 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVEN: Multitask Retrieval Augmented Vision-Language Learning
Jun 27, 2024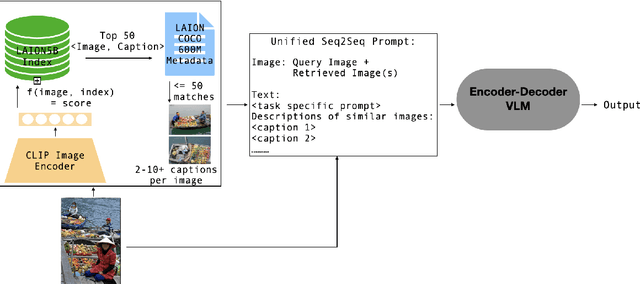
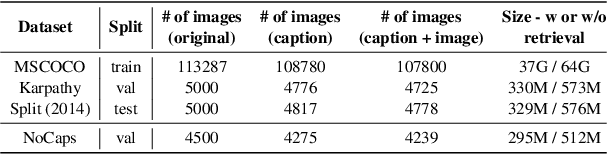
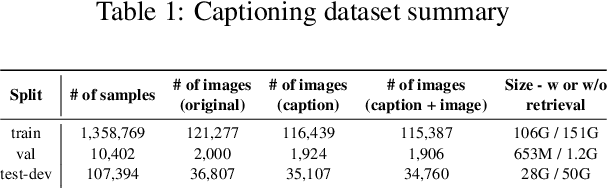

The scaling of large language models to encode all the world's knowledge in model parameters is unsustainable and has exacerbated resource barriers. Retrieval-Augmented Generation (RAG) presents a potential solution, yet its application to vision-language models (VLMs) is under explored. Existing methods focus on models designed for single tasks. Furthermore, they're limited by the need for resource intensive pre training, additional parameter requirements, unaddressed modality prioritization and lack of clear benefit over non-retrieval baselines. This paper introduces RAVEN, a multitask retrieval augmented VLM framework that enhances base VLMs through efficient, task specific fine-tuning. By integrating retrieval augmented samples without the need for additional retrieval-specific parameters, we show that the model acquires retrieval properties that are effective across multiple tasks. Our results and extensive ablations across retrieved modalities for the image captioning and VQA tasks indicate significant performance improvements compared to non retrieved baselines +1 CIDEr on MSCOCO, +4 CIDEr on NoCaps and nearly a +3\% accuracy on specific VQA question types. This underscores the efficacy of applying RAG approaches to VLMs, marking a stride toward more efficient and accessible multimodal learning.
Motion Classification Based on Harmonic Micro-Doppler Signatures Using a Convolutional Neural Network
Jan 13, 2023



We demonstrate the classification of common motions of held objects using the harmonic micro-Doppler signatures scattered from harmonic radio-frequency tags. Harmonic tags capture incident signals and retransmit at harmonic frequencies, making them easier to distinguish from clutter. We characterize the motion of tagged handheld objects via the time-varying frequency shift of the harmonic signals (harmonic Doppler). With complex micromotions of held objects, the time-frequency response manifests complex micro-Doppler signatures that can be used to classify the motions. We developed narrow-band harmonic tags at 2.4/4.8 GHz that support frequency scalability for multi-tag operation, and a harmonic radar system to transmit a 2.4 GHz continuous-wave signal and receive the scattered 4.8 GHz harmonic signal. Experiments were conducted to mimic four common motions of held objects from 35 subjects in a cluttered indoor environment. A 7-layer convolutional neural network (CNN) multi-label classifier was developed and obtained a real time classification accuracy of 94.24%, with a response time of 2 seconds per sample with a data processing latency of less than 0.5 seconds.
