 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Reasons Help Improve Pedestrian Intent Estimation? A Cross-Modal Approach
Nov 20, 2024



With the increased importance of autonomous navigation systems has come an increasing need to protect the safety of Vulnerable Road Users (VRUs) such as pedestrians. Predicting pedestrian intent is one such challenging task, where prior work predicts the binary cross/no-cross intention with a fusion of visual and motion features. However, there has been no effort so far to hedge such predictions with human-understandable reasons. We address this issue by introducing a novel problem setting of exploring the intuitive reasoning behind a pedestrian's intent. In particular, we show that predicting the 'WHY' can be very useful in understanding the 'WHAT'. To this end, we propose a novel, reason-enriched PIE++ dataset consisting of multi-label textual explanations/reasons for pedestrian intent. We also introduce a novel multi-task learning framework called MINDREAD, which leverages a cross-modal representation learning framework for predicting pedestrian intent as well as the reason behind the intent. Our comprehensive experiments show significant improvement of 5.6% and 7% in accuracy and F1-score for the task of intent prediction on the PIE++ dataset using MINDREAD. We also achieved a 4.4% improvement in accuracy on a commonly used JAAD dataset. Extensive evaluation using quantitative/qualitative metrics and user studies shows the effectiveness of our approach.
CueCAn: Cue Driven Contextual Attention For Identifying Missing Traffic Signs on Unconstrained Roads
Mar 05, 2023



Unconstrained Asian roads often involve poor infrastructure, affecting overall road safety. Missing traffic signs are a regular part of such roads. Missing or non-existing object detection has been studied for locating missing curbs and estimating reasonable regions for pedestrians on road scene images. Such methods involve analyzing task-specific single object cues. In this paper, we present the first and most challenging video dataset for missing objects, with multiple types of traffic signs for which the cues are visible without the signs in the scenes. We refer to it as the Missing Traffic Signs Video Dataset (MTSVD). MTSVD is challenging compared to the previous works in two aspects i) The traffic