 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Robot Safety via MLLM-Based Semantic Interpretation of Failure Data
Jun 06, 2025As robotic systems become increasingly integrated into real-world environments, ranging from autonomous vehicles to household assistants, they inevitably encounter diverse and unstructured scenarios that lead to failures. While such failures pose safety and reliability challenges, they also provide rich perceptual data for improving future performance. However, manually analyzing large-scale failure datasets is impractical. In this work, we present a method for automatically organizing large-scale robotic failure data into semantically meaningful clusters, enabling scalable learning from failure without human supervision. Our approach leverages the reasoning capabilities of Multimodal Large Language Models (MLLMs), trained on internet-scale data, to infer high-level failure causes from raw perceptual trajectories and discover interpretable structure within uncurated failure logs. These semantic clusters reveal latent patterns and hypothesized causes of failure, enabling scalable learning from experience. We demonstrate that the discovered failure modes can guide targeted data collection for policy refinement, accelerating iterative improvement in agent policies and overall safety. Additionally, we show that these semantic clusters can be employed for online failure detection, offering a lightweight yet powerful safeguard for real-time adaptation. We demonstrate that this framework enhances robot learning and robustness by transforming real-world failures into actionable and interpretable signals for adaptation.
TLDR: Traffic Light Detection using Fourier Domain Adaptation in Hostile WeatheR
Nov 12, 2024

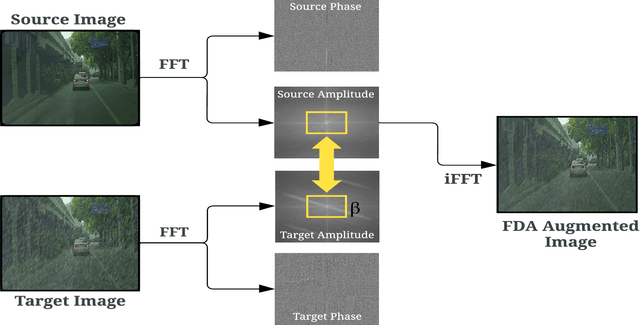

The scarcity of comprehensive datasets in the traffic light detection and recognition domain and the poor performance of state-of-the-art models under hostile weather conditions present significant challenges. To address these issues, this paper proposes a novel approach by merging two widely used datasets, LISA and S2TLD. The merged dataset is further processed to tackle class imbalance, a common problem in this domain. This merged dataset becomes our source domain. Synthetic rain and fog are added to the dataset to create our target domain. We employ Fourier Domain Adaptation (FDA) to create a final dataset with a minimized domain gap between the two datasets, helping the model trained on this final dataset adapt to rainy and foggy weather conditions. Additionally, we explore Semi-Supervised Learning (SSL) techniques to leverage the available data more effectively. Experimental results demonstrate that models trained on FDA-augmented images outperform those trained without FDA across confidence-dependent and independent metrics, like mAP50, mAP50-95, Precision, and Recall. The best-performing model, YOLOv8, achieved a Precision increase of 5.1860%, Recall increase of 14.8009%, mAP50 increase of 9.5074%, and mAP50-95 increase of 19.5035%. On average, percentage increases of 7.6892% in Precision, 19.9069% in Recall, 15.8506% in mAP50, and 23.8099% in mAP50-95 were observed across all models, highlighting the effectiveness of FDA in mitigating the impact of adverse weather conditions on model performance. These improvements pave the way for real-world applications where reliable performance in challenging environmental conditions is critical.
Enhancing Safety and Robustness of Vision-Based Controllers via Reachability Analysis
Oct 29, 2024
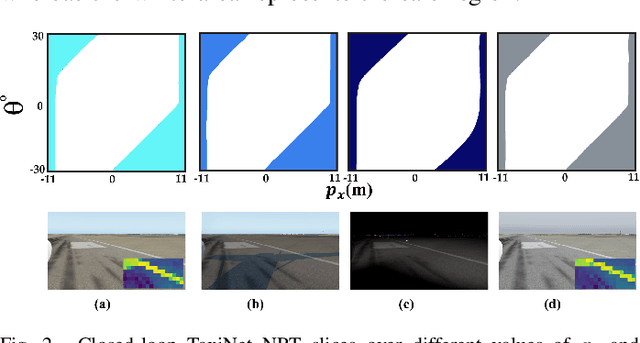
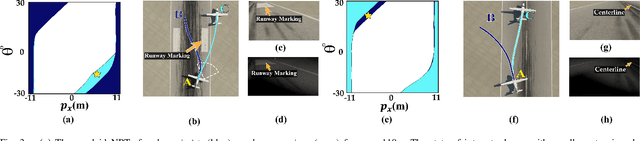
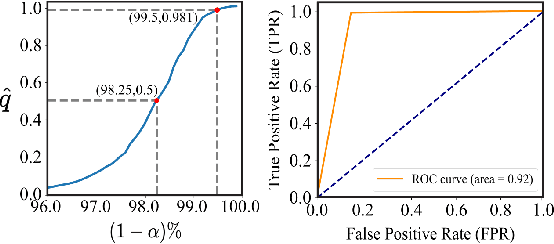
Autonomous systems, such as self-driving cars and drones, have made significant strides in recent years by leveraging visual inputs and machine learning for decision-making and control. Despite their impressive performance, these vision-based controllers can make erroneous predictions when faced with novel or out-of-distribution inputs. Such errors can cascade into catastrophic system failures and compromise system safety. In this work, we compute Neural Reachable Tubes, which act as parameterized approximations of Backward Reachable Tubes to stress-test the vision-based controllers and mine their failure modes. The identified failures are then used to enhance the system safety through both offline and online methods. The online approach involves training a classifier as a run-time failure monitor to detect closed-loop, system-level failures, subsequently triggering a fallback controller that robustly handles these detected failures to preserve system safety. For the offline approach, we improve the original controller via incremental training using a carefully augmented failure dataset, resulting in a more robust controller that is resistant to the known failure modes. In either approach, the system is safeguarded against shortcomings that transcend the vision-based controller and pertain to the closed-loop safety of the overall system. We validate the proposed approaches on an autonomous aircraft taxiing task that involves using a vision-based controller to guide the aircraft towards the centerline of the runway. Our results show the efficacy of the proposed algorithms in identifying and handling system-level failures, outperforming methods that rely on controller prediction error or uncertainty quantification for identifying system failures.
Deep Reinforcement Learning for Sim-to-Real Policy Transfer of VTOL-UAVs Offshore Docking Operations
Jun 02, 2024This paper proposes a novel Reinforcement Learning (RL) approach for sim-to-real policy transfer of Vertical Take-Off and Landing Unmanned Aerial Vehicle (VTOL-UAV). The proposed approach is designed for VTOL-UAV landing on offshore docking stations in maritime operations. VTOL-UAVs in maritime operations encounter limitations in their operational range, primarily stemming from constraints imposed by their battery capacity. The concept of autonomous landing on a charging platform presents an intriguing prospect for mitigating these limitations by facilitating battery charging and data transfer. However, current Deep Reinforcement Learning (DRL) methods exhibit drawbacks, including lengthy training times, and modest success rates. In this paper, we tackle these concerns comprehensively by decomposing the landing procedure into a sequence of more manageable but analogous tasks in terms of an approach phase and a landing phase. The proposed architecture utilizes a model-based control scheme for the approach phase, where the VTOL-UAV is approaching the offshore docking station. In the Landing phase, DRL agents were trained offline to learn the optimal policy to dock on the offshore station. The Joint North Sea Wave Project (JONSWAP) spectrum model has been employed to create a wave model for each episode, enhancing policy generalization for sim2real transfer. A set of DRL algorithms have been tested through numerical simulations including value-based agents and policy-based agents such as Deep \textit{Q} Networks (DQN) and Proximal Policy Optimization (PPO) respectively. The numerical experiments show that the PPO agent can learn complicated and efficient policies to land in uncertain environments, which in turn enhances the likelihood of successful sim-to-real transfer.
Detecting and Mitigating System-Level Anomalies of Vision-Based Controllers
Sep 23, 2023



