 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRinGS: Selective Text Refinement in Gaussian Splatting
Dec 08, 2025Text as signs, labels, or instructions is a critical element of real-world scenes as they can convey important contextual information. 3D representations such as 3D Gaussian Splatting (3DGS) struggle to preserve fine-grained text details, while achieving high visual fidelity. Small errors in textual element reconstruction can lead to significant semantic loss. We propose STRinGS, a text-aware, selective refinement framework to address this issue for 3DGS reconstruction. Our method treats text and non-text regions separately, refining text regions first and merging them with non-text regions later for full-scene optimization. STRinGS produces sharp, readable text even in challenging configurations. We introduce a text readability measure OCR Character Error Rate (CER) to evaluate the efficacy on text regions. STRinGS results in a 63.6% relative improvement over 3DGS at just 7K iterations. We also introduce a curated dataset STRinGS-360 with diverse text scenarios to evaluate text readability in 3D reconstruction. Our method and dataset together push the boundaries of 3D scene understanding in text-rich environments, paving the way for more robust text-aware reconstruction methods.
Specularity Factorization for Low-Light Enhancement
Apr 02, 2024We present a new additive image factorization technique that treats images to be composed of multiple latent specular components which can be simply estimated recursively by modulating the sparsity during decomposition. Our model-driven {\em RSFNet} estimates these factors by unrolling the optimization into network layers requiring only a few scalars to be learned. The resultant factors are interpretable by design and can be fused for different image enhancement tasks via a network or combined directly by the user in a controllable fashion. Based on RSFNet, we detail a zero-reference Low Light Enhancement (LLE) application trained without paired or unpaired supervision. Our system improves the state-of-the-art performance on standard benchmarks and achieves better generalization on multiple other datasets. We also integrate our factors with other task specific fusion networks for applications like deraining, deblurring and dehazing with negligible overhead thereby highlighting the multi-domain and multi-task generalizability of our proposed RSFNet. The code and data is released for reproducibility on the project homepage.
A survey on Concept-based Approaches For Model Improvement
Mar 23, 2024The focus of recent research has shifted from merely improving the metrics based performance of Deep Neural Networks (DNNs) to DNNs which are more interpretable to humans. The field of eXplainable Artificial Intelligence (XAI) has observed various techniques, including saliency-based and concept-based approaches. These approaches explain the model's decisions in simple human understandable terms called Concepts. Concepts are known to be the thinking ground of humans}. Explanations in terms of concepts enable detecting spurious correlations, inherent biases, or clever-hans. With the advent of concept-based explanations, a range of concept representation methods and automatic concept discovery algorithms have been introduced. Some recent works also use concepts for model improvement in terms of interpretability and generalization. We provide a systematic review and taxonomy of various concept representations and their discovery algorithms in DNNs, specifically in vision. We also provide details on concept-based model improvement literature marking the first comprehensive survey of these methods.
Concept Distillation: Leveraging Human-Centered Explanations for Model Improvement
Nov 26, 2023



Humans use abstract concepts for understanding instead of hard features. Recent interpretability research has focused on human-centered concept explanations of neural networks. Concept Activation Vectors (CAVs) estimate a model's sensitivity and possible biases to a given concept. In this paper, we extend CAVs from post-hoc analysis to ante-hoc training in order to reduce model bias through fine-tuning using an additional Concept Loss. Concepts were defined on the final layer of the network in the past. We generalize it to intermediate layers using class prototypes. This facilitates class learning in the last convolution layer, which is known to be most informative. We also introduce Concept Distillation to create richer concepts using a pre-trained knowledgeable model as the teacher. Our method can sensitize or desensitize a model towards concepts. We show applications of concept-sensitive training to debias several classification problems. We also use concepts to induce prior knowledge into IID, a reconstruction problem. Concept-sensitive training can improve model interpretability, reduce biases, and induce prior knowledge. Please visit https://avani17101.github.io/Concept-Distilllation/ for code and more details.
Nose, eyes and ears: Head pose estimation by locating facial keypoints
Dec 03, 2018


