 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoadTones: Tone Controllable Text Generation from Road Event Videos
May 20, 2026Existing video-language models can generate factual descriptions of road events but lack control over how these events are expressed: their tone, urgency, or style. This limits deployment in communication-critical settings where the effectiveness of a message depends on both content and presentation, not just factual accuracy. To mitigate this, we introduce a comprehensive dataset-model-evaluation suite for tone-controllable road video captioning. Our human-validated data generation pipeline expands road-video corpora with diverse tonal annotations and multi-tone captions, yielding the RoadTones-51K dataset. We propose RoadTones-VL-CoT, a controllable video-to-text model that also generates tone-conditioned Chain-of-Thought intermediate drafts for interpretability. We also introduce RoadTones-Eval, a new evaluation suite that jointly measures factual consistency and tone adherence. In addition, we conducted a user study whose results validate caption quality, tone control, and factual consistency. Together, these contributions lay the foundation for context-sensitive tone-controllable video captioning.
SeeThrough3D: Occlusion Aware 3D Control in Text-to-Image Generation
Feb 26, 2026We identify occlusion reasoning as a fundamental yet overlooked aspect for 3D layout-conditioned generation. It is essential for synthesizing partially occluded objects with depth-consistent geometry and scale. While existing methods can generate realistic scenes that follow input layouts, they often fail to model precise inter-object occlusions. We propose SeeThrough3D, a model for 3D layout conditioned generation that explicitly models occlusions. We introduce an occlusion-aware 3D scene representation (OSCR), where objects are depicted as translucent 3D boxes placed within a virtual environment and rendered from desired camera viewpoint. The transparency encodes hidden object regions, enabling the model to reason about occlusions, while the rendered viewpoint provides explicit camera control during generation. We condition a pretrained flow based text-to-image image generation model by introducing a set of visual tokens derived from our rendered 3D representation. Furthermore, we apply masked self-attention to accurately bind each object bounding box to its corresponding textual description, enabling accurate generation of multiple objects without object attribute mixing. To train the model, we construct a synthetic dataset with diverse multi-object scenes with strong inter-object occlusions. SeeThrough3D generalizes effectively to unseen object categories and enables precise 3D layout control with realistic occlusions and consistent camera control.
Unveiling Text in Challenging Stone Inscriptions: A Character-Context-Aware Patching Strategy for Binarization
Jan 07, 2026Binarization is a popular first step towards text extraction in historical artifacts. Stone inscription images pose severe challenges for binarization due to poor contrast between etched characters and the stone background, non-uniform surface degradation, distracting artifacts, and highly variable text density and layouts. These conditions frequently cause existing binarization techniques to fail and struggle to isolate coherent character regions. Many approaches sub-divide the image into patches to improve text fragment resolution and improve binarization performance. With this in mind, we present a robust and adaptive patching strategy to binarize challenging Indic inscriptions. The patches from our approach are used to train an Attention U-Net for binarization. The attention mechanism allows the model to focus on subtle structural cues, while our dynamic sampling and patch selection method ensures that the model learns to overcome surface noise and layout irregularities. We also introduce a carefully annotated, pixel-precise dataset of Indic stone inscriptions at the character-fragment level. We demonstrate that our novel patching mechanism significantly boosts binarization performance across classical and deep learning baselines. Despite training only on single script Indic dataset, our model exhibits strong zero-shot generalization to other Indic and non-indic scripts, highlighting its robustness and script-agnostic generalization capabilities. By producing clean, structured representations of inscription content, our method lays the foundation for downstream tasks such as script identification, OCR, and historical text analysis. Project page: https://ihdia.iiit.ac.in/shilalekhya-binarization/
IndicDLP: A Foundational Dataset for Multi-Lingual and Multi-Domain Document Layout Parsing
Dec 23, 2025Document layout analysis is essential for downstream tasks such as information retrieval, extraction, OCR, and digitization. However, existing large-scale datasets like PubLayNet and DocBank lack fine-grained region labels and multilingual diversity, making them insufficient for representing complex document layouts. In contrast, human-annotated datasets such as M6Doc and D4LA offer richer labels and greater domain diversity, but are too small to train robust models and lack adequate multilingual coverage. This gap is especially pronounced for Indic documents, which encompass diverse scripts yet remain underrepresented in current datasets, further limiting progress in this space. To address these shortcomings, we introduce IndicDLP, a large-scale foundational document layout dataset spanning 11 representative Indic languages alongside English and 12 common document domains. Additionally, we curate UED-mini, a dataset derived from DocLayNet and M6Doc, to enhance pretraining and provide a solid foundation for Indic layout models. Our experiments demonstrate that fine-tuning existing English models on IndicDLP significantly boosts performance, validating its effectiveness. Moreover, models trained on IndicDLP generalize well beyond Indic layouts, making it a valuable resource for document digitization. This work bridges gaps in scale, diversity, and annotation granularity, driving inclusive and efficient document understanding.
