 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrion: A Unified Visual Agent for Multimodal Perception, Advanced Visual Reasoning and Execution
Nov 18, 2025We introduce Orion, a visual agent framework that can take in any modality and generate any modality. Using an agentic framework with multiple tool-calling capabilities, Orion is designed for visual AI tasks and achieves state-of-the-art results. Unlike traditional vision-language models that produce descriptive outputs, Orion orchestrates a suite of specialized computer vision tools, including object detection, keypoint localization, panoptic segmentation, Optical Character Recognition, and geometric analysis, to execute complex multi-step visual workflows. The system achieves competitive performance on MMMU, MMBench, DocVQA, and MMLongBench while extending monolithic vision-language models to production-grade visual intelligence. By combining neural perception with symbolic execution, Orion enables autonomous visual reasoning, marking a transition from passive visual understanding to active, tool-driven visual intelligence.
Leveraging Cycle-Consistent Anchor Points for Self-Supervised RGB-D Registration
Oct 16, 2025With the rise in consumer depth cameras, a wealth of unlabeled RGB-D data has become available. This prompts the question of how to utilize this data for geometric reasoning of scenes. While many RGB-D registration meth- ods rely on geometric and feature-based similarity, we take a different approach. We use cycle-consistent keypoints as salient points to enforce spatial coherence constraints during matching, improving correspondence accuracy. Additionally, we introduce a novel pose block that combines a GRU recurrent unit with transformation synchronization, blending historical and multi-view data. Our approach surpasses previous self- supervised registration methods on ScanNet and 3DMatch, even outperforming some older supervised methods. We also integrate our components into existing methods, showing their effectiveness.
* 8 pages, accepted at ICRA 2024 (International Conference on Robotics and Automation)
Reconstructing Animatable Categories from Videos
May 10, 2023



Building animatable 3D models is challenging due to the need for 3D scans, laborious registration, and manual rigging, which are difficult to scale to arbitrary categories. Recently, differentiable rendering provides a pathway to obtain high-quality 3D models from monocular videos, but these are limited to rigid categories or single instances. We present RAC that builds category 3D models from monocular videos while disentangling variations over instances and motion over time. Three key ideas are introduced to solve this problem: (1) specializing a skeleton to instances via optimization, (2) a method for latent space regularization that encourages shared structure across a category while maintaining instance details, and (3) using 3D background models to disentangle objects from the background. We show that 3D models of humans, cats, and dogs can be learned from 50-100 internet videos.
Joint Semantic and Motion Segmentation for dynamic scenes using Deep Convolutional Networks
Apr 18, 2017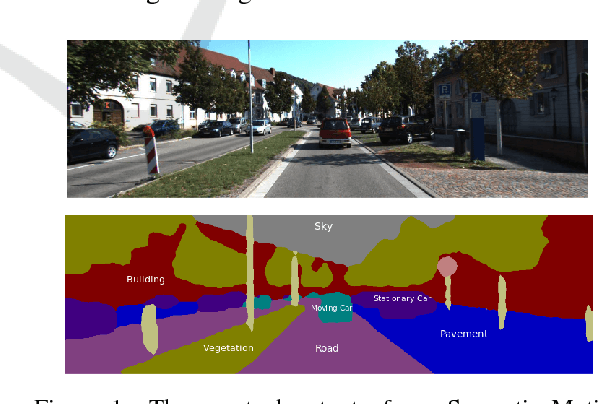