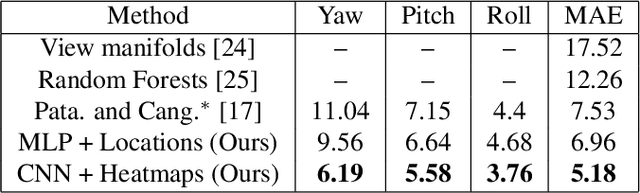
Monocular head pose estimation requires learning a model that computes the intrinsic Euler angles for pose (yaw, pitch, roll) from an input image of human face. Annotating ground truth head pose angles for images in the wild is difficult and requires ad-hoc fitting procedures (which provides only coarse and approximate annotations). This highlights the need for approaches which can train on data captured in controlled environment and generalize on the images in the wild (with varying appearance and illumination of the face). Most present day deep learning approaches which learn a regression function directly on the input images fail to do so. To this end, we propose to use a higher level representation to regress the head pose while using deep learning architectures. More specifically, we use the uncertainty maps in the form of 2D soft localization heatmap images over five facial keypoints, namely left ear, right ear, left eye, right eye and nose, and pass them through an convolutional neural network to regress the head-pose. We show head pose estimation results on two challenging benchmarks BIWI and AFLW and our approach surpasses the state of the art on both the datasets.
Part-based Graph Convolutional Network for Action Recognition
Sep 13, 2018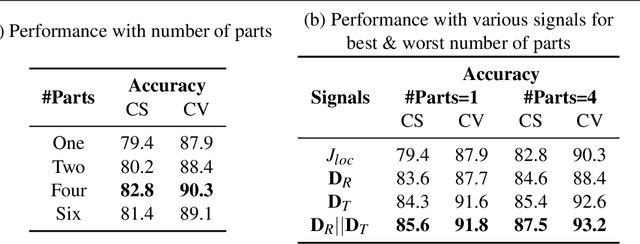

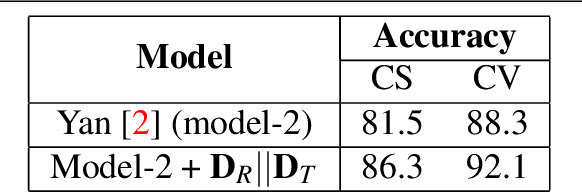
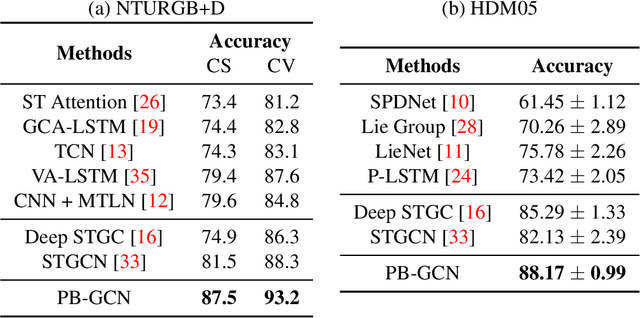
Human actions comprise of joint motion of articulated body parts or `gestures'. Human skeleton is intuitively represented as a sparse graph with joints as nodes and natural connections between them as edges. Graph convolutional networks have been used to recognize actions from skeletal videos. We introduce a part-based graph convolutional network (PB-GCN) for this task, inspired by Deformable Part-based Models (DPMs). We divide the skeleton graph into four subgraphs with joints shared across them and learn a recognition model using a part-based graph convolutional network. We show that such a model improves performance of recognition, compared to a model using entire skeleton graph. Instead of using 3D joint coordinates as node features, we show that using relative coordinates and temporal displacements boosts performance. Our model achieves state-of-the-art performance on two challenging benchmark datasets NTURGB+D and HDM05, for skeletal action recognition.
A Unified View-Graph Selection Framework for Structure from Motion
Dec 04, 2017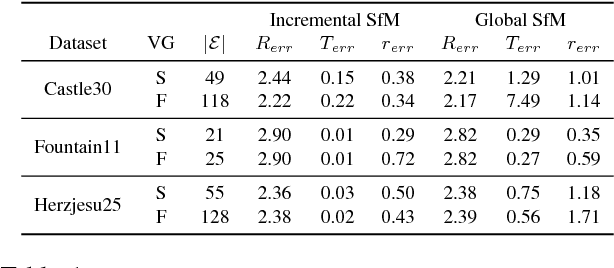

