 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwarm-Gen: Fast Generation of Diverse Feasible Swarm Behaviors
Jan 31, 2025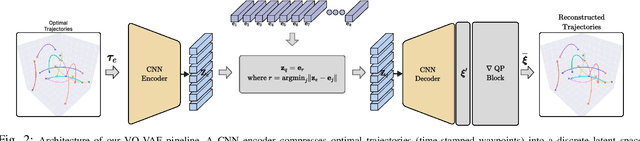
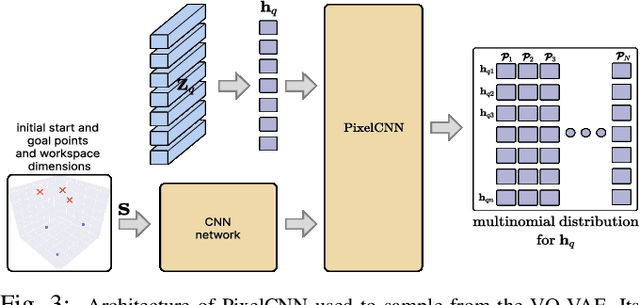

Coordination behavior in robot swarms is inherently multi-modal in nature. That is, there are numerous ways in which a swarm of robots can avoid inter-agent collisions and reach their respective goals. However, the problem of generating diverse and feasible swarm behaviors in a scalable manner remains largely unaddressed. In this paper, we fill this gap by combining generative models with a safety-filter (SF). Specifically, we sample diverse trajectories from a learned generative model which is subsequently projected onto the feasible set using the SF. We experiment with two choices for generative models, namely: Conditional Variational Autoencoder (CVAE) and Vector-Quantized Variational Autoencoder (VQ-VAE). We highlight the trade-offs these two models provide in terms of computation time and trajectory diversity. We develop a custom solver for our SF and equip it with a neural network that predicts context-specific initialization. Thecinitialization network is trained in a self-supervised manner, taking advantage of the differentiability of the SF solver. We provide two sets of empirical results. First, we demonstrate that we can generate a large set of multi-modal, feasible trajectories, simulating diverse swarm behaviors, within a few tens of milliseconds. Second, we show that our initialization network provides faster convergence of our SF solver vis-a-vis other alternative heuristics.
CrowdSurfer: Sampling Optimization Augmented with Vector-Quantized Variational AutoEncoder for Dense Crowd Navigation
Sep 24, 2024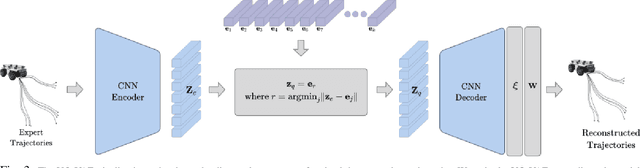
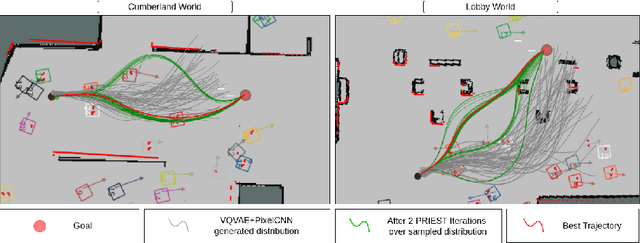
Navigation amongst densely packed crowds remains a challenge for mobile robots. The complexity increases further if the environment layout changes, making the prior computed global plan infeasible. In this paper, we show that it is possible to dramatically enhance crowd navigation by just improving the local planner. Our approach combines generative modelling with inference time optimization to generate sophisticated long-horizon local plans at interactive rates. More specifically, we train a Vector Quantized Variational AutoEncoder to learn a prior over the expert trajectory distribution conditioned on the perception input. At run-time, this is used as an initialization for a sampling-based optimizer for further refinement. Our approach does not require any sophisticated prediction of dynamic obstacles and yet provides state-of-the-art performance. In particular, we compare against the recent DRL-VO approach and show a 40% improvement in success rate and a 6% improvement in travel time.