A linearized framework and a new benchmark for model selection for fine-tuning
Jan 29, 2021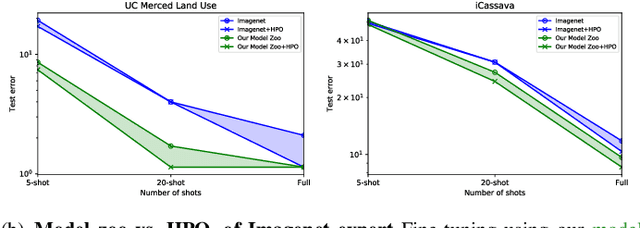

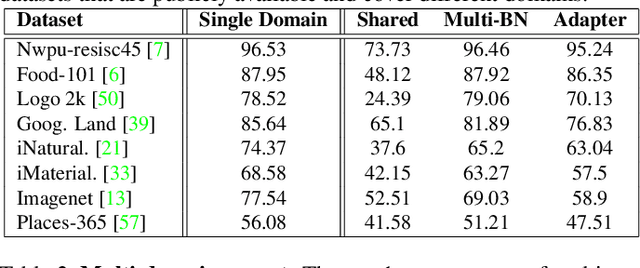
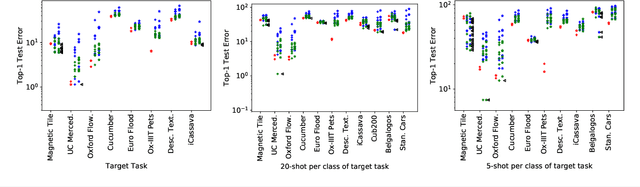
Fine-tuning from a collection of models pre-trained on different domains (a "model zoo") is emerging as a technique to improve test accuracy in the low-data regime. However, model selection, i.e. how to pre-select the right model to fine-tune from a model zoo without performing any training, remains an open topic. We use a linearized framework to approximate fine-tuning, and introduce two new baselines for model selection -- Label-Gradient and Label-Feature Correlation. Since all model selection algorithms in the literature have been tested on different use-cases and never compared directly, we introduce a new comprehensive benchmark for model selection comprising of: i) A model zoo of single and multi-domain models, and ii) Many target tasks. Our benchmark highlights accuracy gain with model zoo compared to fine-tuning Imagenet models. We show our model selection baseline can select optimal models to fine-tune in few selections and has the highest ranking correlation to fine-tuning accuracy compared to existing algorithms.
Diverse and Controllable Image Captioning with Part-of-Speech Guidance
May 31, 2018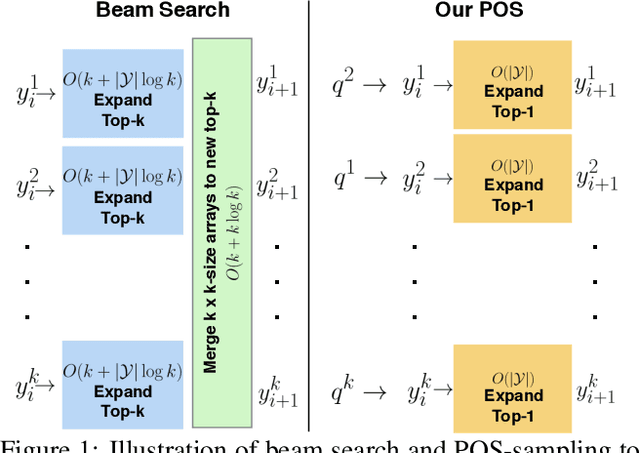
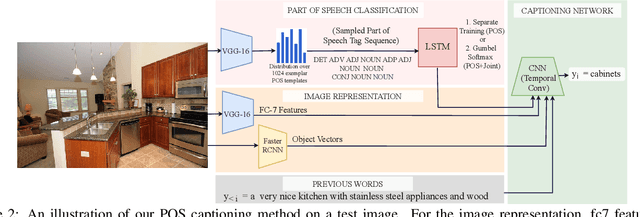
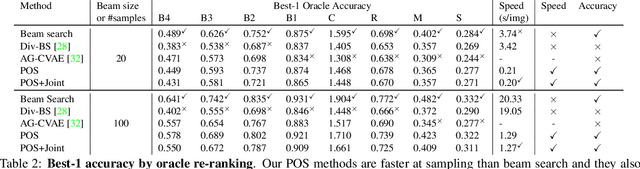
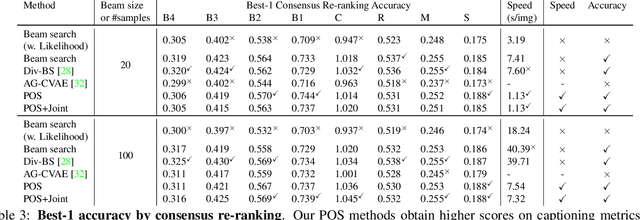
Automatically describing an image is an important capability for virtual assistants. Significant progress has been achieved in recent years on this task of image captioning. However, classical prediction techniques based on maximum likelihood trained LSTM nets don't embrace the inherent ambiguity of image captioning. To address this concern, recent variational auto-encoder