Dynamic scene understanding is a challenging problem and motion segmentation plays a crucial role in solving it. Incorporating semantics and motion enhances the overall perception of the dynamic scene. For applications of outdoor robotic navigation, joint learning methods have not been extensively used for extracting spatio-temporal features or adding different priors into the formulation. The task becomes even more challenging without stereo information being incorporated. This paper proposes an approach to fuse semantic features and motion clues using CNNs, to address the problem of monocular semantic motion segmentation. We deduce semantic and motion labels by integrating optical flow as a constraint with semantic features into dilated convolution network. The pipeline consists of three main stages i.e Feature extraction, Feature amplification and Multi Scale Context Aggregation to fuse the semantics and flow features. Our joint formulation shows significant improvements in monocular motion segmentation over the state of the art methods on challenging KITTI tracking dataset.
Incremental Real-Time Multibody VSLAM with Trajectory Optimization Using Stereo Camera
Aug 02, 2016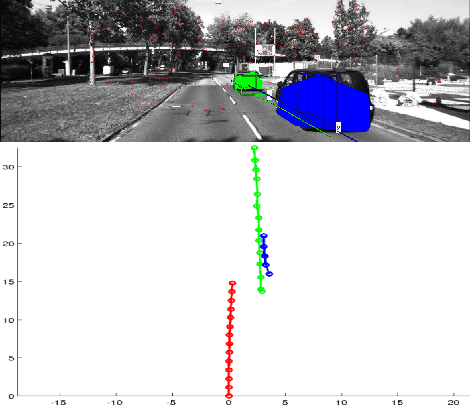
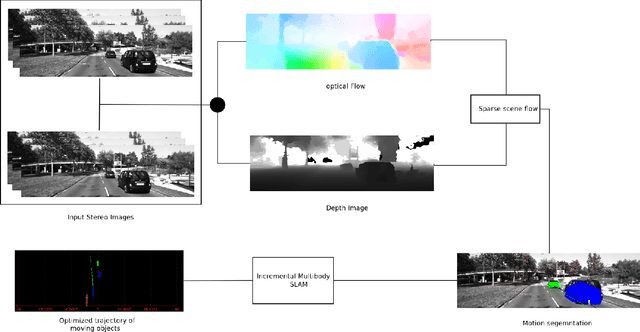
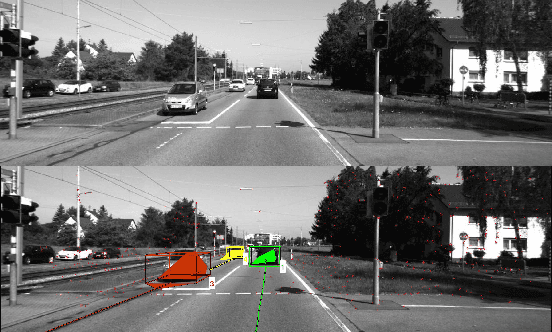
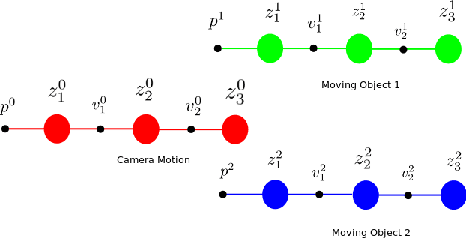
Real time outdoor navigation in highly dynamic environments is an crucial problem. The recent literature on real time static SLAM don't scale up to dynamic outdoor environments. Most of these methods assume moving objects as outliers or discard the information provided by them. We propose an algorithm to jointly infer the camera trajectory and the moving object trajectory simultaneously. In this paper, we perform a sparse scene flow based motion segmentation using a stereo camera. The segmented objects motion models are used for accurate localization of the camera trajectory as well as the moving objects. We exploit the relationship between moving objects for improving the accuracy of the poses. We formulate the poses as a factor graph incorporating all the constraints. We achieve exact incremental solution by solving a full nonlinear optimization problem in real time. The evaluation is performed on the challenging KITTI dataset with multiple moving cars.Our method outperforms the previous baselines in outdoor navigation.
Top Down Approach to Multiple Plane Detection
Dec 26, 2013
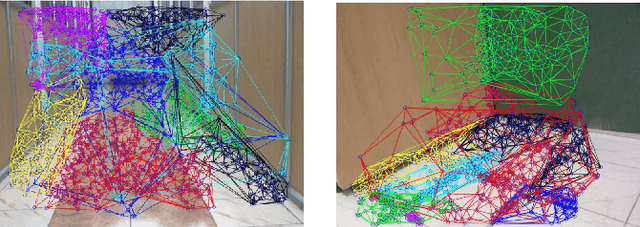

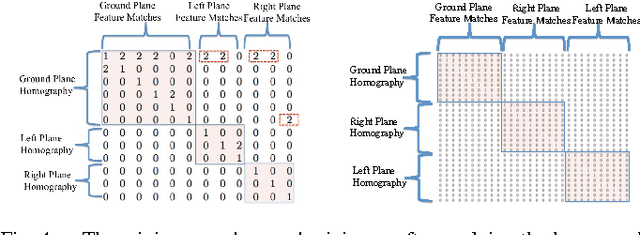
Detecting multiple planes in images is a challenging problem, but one with many applications. Recent work such as J-Linkage and Ordered Residual Kernels have focussed on developing a domain independent approach to detect multiple structures. These multiple structure detection methods are then used for estimating multiple homographies given feature matches between two images. Features participating in the multiple homographies detected, provide us the multiple scene planes. We show that these methods provide locally optimal results and fail to merge detected planar patches to the true scene planes. These methods use only residues obtained on applying homography of one plane to another as cue for merging. In this paper, we develop additional cues such as local consistency of planes, local normals, texture etc. to perform better classification and merging . We formulate the classification as an MRF problem and use TRWS message passing algorithm to solve non metric energy terms and complex sparse graph structure. We show results on challenging dataset common in robotics navigation scenarios where our method shows accuracy of more than 85 percent on average while being close or same as the actual number of scene planes.