 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipate, Adapt, Act: A Hybrid Framework for Task Planning
Feb 23, 2026Anticipating and adapting to failures is a key capability robots need to collaborate effectively with humans in complex domains. This continues to be a challenge despite the impressive performance of state of the art AI planning systems and Large Language Models (LLMs) because of the uncertainty associated with the tasks and their outcomes. Toward addressing this challenge, we present a hybrid framework that integrates the generic prediction capabilities of an LLM with the probabilistic sequential decision-making capability of Relational Dynamic Influence Diagram Language. For any given task, the robot reasons about the task and the capabilities of the human attempting to complete it; predicts potential failures due to lack of ability (in the human) or lack of relevant domain objects; and executes actions to prevent such failures or recover from them. Experimental evaluation in the VirtualHome 3D simulation environment demonstrates substantial improvement in performance compared with state of the art baselines.
Crowd-FM: Learned Optimal Selection of Conditional Flow Matching-generated Trajectories for Crowd Navigation
Feb 06, 2026Safe and computationally efficient local planning for mobile robots in dense, unstructured human crowds remains a fundamental challenge. Moreover, ensuring that robot trajectories are similar to how a human moves will increase the acceptance of the robot in human environments. In this paper, we present Crowd-FM, a learning-based approach to address both safety and human-likeness challenges. Our approach has two novel components. First, we train a Conditional Flow-Matching (CFM) policy over a dataset of optimally controlled trajectories to learn a set of collision-free primitives that a robot can choose at any given scenario. The chosen optimal control solver can generate multi-modal collision-free trajectories, allowing the CFM policy to learn a diverse set of maneuvers. Secondly, we learn a score function over a dataset of human demonstration trajectories that provides a human-likeness score for the flow primitives. At inference time, computing the optimal trajectory requires selecting the one with the highest score. Our approach improves the state-of-the-art by showing that our CFM policy alone can produce collision-free navigation with a higher success rate than existing learning-based baselines. Furthermore, when augmented with inference-time refinement, our approach can outperform even expensive optimisation-based planning approaches. Finally, we validate that our scoring network can select trajectories closer to the expert data than a manually designed cost function.
MonoMPC: Monocular Vision Based Navigation with Learned Collision Model and Risk-Aware Model Predictive Control
Aug 10, 2025Navigating unknown environments with a single RGB camera is challenging, as the lack of depth information prevents reliable collision-checking. While some methods use estimated depth to build collision maps, we found that depth estimates from vision foundation models are too noisy for zero-shot navigation in cluttered environments. We propose an alternative approach: instead of using noisy estimated depth for direct collision-checking, we use it as a rich context input to a learned collision model. This model predicts the distribution of minimum obstacle clearance that the robot can expect for a given control sequence. At inference, these predictions inform a risk-aware MPC planner that minimizes estimated collision risk. Our joint learning pipeline co-trains the collision model and risk metric using both safe and unsafe trajectories. Crucially, our joint-training ensures optimal variance in our collision model that improves navigation in highly cluttered environments. Consequently, real-world experiments show 9x and 7x improvements in success rates over NoMaD and the ROS stack, respectively. Ablation studies further validate the effectiveness of our design choices.
SparseLoc: Sparse Open-Set Landmark-based Global Localization for Autonomous Navigation
Mar 30, 2025



Global localization is a critical problem in autonomous navigation, enabling precise positioning without reliance on GPS. Modern global localization techniques often depend on dense LiDAR maps, which, while precise, require extensive storage and computational resources. Recent approaches have explored alternative methods, such as sparse maps and learned features, but they suffer from poor robustness and generalization. We propose SparseLoc, a global localization framework that leverages vision-language foundation models to generate sparse, semantic-topometric maps in a zero-shot manner. It combines this map representation with a Monte Carlo localization scheme enhanced by a novel late optimization strategy, ensuring improved pose estimation. By constructing compact yet highly discriminative maps and refining localization through a carefully designed optimization schedule, SparseLoc overcomes the limitations of existing techniques, offering a more efficient and robust solution for global localization. Our system achieves over a 5X improvement in localization accuracy compared to existing sparse mapping techniques. Despite utilizing only 1/500th of the points of dense mapping methods, it achieves comparable performance, maintaining an average global localization error below 5m and 2 degrees on KITTI sequences.