and generative adversarial network based methods produce a set of captions by sampling from an abstract latent space. But, this latent space has limited interpretability and therefore, a control mechanism for captioning remains an open problem. This paper proposes a captioning technique conditioned on part-of-speech. Our method provides human interpretable control in form of part-of-speech. Importantly, part-of-speech is a language prior, and conditioning on it provides: (i) more diversity as evaluated by counting n-grams and the novel sentences generated, (ii) achieves high accuracy for the diverse captions on standard captioning metrics.
Convolutional Image Captioning
Nov 24, 2017
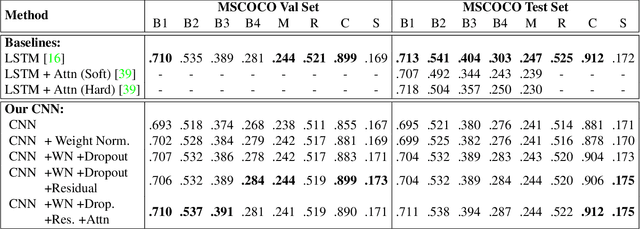
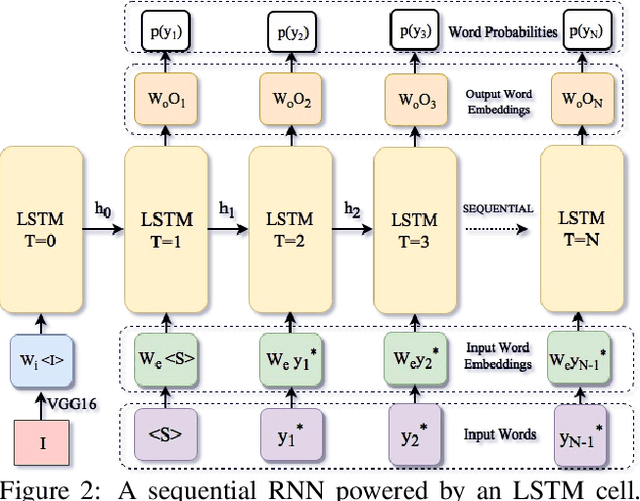

Image captioning is an important but challenging task, applicable to virtual assistants, editing tools, image indexing, and support of the disabled. Its challenges are due to the variability and ambiguity of possible image descriptions. In recent years significant progress has been made in image captioning, using Recurrent Neural Networks powered by long-short-term-memory (LSTM) units. Despite mitigating the vanishing gradient problem, and despite their compelling ability to memorize dependencies, LSTM units are complex and inherently sequential across time. To address this issue, recent work has shown benefits of convolutional networks for machine translation and conditional image generation. Inspired by their success, in this paper, we develop a convolutional image captioning technique. We demonstrate its efficacy on the challenging MSCOCO dataset and demonstrate performance on par with the baseline, while having a faster training time per number of parameters. We also perform a detailed analysis, providing compelling reasons in favor of convolutional language generation approaches.