signs are generally not present in the vicinity of their cues, ii) The traffic signs cues are diverse and unique. Also, MTSVD is the first publicly available missing object dataset. To train the models for identifying missing signs, we complement our dataset with 10K traffic sign tracks, with 40 percent of the traffic signs having cues visible in the scenes. For identifying missing signs, we propose the Cue-driven Contextual Attention units (CueCAn), which we incorporate in our model encoder. We first train the encoder to classify the presence of traffic sign cues and then train the entire segmentation model end-to-end to localize missing traffic signs. Quantitative and qualitative analysis shows that CueCAn significantly improves the performance of base models.
IDD-3D: Indian Driving Dataset for 3D Unstructured Road Scenes
Oct 23, 2022



Autonomous driving and assistance systems rely on annotated data from traffic and road scenarios to model and learn the various object relations in complex real-world scenarios. Preparation and training of deploy-able deep learning architectures require the models to be suited to different traffic scenarios and adapt to different situations. Currently, existing datasets, while large-scale, lack such diversities and are geographically biased towards mainly developed cities. An unstructured and complex driving layout found in several developing countries such as India poses a challenge to these models due to the sheer degree of variations in the object types, densities, and locations. To facilitate better research toward accommodating such scenarios, we build a new dataset, IDD-3D, which consists of multi-modal data from multiple cameras and LiDAR sensors with 12k annotated driving LiDAR frames across various traffic scenarios. We discuss the need for this dataset through statistical comparisons with existing datasets and highlight benchmarks on standard 3D object detection and tracking tasks in complex layouts. Code and data available at https://github.com/shubham1810/idd3d_kit.git
TRoVE: Transforming Road Scene Datasets into Photorealistic Virtual Environments
Aug 16, 2022

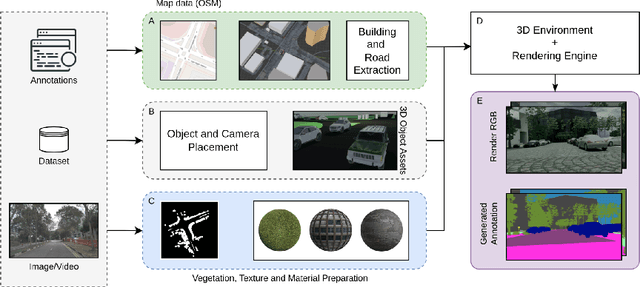
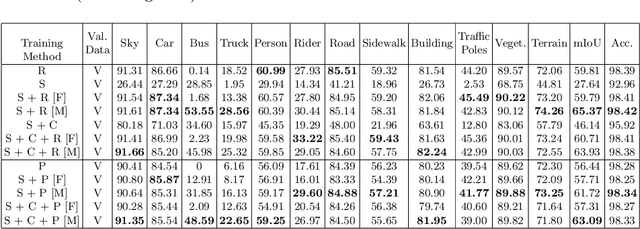
