 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdSurfer: Sampling Optimization Augmented with Vector-Quantized Variational AutoEncoder for Dense Crowd Navigation
Sep 24, 2024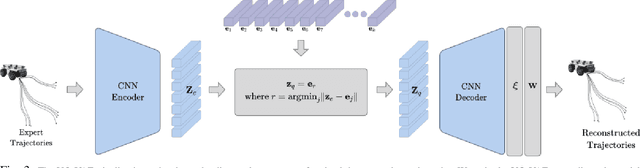
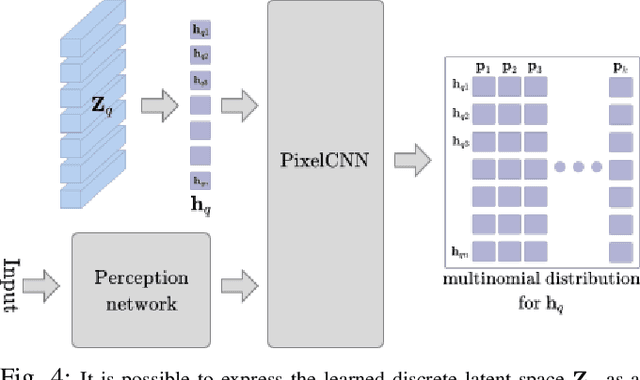
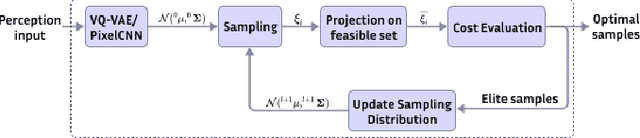
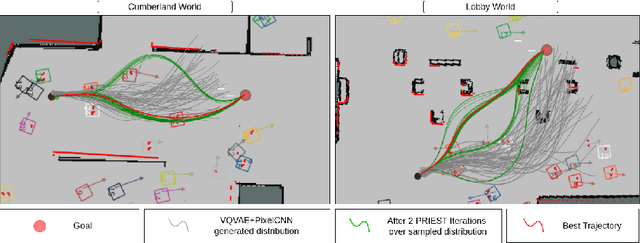
Navigation amongst densely packed crowds remains a challenge for mobile robots. The complexity increases further if the environment layout changes, making the prior computed global plan infeasible. In this paper, we show that it is possible to dramatically enhance crowd navigation by just improving the local planner. Our approach combines generative modelling with inference time optimization to generate sophisticated long-horizon local plans at interactive rates. More specifically, we train a Vector Quantized Variational AutoEncoder to learn a prior over the expert trajectory distribution conditioned on the perception input. At run-time, this is used as an initialization for a sampling-based optimizer for further refinement. Our approach does not require any sophisticated prediction of dynamic obstacles and yet provides state-of-the-art performance. In particular, we compare against the recent DRL-VO approach and show a 40% improvement in success rate and a 6% improvement in travel time.
Open-Set 3D Semantic Instance Maps for Vision Language Navigation -- O3D-SIM
Apr 27, 2024Humans excel at forming mental maps of their surroundings, equipping them to understand object relationships and navigate based on language queries. Our previous work SI Maps [1] showed that having instance-level information and the semantic understanding of an environment helps significantly improve performance for language-guided tasks. We extend this instance-level approach to 3D while increasing the pipeline's robustness and improving quantitative and qualitative results. Our method leverages foundational models for object recognition, image segmentation, and feature extraction. We propose a representation that results in a 3D point cloud map with instance-level embeddings, which bring in the semantic understanding that natural language commands can query. Quantitatively, the work improves upon the success rate of language-guided tasks. At the same time, we qualitatively observe the ability to identify instances more clearly and leverage the foundational models and language and image-aligned embeddings to identify objects that, otherwise, a closed-set approach wouldn't be able to identify.
Instance-Level Semantic Maps for Vision Language Navigation
May 23, 2023Humans have a natural ability to perform semantic associations with the surrounding objects in the environment. This allows them to create a mental map of the environment which helps them to navigate on-demand when given a linguistic instruction. A natural goal in Vision Language Navigation (VLN) research is to impart autonomous agents with similar capabilities. Recently introduced VL Maps \cite{huang23vlmaps} take a step towards this goal by creating a semantic spatial map representation of the environment without any labelled data. However, their representations are limited for practical applicability as they do not distinguish between different instances of the same object. In this work, we address this limitation by integrating instance-level information into spatial map representation using a community detection algorithm and by utilizing word ontology learned by large language models (LLMs) to perform open-set semantic associations in the mapping representation. The resulting map representation improves the navigation performance by two-fold (233\%) on realistic language commands with instance-specific descriptions compared to VL Maps. We validate the practicality and effectiveness of our approach through extensive qualitative and quantitative experiments.