Learning Diverse Image Colorization
Apr 27, 2017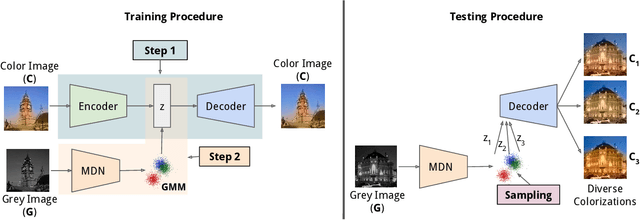

Colorization is an ambiguous problem, with multiple viable colorizations for a single grey-level image. However, previous methods only produce the single most probable colorization. Our goal is to model the diversity intrinsic to the problem of colorization and produce multiple colorizations that display long-scale spatial co-ordination. We learn a low dimensional embedding of color fields using a variational autoencoder (VAE). We construct loss terms for the VAE decoder that avoid blurry outputs and take into account the uneven distribution of pixel colors. Finally, we build a conditional model for the multi-modal distribution between grey-level image and the color field embeddings. Samples from this conditional model result in diverse colorization. We demonstrate that our method obtains better diverse colorizations than a standard conditional variational autoencoder (CVAE) model, as well as a recently proposed conditional generative adversarial network (cGAN).
CDVAE: Co-embedding Deep Variational Auto Encoder for Conditional Variational Generation
Mar 28, 2017
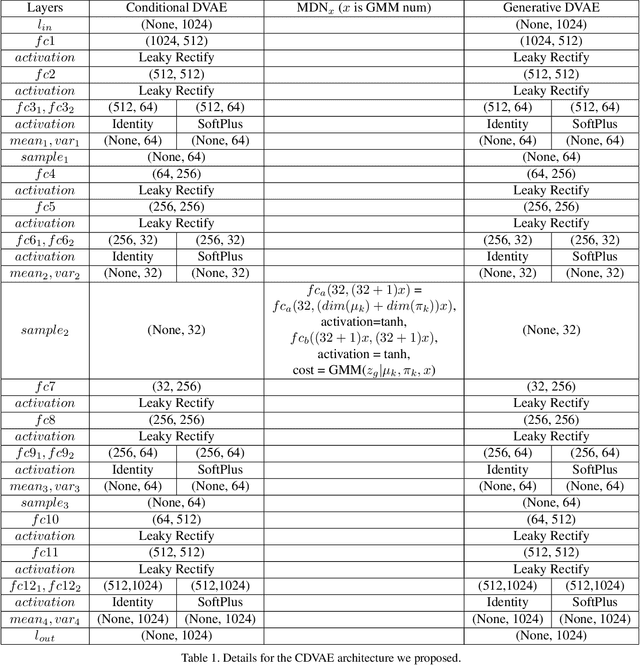
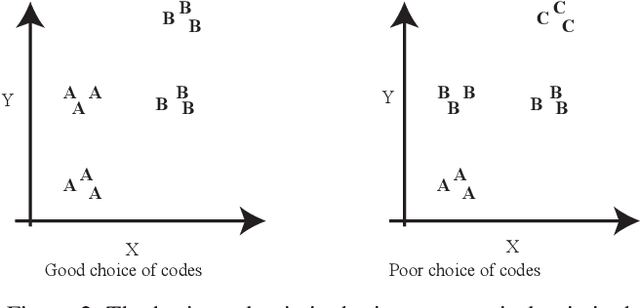
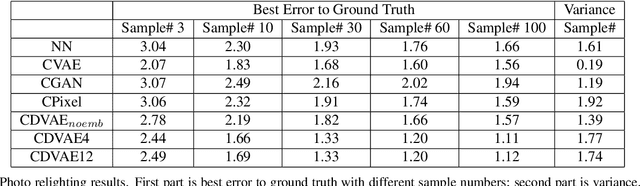
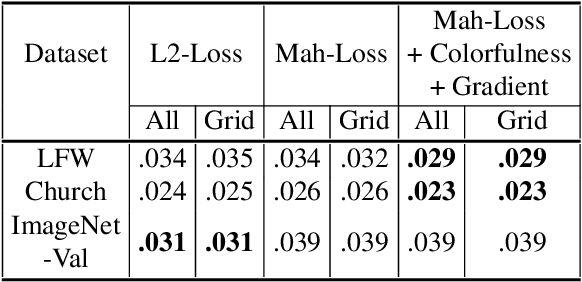
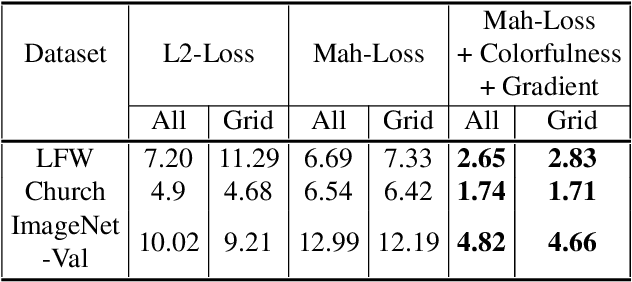
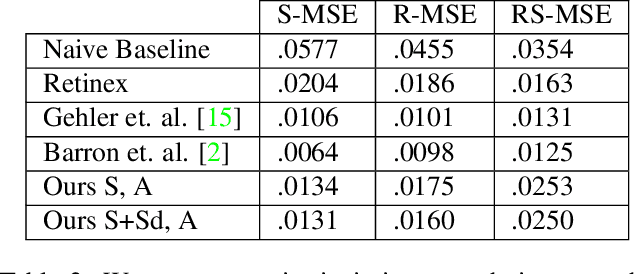
Problems such as predicting a new shading field (Y) for an image (X) are ambiguous: many very distinct solutions are good. Representing this ambiguity requires building a conditional model P(Y|X) of the prediction, conditioned on the image. Such a model is difficult to train, because we do not usually have training data