High-quality structured data with rich annotations are critical components in intelligent vehicle systems dealing with road scenes. However, data curation and annotation require intensive investments and yield low-diversity scenarios. The recently growing interest in synthetic data raises questions about the scope of improvement in such systems and the amount of manual work still required to produce high volumes and variations of simulated data. This work proposes a synthetic data generation pipeline that utilizes existing datasets, like nuScenes, to address the difficulties and domain-gaps present in simulated datasets. We show that using annotations and visual cues from existing datasets, we can facilitate automated multi-modal data generation, mimicking real scene properties with high-fidelity, along with mechanisms to diversify samples in a physically meaningful way. We demonstrate improvements in mIoU metrics by presenting qualitative and quantitative experiments with real and synthetic data for semantic segmentation on the Cityscapes and KITTI-STEP datasets. All relevant code and data is released on github (https://github.com/shubham1810/trove_toolkit).
Detecting, Tracking and Counting Motorcycle Rider Traffic Violations on Unconstrained Roads
Apr 18, 2022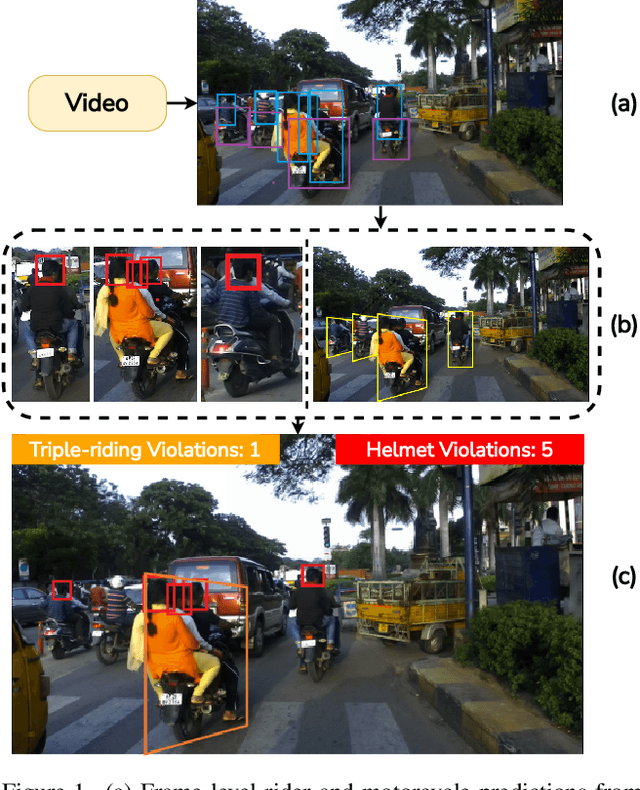
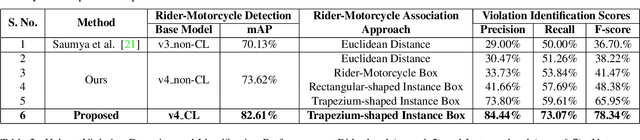
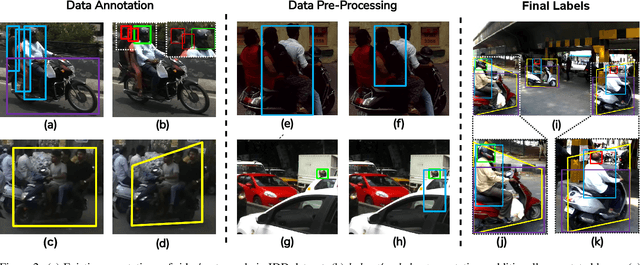
In many Asian countries with unconstrained road traffic conditions, driving violations such as not wearing helmets and triple-riding are a significant source of fatalities involving motorcycles. Identifying and penalizing such riders is vital in curbing road accidents and improving citizens' safety. With this motivation, we propose an approach for detecting, tracking, and counting motorcycle riding violations in videos taken from a vehicle-mounted dashboard camera. We employ a curriculum learning-based object detector to better tackle challenging scenarios such as occlusions. We introduce a novel trapezium-shaped object boundary representation to increase robustness and tackle the rider-motorcycle association. We also introduce an amodal regressor that generates bounding boxes for the occluded riders. Experimental results on a large-scale unconstrained driving dataset demonstrate the superiority of our approach compared to existing approaches and other ablative variants.
Automatic Quantification and Visualization of Street Trees
Jan 17, 2022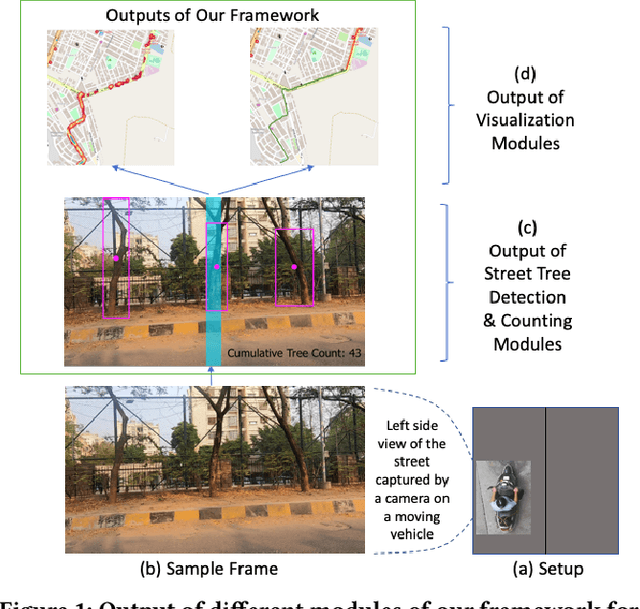

