 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Time Step Flow Matching for Autonomous Driving Motion Planning
Feb 14, 2026Autonomous driving requires reasoning about interactions with surrounding traffic. A prevailing approach is large-scale imitation learning on expert driving datasets, aimed at generalizing across diverse real-world scenarios. For online trajectory generation, such methods must operate at real-time rates. Diffusion models require hundreds of denoising steps at inference, resulting in high latency. Consistency models mitigate this issue but rely on carefully tuned noise schedules to capture the multimodal action distributions common in autonomous driving. Adapting the schedule, typically requires expensive retraining. To address these limitations, we propose a framework based on conditional flow matching that jointly predicts future motions of surrounding agents and plans the ego trajectory in real time. We train a lightweight variance estimator that selects the number of inference steps online, removing the need for retraining to balance runtime and imitation learning performance. To further enhance ride quality, we introduce a trajectory post-processing step cast as a convex quadratic program, with negligible computational overhead. Trained on the Waymo Open Motion Dataset, the framework performs maneuvers such as lane changes, cruise control, and navigating unprotected left turns without requiring scenario-specific tuning. Our method maintains a 20 Hz update rate on an NVIDIA RTX 3070 GPU, making it suitable for online deployment. Compared to transformer, diffusion, and consistency model baselines, we achieve improved trajectory smoothness and better adherence to dynamic constraints. Experiment videos and code implementations can be found at https://flow-matching-self-driving.github.io/.
Enhancing Robot Safety via MLLM-Based Semantic Interpretation of Failure Data
Jun 06, 2025As robotic systems become increasingly integrated into real-world environments, ranging from autonomous vehicles to household assistants, they inevitably encounter diverse and unstructured scenarios that lead to failures. While such failures pose safety and reliability challenges, they also provide rich perceptual data for improving future performance. However, manually analyzing large-scale failure datasets is impractical. In this work, we present a method for automatically organizing large-scale robotic failure data into semantically meaningful clusters, enabling scalable learning from failure without human supervision. Our approach leverages the reasoning capabilities of Multimodal Large Language Models (MLLMs), trained on internet-scale data, to infer high-level failure causes from raw perceptual trajectories and discover interpretable structure within uncurated failure logs. These semantic clusters reveal latent patterns and hypothesized causes of failure, enabling scalable learning from experience. We demonstrate that the discovered failure modes can guide targeted data collection for policy refinement, accelerating iterative improvement in agent policies and overall safety. Additionally, we show that these semantic clusters can be employed for online failure detection, offering a lightweight yet powerful safeguard for real-time adaptation. We demonstrate that this framework enhances robot learning and robustness by transforming real-world failures into actionable and interpretable signals for adaptation.