containing many different shadings for the same image. As a result, we need different training examples to share data to produce good models. This presents a danger we call "code space collapse" - the training procedure produces a model that has a very good loss score, but which represents the conditional distribution poorly. We demonstrate an improved method for building conditional models by exploiting a metric constraint on training data that prevents code space collapse. We demonstrate our model on two example tasks using real data: image saturation adjustment, image relighting. We describe quantitative metrics to evaluate ambiguous generation results. Our results quantitatively and qualitatively outperform different strong baselines.
Authoring image decompositions with generative models
Dec 05, 2016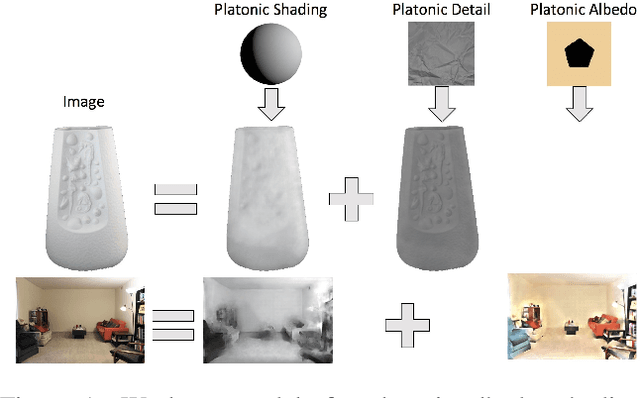
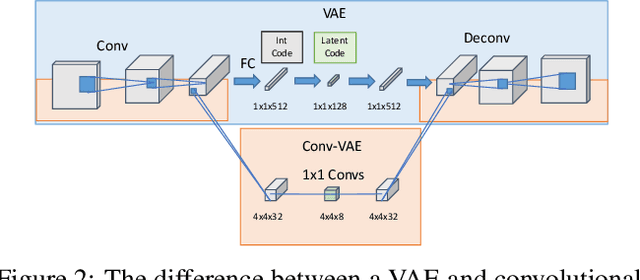
We show how to extend traditional intrinsic image decompositions to incorporate further layers above albedo and shading. It is hard to obtain data to learn a multi-layer decomposition. Instead, we can learn to decompose an image into layers that are "like this" by authoring generative models for each layer using proxy examples that capture the Platonic ideal (Mondrian images for albedo; rendered 3D primitives for shading; material swatches for shading detail). Our method then generates image layers, one from each model, that explain the image. Our approach rests on innovation in generative models for images. We introduce a Convolutional Variational Auto Encoder (conv-VAE), a novel VAE architecture that can reconstruct high fidelity images. The approach is general, and does not require that layers admit a physical interpretation.