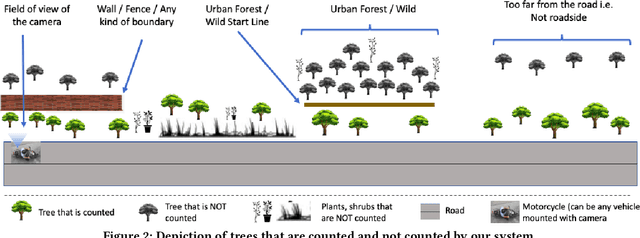
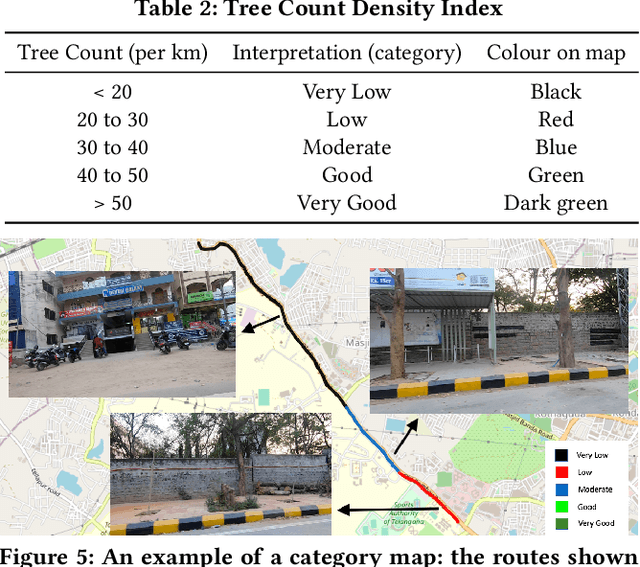
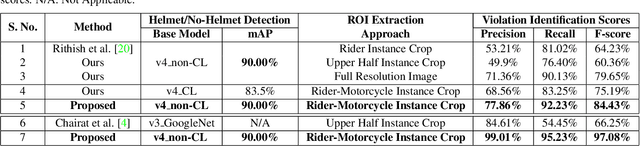
Assessing the number of street trees is essential for evaluating urban greenery and can help municipalities employ solutions to identify tree-starved streets. It can also help identify roads with different levels of deforestation and afforestation over time. Yet, there has been little work in the area of street trees quantification. This work first explains a data collection setup carefully designed for counting roadside trees. We then describe a unique annotation procedure aimed at robustly detecting and quantifying trees. We work on a dataset of around 1300 Indian road scenes annotated with over 2500 street trees. We additionally use the five held-out videos covering 25 km of roads for counting trees. We finally propose a street tree detection, counting, and visualization framework using current object detectors and a novel yet simple counting algorithm owing to the thoughtful collection setup. We find that the high-level visualizations based on the density of trees on the routes and Kernel Density Ranking (KDR) provide a quick, accurate, and inexpensive way to recognize tree-starved streets. We obtain a tree detection mAP of 83.74% on the test images, which is a 2.73% improvement over our baseline. We propose Tree Count Density Classification Accuracy (TCDCA) as an evaluation metric to measure tree density. We obtain TCDCA of 96.77% on the test videos, with a remarkable improvement of 22.58% over baseline, and demonstrate that our counting module's performance is close to human level. Source code: https://github.com/iHubData-Mobility/public-tree-counting.
Attention Guided Cosine Margin For Overcoming Class-Imbalance in Few-Shot Road Object Detection
Nov 12, 2021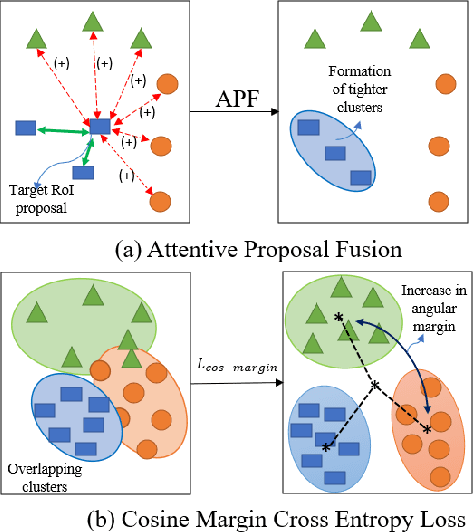
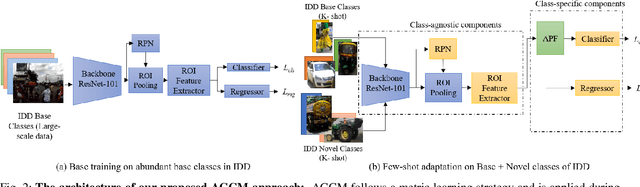
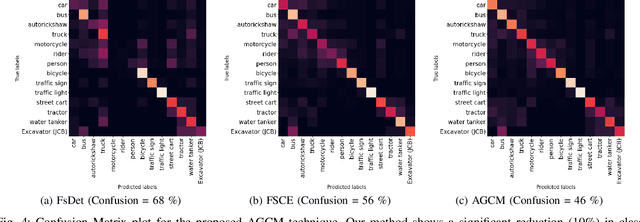
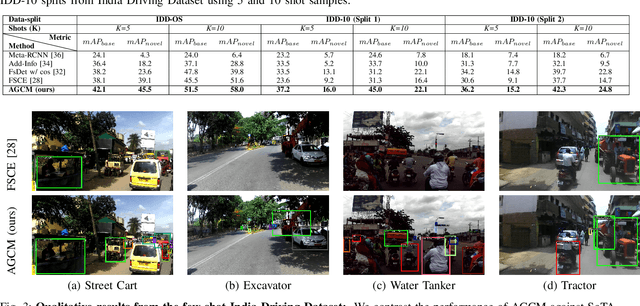