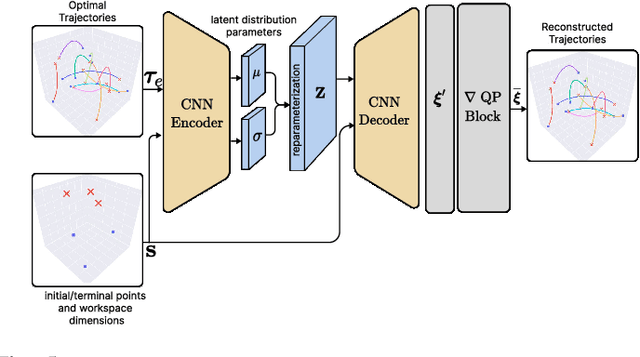
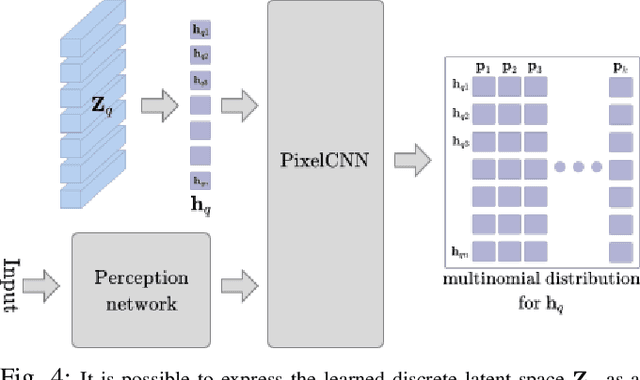
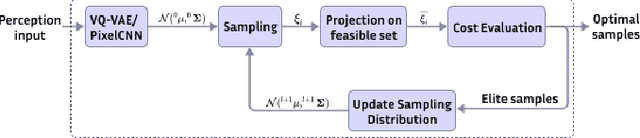
Learning Sampling Distribution and Safety Filter for Autonomous Driving with VQ-VAE and Differentiable Optimization
Mar 28, 2024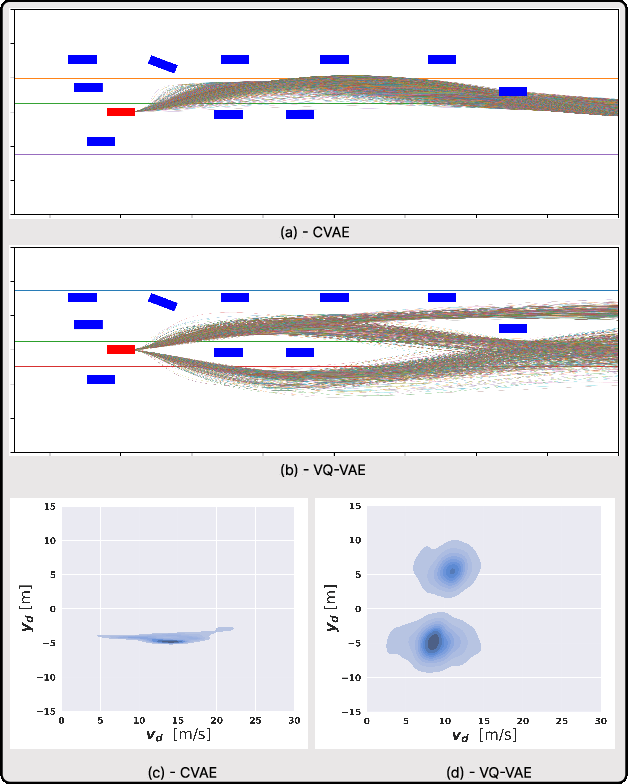

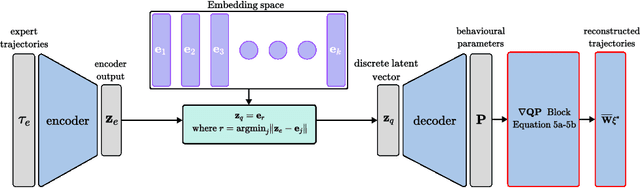
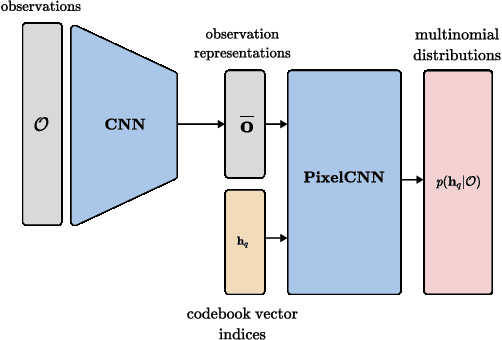
Sampling trajectories from a distribution followed by ranking them based on a specified cost function is a common approach in autonomous driving. Typically, the sampling distribution is hand-crafted (e.g a Gaussian, or a grid). Recently, there have been efforts towards learning the sampling distribution through generative models such as Conditional Variational Autoencoder (CVAE). However, these approaches fail to capture the multi-modality of the driving behaviour due to the Gaussian latent prior of the CVAE. Thus, in this paper, we re-imagine the distribution learning through vector quantized variational autoencoder (VQ-VAE), whose discrete latent-space is well equipped to capture multi-modal sampling distribution. The VQ-VAE is trained with demonstration data of optimal trajectories. We further propose a differentiable optimization based safety filter to minimally correct the VQVAE sampled trajectories to ensure collision avoidance. We use backpropagation through the optimization layers in a self-supervised learning set-up to learn good initialization and optimal parameters of the safety filter. We perform extensive comparisons with state-of-the-art CVAE-based baseline in dense and aggressive traffic scenarios and show a reduction of up to 12 times in collision-rate while being competitive in driving speeds.
