 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Set 3D Semantic Instance Maps for Vision Language Navigation -- O3D-SIM
Apr 27, 2024Humans excel at forming mental maps of their surroundings, equipping them to understand object relationships and navigate based on language queries. Our previous work SI Maps [1] showed that having instance-level information and the semantic understanding of an environment helps significantly improve performance for language-guided tasks. We extend this instance-level approach to 3D while increasing the pipeline's robustness and improving quantitative and qualitative results. Our method leverages foundational models for object recognition, image segmentation, and feature extraction. We propose a representation that results in a 3D point cloud map with instance-level embeddings, which bring in the semantic understanding that natural language commands can query. Quantitatively, the work improves upon the success rate of language-guided tasks. At the same time, we qualitatively observe the ability to identify instances more clearly and leverage the foundational models and language and image-aligned embeddings to identify objects that, otherwise, a closed-set approach wouldn't be able to identify.
IDD-3D: Indian Driving Dataset for 3D Unstructured Road Scenes
Oct 23, 2022



Autonomous driving and assistance systems rely on annotated data from traffic and road scenarios to model and learn the various object relations in complex real-world scenarios. Preparation and training of deploy-able deep learning architectures require the models to be suited to different traffic scenarios and adapt to different situations. Currently, existing datasets, while large-scale, lack such diversities and are geographically biased towards mainly developed cities. An unstructured and complex driving layout found in several developing countries such as India poses a challenge to these models due to the sheer degree of variations in the object types, densities, and locations. To facilitate better research toward accommodating such scenarios, we build a new dataset, IDD-3D, which consists of multi-modal data from multiple cameras and LiDAR sensors with 12k annotated driving LiDAR frames across various traffic scenarios. We discuss the need for this dataset through statistical comparisons with existing datasets and highlight benchmarks on standard 3D object detection and tracking tasks in complex layouts. Code and data available at https://github.com/shubham1810/idd3d_kit.git
A Deep Learning Approach for Robust Corridor Following
Nov 18, 2019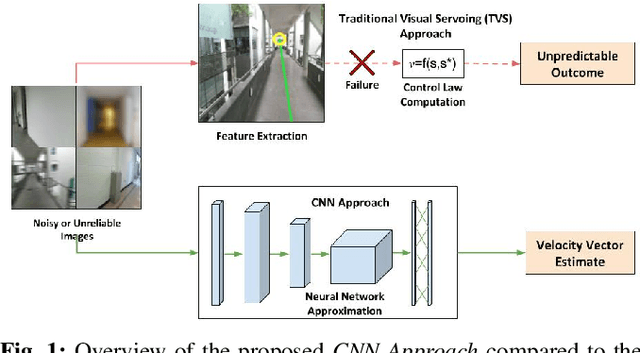
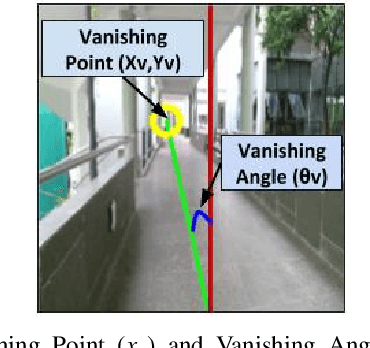

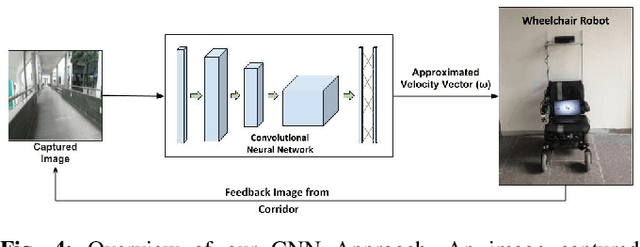
For an autonomous corridor following task where the environment is continuously changing, several forms of environmental noise prevent an automated feature extraction procedure from performing reliably. Moreover, in cases where pre-defined features are absent from the captured data, a well defined control signal for performing the servoing task fails to get produced. In order to overcome these drawbacks, we present in this work, using a convolutional neural network (CNN) to directly estimate the required control signal from an image, encompassing feature extraction and control law computation into one single end-to-end framework. In particular, we study the task of autonomous corridor following using a CNN and present clear advantages in cases where a traditional method used for performing the same task fails to give a reliable outcome. We evaluate the performance of our method on this task on a Wheelchair Platform developed at our institute for this purpose.
Connecting Visual Experiences using Max-flow Network with Application to Visual Localization
Aug 01, 2018

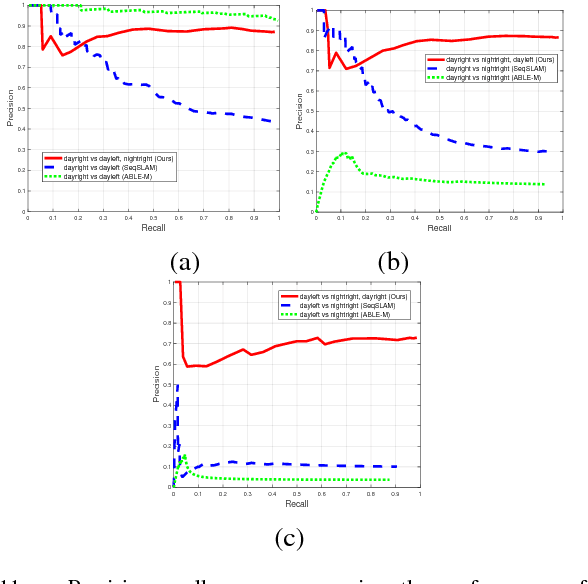
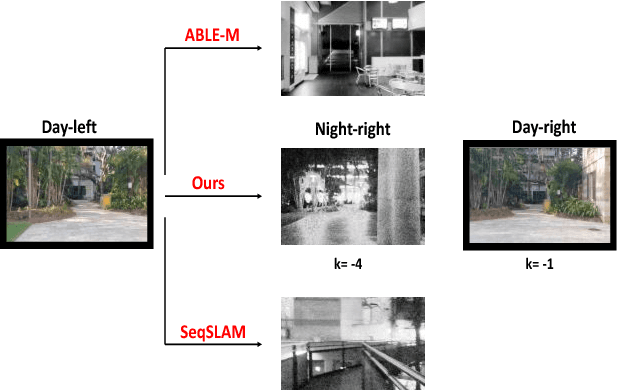
We are motivated by the fact that multiple representations of the environment are required to stand for the changes in appearance with time and for changes that appear in a cyclic manner. These changes are, for example, from day to night time, and from day to day across seasons. In such situations, the robot visits the same routes multiple times and collects different appearances of it. Multiple visual experiences usually find robotic vision applications like visual localization, mapping, place recognition, and autonomous navigation. The novelty in this paper is an algorithm that connects multiple visual experiences via aligning multiple image sequences. This problem is solved by finding the maximum flow in a directed graph flow-network, whose vertices represent the matches between frames in the test and reference sequences. Edges of the graph represent the cost of these matches. The problem of finding the best match is reduced to finding the minimum-cut surface, which is solved as a maximum flow network problem. Application to visual localization is considered in this paper to show the effectiveness of the proposed multiple image sequence alignment method, without loosing its generality. Experimental evaluations show that the precision of sequence matching is improved by considering multiple visual sequences for the same route, and that the method performs favorably against state-of-the-art single representation methods like SeqSLAM and ABLE-M.