Multistage SFM: A Coarse-to-Fine Approach for 3D Reconstruction
Oct 12, 2016

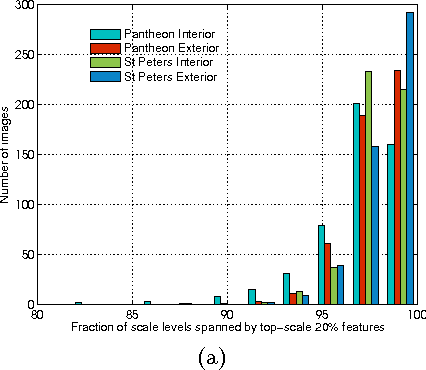
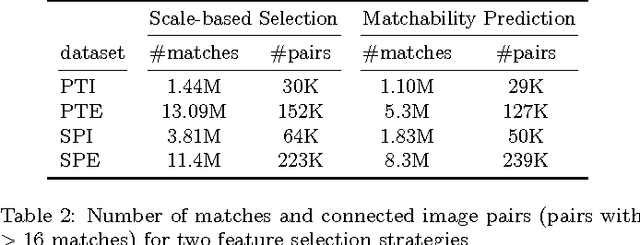
Several methods have been proposed for large-scale 3D reconstruction from large, unorganized image collections. A large reconstruction problem is typically divided into multiple components which are reconstructed independently using structure from motion (SFM) and later merged together. Incremental SFM methods are most popular for the basic structure recovery of a single component. They are robust and effective but are strictly sequential in nature. We present a multistage approach for SFM reconstruction of a single component that breaks the sequential nature of the incremental SFM methods. Our approach begins with quickly building a coarse 3D model using only a fraction of features from given images. The coarse model is then enriched by localizing remaining images and matching and triangulating remaining features in subsequent stages. These stages are made efficient and highly parallel by leveraging the geometry of the coarse model. Our method produces similar quality models as compared to incremental SFM methods while being notably fast and parallel.
Top Down Approach to Multiple Plane Detection
Dec 26, 2013
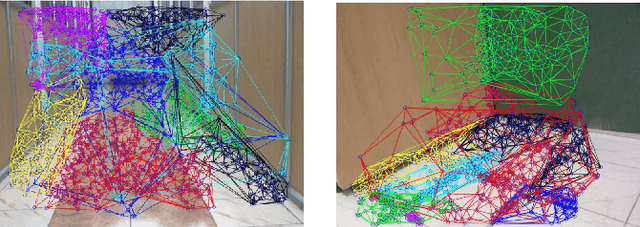

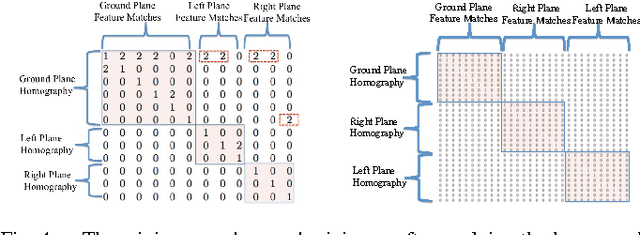
Detecting multiple planes in images is a challenging problem, but one with many applications. Recent work such as J-Linkage and Ordered Residual Kernels have focussed on developing a domain independent approach to detect multiple structures. These multiple structure detection methods are then used for estimating multiple homographies given feature matches between two images. Features participating in the multiple homographies detected, provide us the multiple scene planes. We show that these methods provide locally optimal results and fail to merge detected planar patches to the true scene planes. These methods use only residues obtained on applying homography of one plane to another as cue for merging. In this paper, we develop additional cues such as local consistency of planes, local normals, texture etc. to perform better classification and merging . We formulate the classification as an MRF problem and use TRWS message passing algorithm to solve non metric energy terms and complex sparse graph structure. We show results on challenging dataset common in robotics navigation scenarios where our method shows accuracy of more than 85 percent on average while being close or same as the actual number of scene planes.