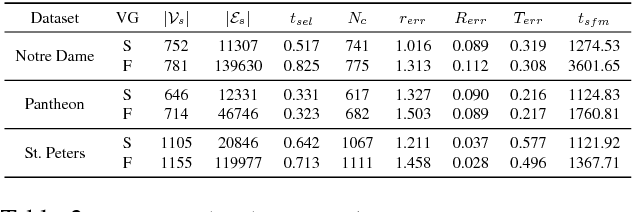
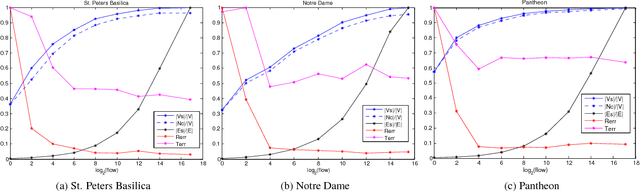
View-graph is an essential input to large-scale structure from motion (SfM) pipelines. Accuracy and efficiency of large-scale SfM is crucially dependent on the input view-graph. Inconsistent or inaccurate edges can lead to inferior or wrong reconstruction. Most SfM methods remove `undesirable' images and pairs using several, fixed heuristic criteria, and propose tailor-made solutions to achieve specific reconstruction objectives such as efficiency, accuracy, or disambiguation. In contrast to these disparate solutions, we propose a single optimization framework that can be used to achieve these different reconstruction objectives with task-specific cost modeling. We also construct a very efficient network-flow based formulation for its approximate solution. The abstraction brought on by this selection mechanism separates the challenges specific to datasets and reconstruction objectives from the standard SfM pipeline and improves its generalization. This paper demonstrates the application of the proposed view-graph framework with standard SfM pipeline for two particular use-cases, (i) accurate and ghost-free reconstructions of highly ambiguous datasets using costs based on disambiguation priors, and (ii) accurate and efficient reconstruction of large-scale Internet datasets using costs based on commonly used priors.
From Traditional to Modern : Domain Adaptation for Action Classification in Short Social Video Clips
Oct 18, 2016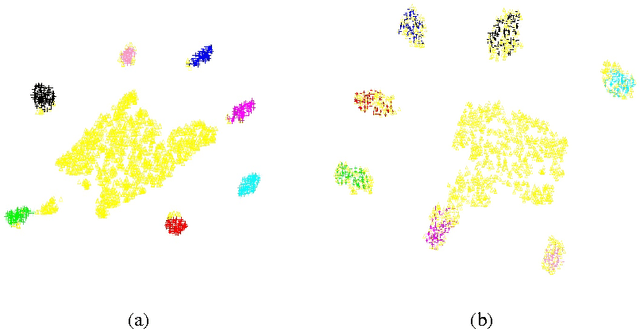


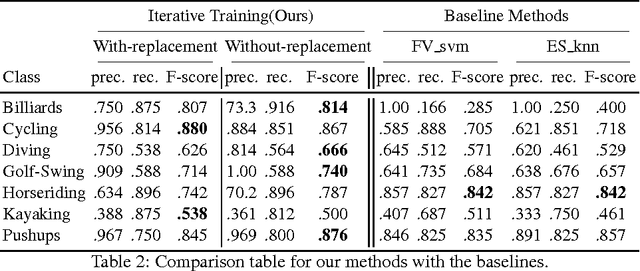
Short internet video clips like vines present a significantly wild distribution compared to traditional video datasets. In this paper, we focus on the problem of unsupervised action classification in wild vines using traditional labeled datasets. To this end, we use a data augmentation based simple domain adaptation strategy. We utilise semantic word2vec space as a common subspace to embed video features from both, labeled source domain and unlablled target domain. Our method incrementally augments the labeled source with target samples and iteratively modifies the embedding function to bring the source and target distributions together. Additionally, we utilise a multi-modal representation that incorporates noisy semantic information available in form of hash-tags. We show the effectiveness of this simple adaptation technique on a test set of vines and achieve notable improvements in performance.
* 9 pages, GCPR, 2016
Multistage SFM: A Coarse-to-Fine Approach for 3D Reconstruction
Oct 12, 2016

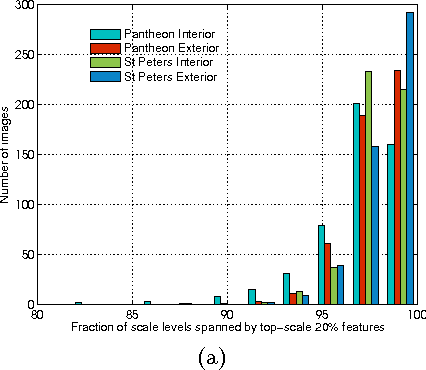
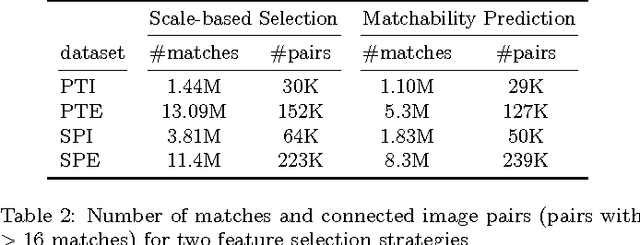
Several methods have been proposed for large-scale 3D reconstruction from large, unorganized image collections. A large reconstruction problem is typically divided into multiple components which are reconstructed independently using structure from motion (SFM) and later merged together. Incremental SFM methods are most popular for the basic structure recovery of a single component. They are robust and effective but are strictly sequential in nature. We present a multistage approach for SFM reconstruction of a single component that breaks the sequential nature of the incremental SFM methods. Our approach begins with quickly building a coarse 3D model using only a fraction of features from given images. The coarse model is then enriched by localizing remaining images and matching and triangulating remaining features in subsequent stages. These stages are made efficient and highly parallel by leveraging the geometry of the coarse model. Our method produces similar quality models as compared to incremental SFM methods while being notably fast and parallel.