DualGuard MPPI: Safe and Performant Optimal Control by Combining Sampling-Based MPC and Hamilton-Jacobi Reachability
Feb 04, 2025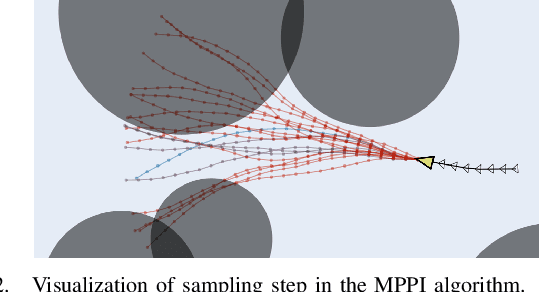
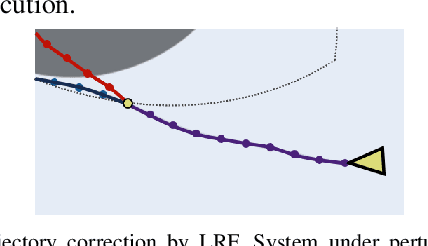
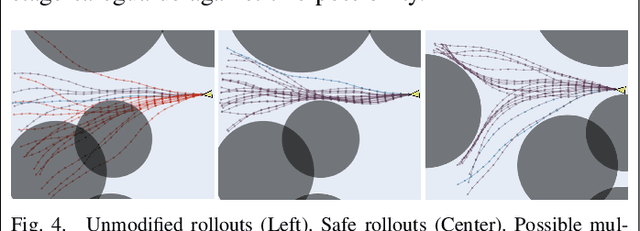
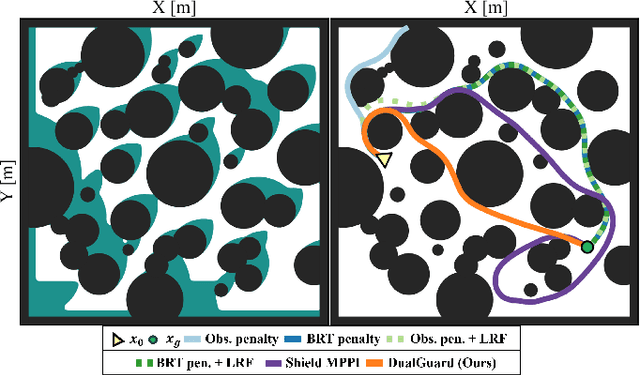
Designing controllers that are both safe and performant is inherently challenging. This co-optimization can be formulated as a constrained optimal control problem, where the cost function represents the performance criterion and safety is specified as a constraint. While sampling-based methods, such as Model Predictive Path Integral (MPPI) control, have shown great promise in tackling complex optimal control problems, they often struggle to enforce safety constraints. To address this limitation, we propose DualGuard-MPPI, a novel framework for solving safety-constrained optimal control problems. Our approach integrates Hamilton-Jacobi reachability analysis within the MPPI sampling process to ensure that all generated samples are provably safe for the system. On the one hand, this integration allows DualGuard-MPPI to enforce strict safety constraints; at the same time, it facilitates a more effective exploration of the environment with the same number of samples, reducing the effective sampling variance and leading to better performance optimization. Through several simulations and hardware experiments, we demonstrate that the proposed approach achieves much higher performance compared to existing MPPI methods, without compromising safety.
Stable-BC: Controlling Covariate Shift with Stable Behavior Cloning
Aug 12, 2024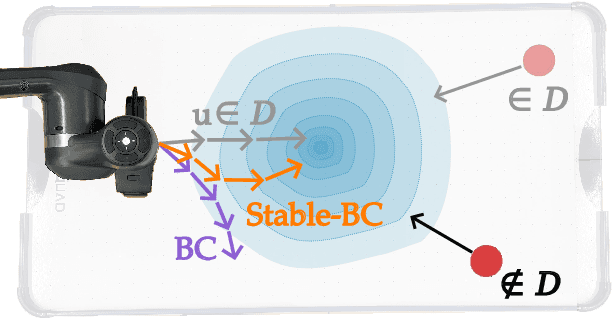
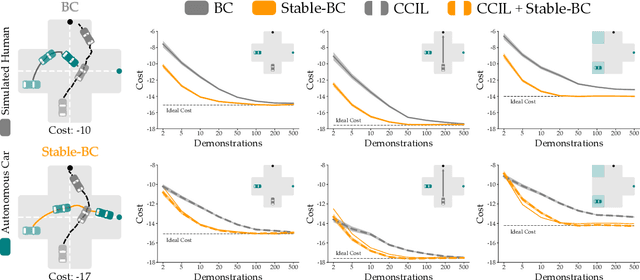
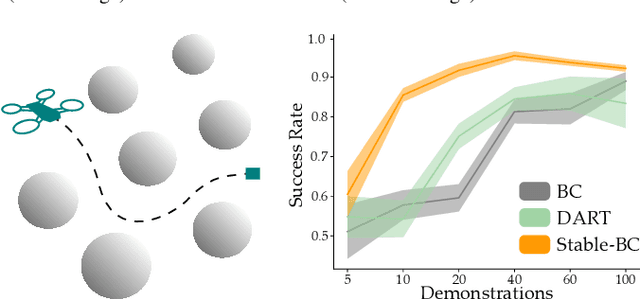
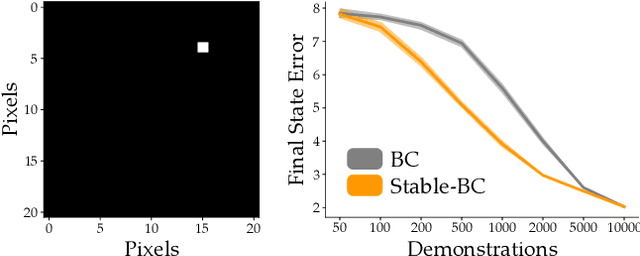
Behavior cloning is a common imitation learning paradigm. Under behavior cloning the robot collects expert demonstrations, and then trains a policy to match the actions taken by the expert. This works well when the robot learner visits states where the expert has already demonstrated the correct action; but inevitably the robot will also encounter new states outside of its training dataset. If the robot learner takes the wrong action at these new states it could move farther from the training data, which in turn leads to increasingly incorrect actions and compounding errors. Existing works try to address this fundamental challenge by augmenting or enhancing the training data. By contrast, in our paper we develop the control theoretic properties of behavior cloned policies. Specifically, we consider the error dynamics between the system's current state and the states in the expert dataset. From the error dynamics we derive model-based and model-free conditions for stability: under these conditions the robot shapes its policy so that its current behavior converges towards example behaviors in the expert dataset. In practice, this results in Stable-BC, an easy to implement extension of standard behavior cloning that is provably robust to covariate shift. We demonstrate the effectiveness of our algorithm in simulations with interactive, nonlinear, and visual environments. We also conduct experiments where a robot arm uses Stable-BC to play air hockey. See our website here: https://collab.me.vt.edu/Stable-BC/