Swarm-Gen: Fast Generation of Diverse Feasible Swarm Behaviors
Jan 31, 2025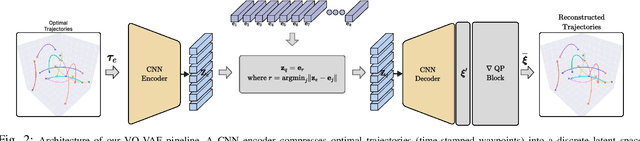
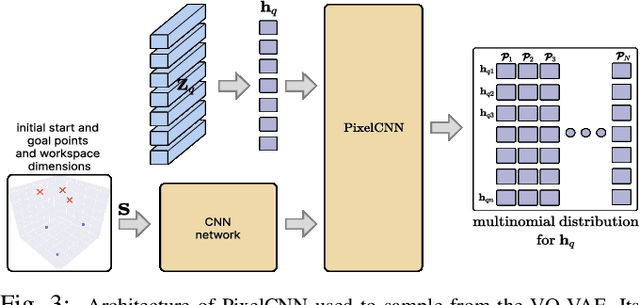

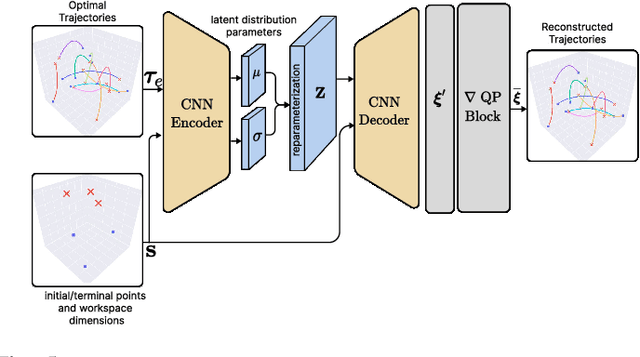
Coordination behavior in robot swarms is inherently multi-modal in nature. That is, there are numerous ways in which a swarm of robots can avoid inter-agent collisions and reach their respective goals. However, the problem of generating diverse and feasible swarm behaviors in a scalable manner remains largely unaddressed. In this paper, we fill this gap by combining generative models with a safety-filter (SF). Specifically, we sample diverse trajectories from a learned generative model which is subsequently projected onto the feasible set using the SF. We experiment with two choices for generative models, namely: Conditional Variational Autoencoder (CVAE) and Vector-Quantized Variational Autoencoder (VQ-VAE). We highlight the trade-offs these two models provide in terms of computation time and trajectory diversity. We develop a custom solver for our SF and equip it with a neural network that predicts context-specific initialization. Thecinitialization network is trained in a self-supervised manner, taking advantage of the differentiability of the SF solver. We provide two sets of empirical results. First, we demonstrate that we can generate a large set of multi-modal, feasible trajectories, simulating diverse swarm behaviors, within a few tens of milliseconds. Second, we show that our initialization network provides faster convergence of our SF solver vis-a-vis other alternative heuristics.
