 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Semantic and Motion Segmentation for dynamic scenes using Deep Convolutional Networks
Paper and Code
Apr 18, 2017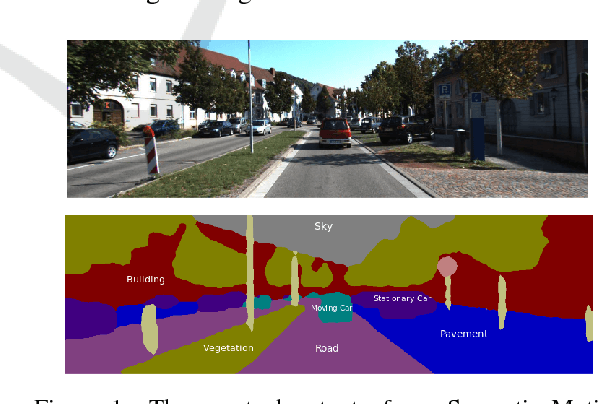



Dynamic scene understanding is a challenging problem and motion segmentation plays a crucial role in solving it. Incorporating semantics and motion enhances the overall perception of the dynamic scene. For applications of outdoor robotic navigation, joint learning methods have not been extensively used for extracting spatio-temporal features or adding different priors into the formulation. The task becomes even more challenging without stereo information being incorporated. This paper proposes an approach to fuse semantic features and motion clues using CNNs, to address the problem of monocular semantic motion segmentation. We deduce semantic and motion labels by integrating optical flow as a constraint with semantic features into dilated convolution network. The pipeline consists of three main stages i.e Feature extraction, Feature amplification and Multi Scale Context Aggregation to fuse the semantics and flow features. Our joint formulation shows significant improvements in monocular motion segmentation over the state of the art methods on challenging KITTI tracking dataset.