Few-shot object detection (FSOD) localizes and classifies objects in an image given only a few data samples. Recent trends in FSOD research show the adoption of metric and meta-learning techniques, which are prone to catastrophic forgetting and class confusion. To overcome these pitfalls in metric learning based FSOD techniques, we introduce Attention Guided Cosine Margin (AGCM) that facilitates the creation of tighter and well separated class-specific feature clusters in the classification head of the object detector. Our novel Attentive Proposal Fusion (APF) module minimizes catastrophic forgetting by reducing the intra-class variance among co-occurring classes. At the same time, the proposed Cosine Margin Cross-Entropy loss increases the angular margin between confusing classes to overcome the challenge of class confusion between already learned (base) and newly added (novel) classes. We conduct our experiments on the challenging India Driving Dataset (IDD), which presents a real-world class-imbalanced setting alongside popular FSOD benchmark PASCAL-VOC. Our method outperforms State-of-the-Art (SoTA) approaches by up to 6.4 mAP points on the IDD-OS and up to 2.0 mAP points on the IDD-10 splits for the 10-shot setting. On the PASCAL-VOC dataset, we outperform existing SoTA approaches by up to 4.9 mAP points.
Meta Guided Metric Learner for Overcoming Class Confusion in Few-Shot Road Object Detection
Oct 28, 2021
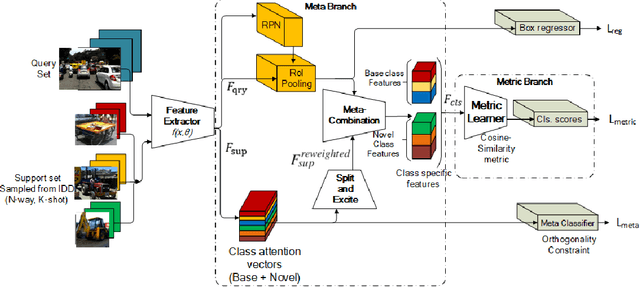
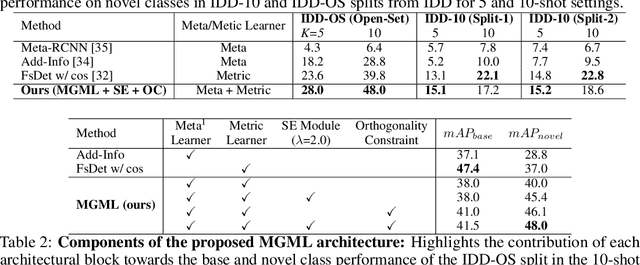

Localization and recognition of less-occurring road objects have been a challenge in autonomous driving applications due to the scarcity of data samples. Few-Shot Object Detection techniques extend the knowledge from existing base object classes to learn novel road objects given few training examples. Popular techniques in FSOD adopt either meta or metric learning techniques which are prone to class confusion and base class forgetting. In this work, we introduce a novel Meta Guided Metric Learner (MGML) to overcome class confusion in FSOD. We re-weight the features of the novel classes higher than the base classes through a novel Squeeze and Excite module and encourage the learning of truly discriminative class-specific features by applying an Orthogonality Constraint to the meta learner. Our method outperforms State-of-the-Art (SoTA) approaches in FSOD on the India Driving Dataset (IDD) by upto 11 mAP points while suffering from the least class confusion of 20% given only 10 examples of each novel road object. We further show similar improvements on the few-shot splits of PASCAL VOC dataset where we outperform SoTA approaches by upto 5.8 mAP accross all splits.