Imagine2Servo: Intelligent Visual Servoing with Diffusion-Driven Goal Generation for Robotic Tasks
Oct 16, 2024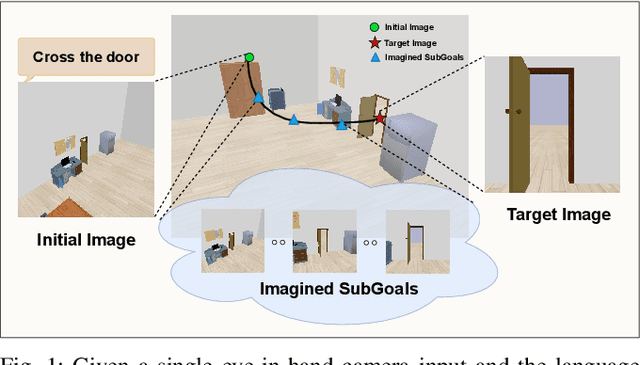
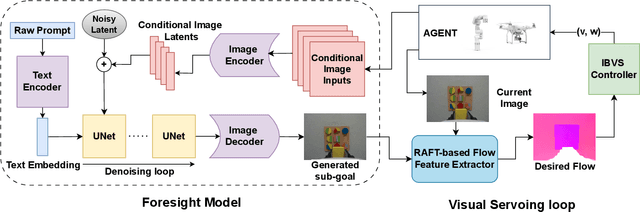
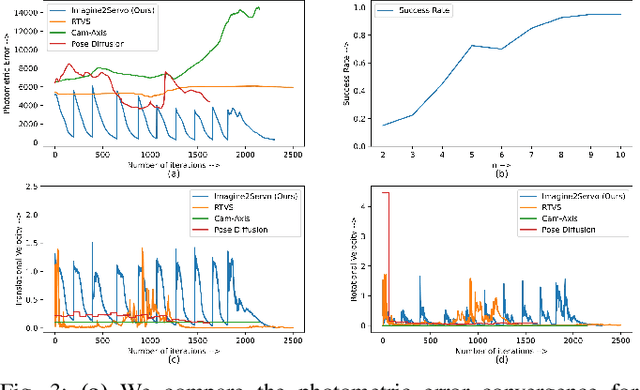

Visual servoing, the method of controlling robot motion through feedback from visual sensors, has seen significant advancements with the integration of optical flow-based methods. However, its application remains limited by inherent challenges, such as the necessity for a target image at test time, the requirement of substantial overlap between initial and target images, and the reliance on feedback from a single camera. This paper introduces Imagine2Servo, an innovative approach leveraging diffusion-based image editing techniques to enhance visual servoing algorithms by generating intermediate goal images. This methodology allows for the extension of visual servoing applications beyond traditional constraints, enabling tasks like long-range navigation and manipulation without predefined goal images. We propose a pipeline that synthesizes subgoal images grounded in the task at hand, facilitating servoing in scenarios with minimal initial and target image overlap and integrating multi-camera feedback for comprehensive task execution. Our contributions demonstrate a novel application of image generation to robotic control, significantly broadening the capabilities of visual servoing systems. Real-world experiments validate the effectiveness and versatility of the Imagine2Servo framework in accomplishing a variety of tasks, marking a notable advancement in the field of visual servoing.
CrowdSurfer: Sampling Optimization Augmented with Vector-Quantized Variational AutoEncoder for Dense Crowd Navigation
Sep 24, 2024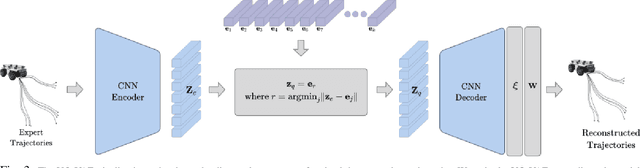
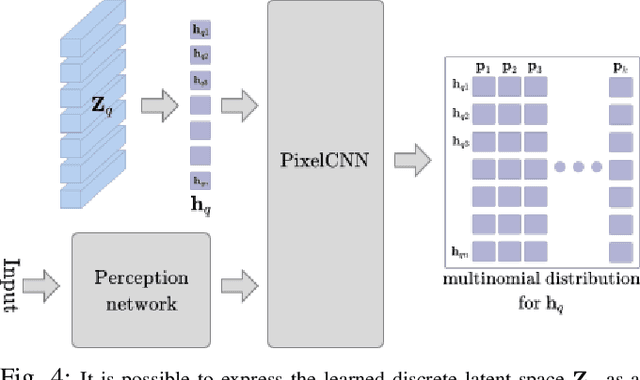
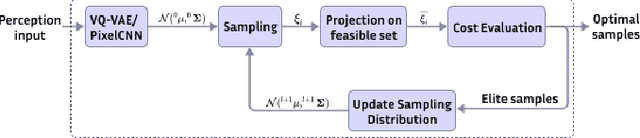
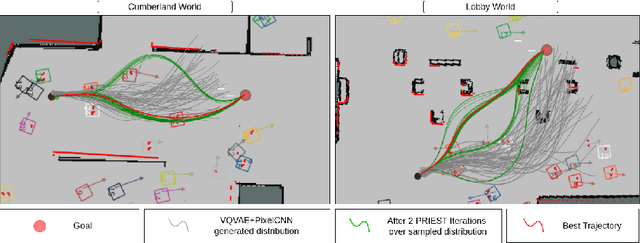
Navigation amongst densely packed crowds remains a challenge for mobile robots. The complexity increases further if the environment layout changes, making the prior computed global plan infeasible. In this paper, we show that it is possible to dramatically enhance crowd navigation by just improving the local planner. Our approach combines generative modelling with inference time optimization to generate sophisticated long-horizon local plans at interactive rates. More specifically, we train a Vector Quantized Variational AutoEncoder to learn a prior over the expert trajectory distribution conditioned on the perception input. At run-time, this is used as an initialization for a sampling-based optimizer for further refinement. Our approach does not require any sophisticated prediction of dynamic obstacles and yet provides state-of-the-art performance. In particular, we compare against the recent DRL-VO approach and show a 40% improvement in success rate and a 6% improvement in travel time.