Autonomous systems, such as self-driving cars and drones, have made significant strides in recent years by leveraging visual inputs and machine learning for decision-making and control. Despite their impressive performance, these vision-based controllers can make erroneous predictions when faced with novel or out-of-distribution inputs. Such errors can cascade to catastrophic system failures and compromise system safety. In this work, we introduce a run-time anomaly monitor to detect and mitigate such closed-loop, system-level failures. Specifically, we leverage a reachability-based framework to stress-test the vision-based controller offline and mine its system-level failures. This data is then used to train a classifier that is leveraged online to flag inputs that might cause system breakdowns. The anomaly detector highlights issues that transcend individual modules and pertain to the safety of the overall system. We also design a fallback controller that robustly handles these detected anomalies to preserve system safety. We validate the proposed approach on an autonomous aircraft taxiing system that uses a vision-based controller for taxiing. Our results show the efficacy of the proposed approach in identifying and handling system-level anomalies, outperforming methods such as prediction error-based detection, and ensembling, thereby enhancing the overall safety and robustness of autonomous systems.
Nose, eyes and ears: Head pose estimation by locating facial keypoints
Dec 03, 2018


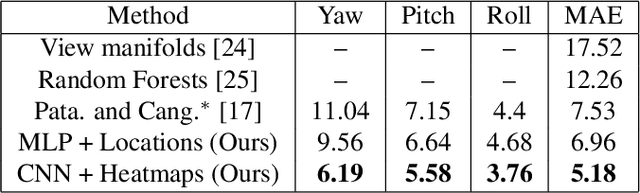
Monocular head pose estimation requires learning a model that computes the intrinsic Euler angles for pose (yaw, pitch, roll) from an input image of human face. Annotating ground truth head pose angles for images in the wild is difficult and requires ad-hoc fitting procedures (which provides only coarse and approximate annotations). This highlights the need for approaches which can train on data captured in controlled environment and generalize on the images in the wild (with varying appearance and illumination of the face). Most present day deep learning approaches which learn a regression function directly on the input images fail to do so. To this end, we propose to use a higher level representation to regress the head pose while using deep learning architectures. More specifically, we use the uncertainty maps in the form of 2D soft localization heatmap images over five facial keypoints, namely left ear, right ear, left eye, right eye and nose, and pass them through an convolutional neural network to regress the head-pose. We show head pose estimation results on two challenging benchmarks BIWI and AFLW and our approach surpasses the state of the art on both the datasets.