Multi-Domain Incremental Learning for Semantic Segmentation
Oct 23, 2021

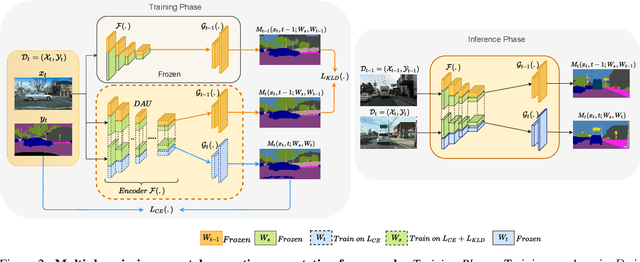
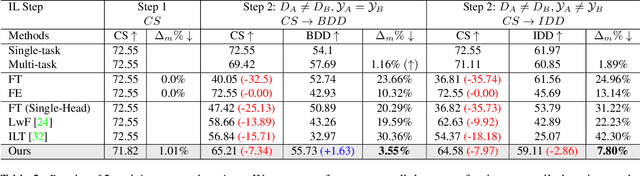
Recent efforts in multi-domain learning for semantic segmentation attempt to learn multiple geographical datasets in a universal, joint model. A simple fine-tuning experiment performed sequentially on three popular road scene segmentation datasets demonstrates that existing segmentation frameworks fail at incrementally learning on a series of visually disparate geographical domains. When learning a new domain, the model catastrophically forgets previously learned knowledge. In this work, we pose the problem of multi-domain incremental learning for semantic segmentation. Given a model trained on a particular geographical domain, the goal is to (i) incrementally learn a new geographical domain, (ii) while retaining performance on the old domain, (iii) given that the previous domain's dataset is not accessible. We propose a dynamic architecture that assigns universally shared, domain-invariant parameters to capture homogeneous semantic features present in all domains, while dedicated domain-specific parameters learn the statistics of each domain. Our novel optimization strategy helps achieve a good balance between retention of old knowledge (stability) and acquiring new knowledge (plasticity). We demonstrate the effectiveness of our proposed solution on domain incremental settings pertaining to real-world driving scenes from roads of Germany (Cityscapes), the United States (BDD100k), and India (IDD).
Few-Shot Batch Incremental Road Object Detection via Detector Fusion
Aug 18, 2021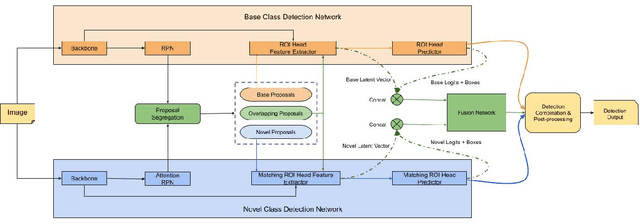


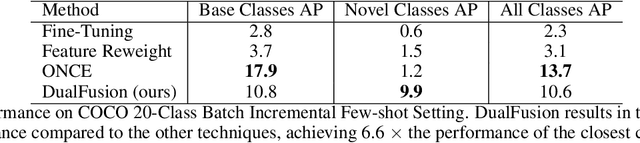
Incremental few-shot learning has emerged as a new and challenging area in deep learning, whose objective is to train deep learning models using very few samples of new class data, and none of the old class data. In this work we tackle the problem of batch incremental few-shot road object detection using data from the India Driving Dataset (IDD). Our approach, DualFusion, combines object detectors in a manner that allows us to learn to detect rare objects with very limited data, all without severely degrading the performance of the detector on the abundant classes. In the IDD OpenSet incremental few-shot detection task, we achieve a mAP50 score of 40.0 on the base classes and an overall mAP50 score of 38.8, both of which are the highest to date. In the COCO batch incremental few-shot detection task, we achieve a novel AP score of 9.9, surpassing the state-of-the-art novel class performance on the same by over 6.6 times.