End-to-End Learning of Behavioural Inputs for Autonomous Driving in Dense Traffic
Oct 23, 2023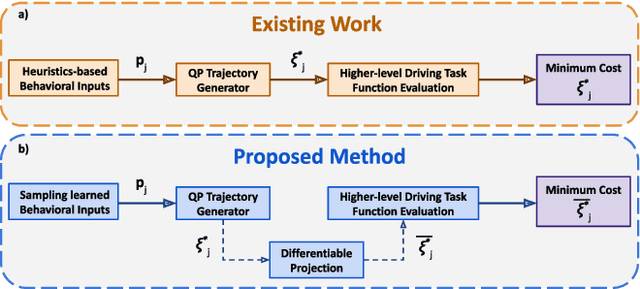
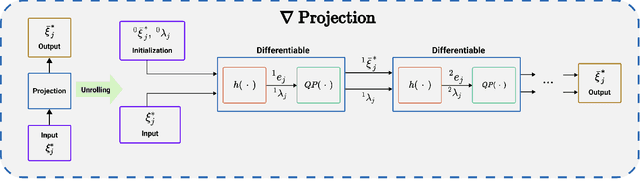
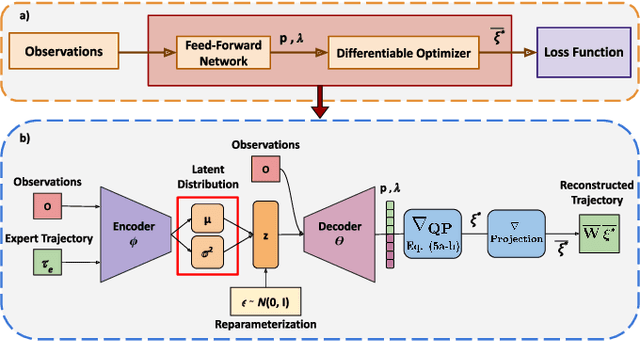
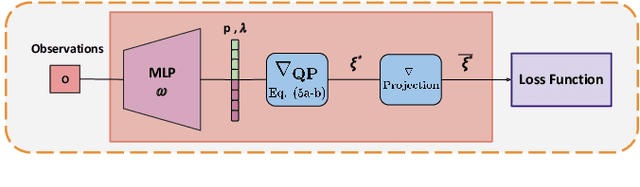
Trajectory sampling in the Frenet(road-aligned) frame, is one of the most popular methods for motion planning of autonomous vehicles. It operates by sampling a set of behavioural inputs, such as lane offset and forward speed, before solving a trajectory optimization problem conditioned on the sampled inputs. The sampling is handcrafted based on simple heuristics, does not adapt to driving scenarios, and is oblivious to the capabilities of downstream trajectory planners. In this paper, we propose an end-to-end learning of behavioural input distribution from expert demonstrations or in a self-supervised manner. Our core novelty lies in embedding a custom differentiable trajectory optimizer as a layer in neural networks, allowing us to update behavioural inputs by considering the optimizer's feedback. Moreover, our end-to-end approach also ensures that the learned behavioural inputs aid the convergence of the optimizer. We improve the state-of-the-art in the following aspects. First, we show that learned behavioural inputs substantially decrease collision rate while improving driving efficiency over handcrafted approaches. Second, our approach outperforms model predictive control methods based on sampling-based optimization.