Do LLMs Recognize me, When I is not me: Assessment of LLMs Understanding of Turkish Indexical Pronouns in Indexical Shift Contexts
Jun 08, 2024



Large language models (LLMs) have shown impressive capabilities in tasks such as machine translation, text summarization, question answering, and solving complex mathematical problems. However, their primary training on data-rich languages like English limits their performance in low-resource languages. This study addresses this gap by focusing on the Indexical Shift problem in Turkish. The Indexical Shift problem involves resolving pronouns in indexical shift contexts, a grammatical challenge not present in high-resource languages like English. We present the first study examining indexical shift in any language, releasing a Turkish dataset specifically designed for this purpose. Our Indexical Shift Dataset consists of 156 multiple-choice questions, each annotated with necessary linguistic details, to evaluate LLMs in a few-shot setting. We evaluate recent multilingual LLMs, including GPT-4, GPT-3.5, Cohere-AYA, Trendyol-LLM, and Turkcell-LLM, using this dataset. Our analysis reveals that even advanced models like GPT-4 struggle with the grammatical nuances of indexical shift in Turkish, achieving only moderate performance. These findings underscore the need for focused research on the grammatical challenges posed by low-resource languages. We released the dataset and code \href{https://anonymous.4open.science/r/indexical_shift_llm-E1B4} {here}.
SAFE-GIL: SAFEty Guided Imitation Learning
Apr 08, 2024Behavior Cloning is a popular approach to Imitation Learning, in which a robot observes an expert supervisor and learns a control policy. However, behavior cloning suffers from the "compounding error" problem - the policy errors compound as it deviates from the expert demonstrations and might lead to catastrophic system failures, limiting its use in safety-critical applications. On-policy data aggregation methods are able to address this issue at the cost of rolling out and repeated training of the imitation policy, which can be tedious and computationally prohibitive. We propose SAFE-GIL, an off-policy behavior cloning method that guides the expert via adversarial disturbance during data collection. The algorithm abstracts the imitation error as an adversarial disturbance in the system dynamics, injects it during data collection to expose the expert to safety critical states, and collects corrective actions. Our method biases training to more closely replicate expert behavior in safety-critical states and allows more variance in less critical states. We compare our method with several behavior cloning techniques and DAgger on autonomous navigation and autonomous taxiing tasks and show higher task success and safety, especially in low data regimes where the likelihood of error is higher, at a slight drop in the performance.