Open-Set 3D Semantic Instance Maps for Vision Language Navigation -- O3D-SIM
Apr 27, 2024Humans excel at forming mental maps of their surroundings, equipping them to understand object relationships and navigate based on language queries. Our previous work SI Maps [1] showed that having instance-level information and the semantic understanding of an environment helps significantly improve performance for language-guided tasks. We extend this instance-level approach to 3D while increasing the pipeline's robustness and improving quantitative and qualitative results. Our method leverages foundational models for object recognition, image segmentation, and feature extraction. We propose a representation that results in a 3D point cloud map with instance-level embeddings, which bring in the semantic understanding that natural language commands can query. Quantitatively, the work improves upon the success rate of language-guided tasks. At the same time, we qualitatively observe the ability to identify instances more clearly and leverage the foundational models and language and image-aligned embeddings to identify objects that, otherwise, a closed-set approach wouldn't be able to identify.
Bi-level Trajectory Optimization on Uneven Terrains with Differentiable Wheel-Terrain Interaction Model
Apr 11, 2024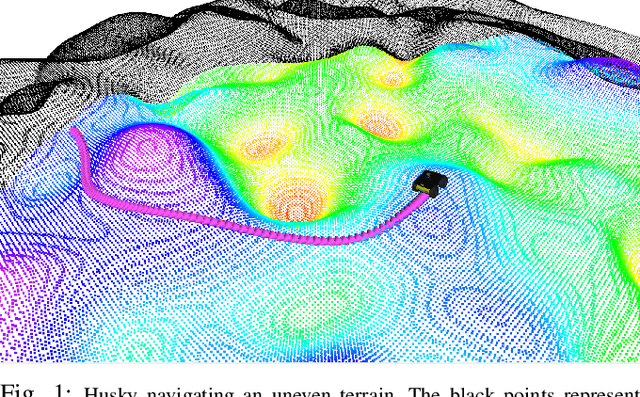
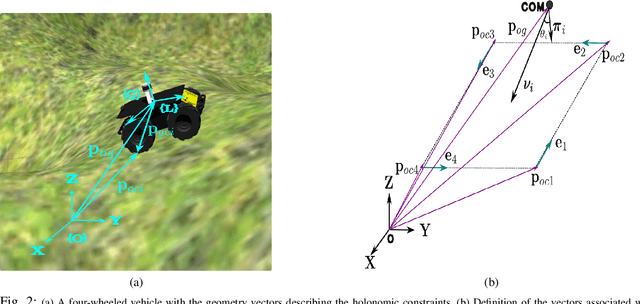
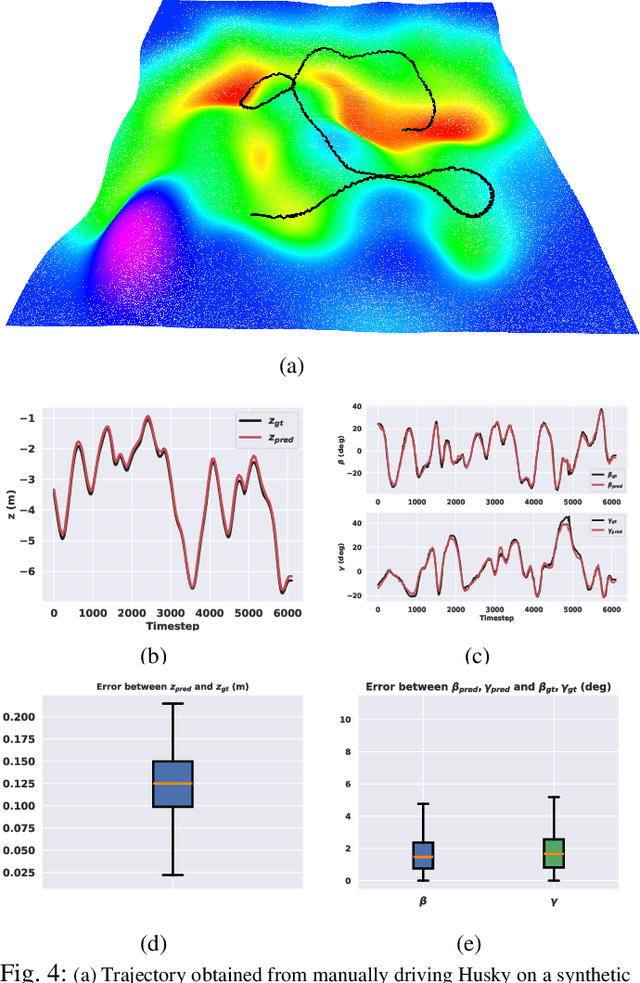
Navigation of wheeled vehicles on uneven terrain necessitates going beyond the 2D approaches for trajectory planning. Specifically, it is essential to incorporate the full 6dof variation of vehicle pose and its associated stability cost in the planning process. To this end, most recent works aim to learn a neural network model to predict the vehicle evolution. However, such approaches are data-intensive and fraught with generalization issues. In this paper, we present a purely model-based approach that just requires the digital elevation information of the terrain. Specifically, we express the wheel-terrain interaction and 6dof pose prediction as a non-linear least squares (NLS) problem. As a result, trajectory planning can be viewed as a bi-level optimization. The inner optimization layer predicts the pose on the terrain along a given trajectory, while the outer layer deforms the trajectory itself to reduce the stability and kinematic costs of the pose. We improve the state-of-the-art in the following respects. First, we show that our NLS based pose prediction closely matches the output from a high-fidelity physics engine. This result coupled with the fact that we can query gradients of the NLS solver, makes our pose predictor, a differentiable wheel-terrain interaction model. We further leverage this differentiability to efficiently solve the proposed bi-level trajectory optimization problem. Finally, we perform extensive experiments, and comparison with a baseline to showcase the effectiveness of our approach in obtaining smooth, stable trajectories.
LeGo-Drive: Language-enhanced Goal-oriented Closed-Loop End-to-End Autonomous Driving
Mar 29, 2024



Existing Vision-Language models (VLMs) estimate either long-term trajectory waypoints or a set of control actions as a reactive solution for closed-loop planning based on their rich scene comprehension. However, these estimations are coarse and are subjective to their "world understanding" which may generate sub-optimal decisions due to perception errors. In this paper, we introduce LeGo-Drive, which aims to address this issue by estimating a goal location based on the given language command as an intermediate representation in an end-to-end setting. The estimated goal might fall in a non-desirable region, like on top of a car for a parking-like command, leading to inadequate planning. Hence, we propose to train the architecture in an end-to-end manner, resulting in iterative refinement of both the goal and the trajectory collectively. We validate the effectiveness of our method through comprehensive experiments conducted in diverse simulated environments. We report significant improvements in standard autonomous driving metrics, with a goal reaching Success Rate of 81%. We further showcase the versatility of LeGo-Drive across different driving scenarios and linguistic inputs, underscoring its potential for practical deployment in autonomous vehicles and intelligent transportation systems.