STRinGS: Selective Text Refinement in Gaussian Splatting
Dec 08, 2025Text as signs, labels, or instructions is a critical element of real-world scenes as they can convey important contextual information. 3D representations such as 3D Gaussian Splatting (3DGS) struggle to preserve fine-grained text details, while achieving high visual fidelity. Small errors in textual element reconstruction can lead to significant semantic loss. We propose STRinGS, a text-aware, selective refinement framework to address this issue for 3DGS reconstruction. Our method treats text and non-text regions separately, refining text regions first and merging them with non-text regions later for full-scene optimization. STRinGS produces sharp, readable text even in challenging configurations. We introduce a text readability measure OCR Character Error Rate (CER) to evaluate the efficacy on text regions. STRinGS results in a 63.6% relative improvement over 3DGS at just 7K iterations. We also introduce a curated dataset STRinGS-360 with diverse text scenarios to evaluate text readability in 3D reconstruction. Our method and dataset together push the boundaries of 3D scene understanding in text-rich environments, paving the way for more robust text-aware reconstruction methods.
TexTAR : Textual Attribute Recognition in Multi-domain and Multi-lingual Document Images
Sep 16, 2025Recognizing textual attributes such as bold, italic, underline and strikeout is essential for understanding text semantics, structure, and visual presentation. These attributes highlight key information, making them crucial for document analysis. Existing methods struggle with computational efficiency or adaptability in noisy, multilingual settings. To address this, we introduce TexTAR, a multi-task, context-aware Transformer for Textual Attribute Recognition (TAR). Our novel data selection pipeline enhances context awareness, and our architecture employs a 2D RoPE (Rotary Positional Embedding)-style mechanism to incorporate input context for more accurate attribute predictions. We also introduce MMTAD, a diverse, multilingual, multi-domain dataset annotated with text attributes across real-world documents such as legal records, notices, and textbooks. Extensive evaluations show TexTAR outperforms existing methods, demonstrating that contextual awareness contributes to state-of-the-art TAR performance.
RoadSocial: A Diverse VideoQA Dataset and Benchmark for Road Event Understanding from Social Video Narratives
Mar 27, 2025
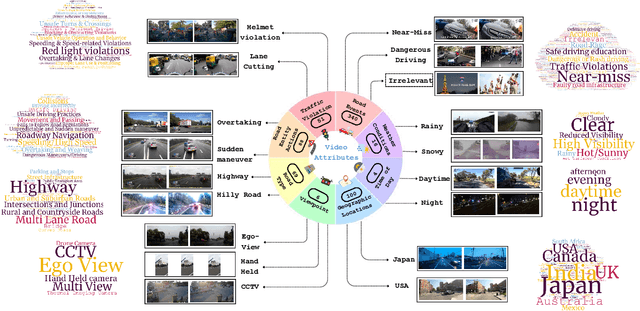
We introduce RoadSocial, a large-scale, diverse VideoQA dataset tailored for generic road event understanding from social media narratives. Unlike existing datasets limited by regional bias, viewpoint bias and expert-driven annotations, RoadSocial captures the global complexity of road events with varied geographies, camera viewpoints (CCTV, handheld, drones) and rich social discourse. Our scalable semi-automatic annotation framework leverages Text LLMs and Video LLMs to generate comprehensive question-answer pairs across 12 challenging QA tasks, pushing the boundaries of road event understanding. RoadSocial is derived from social media videos spanning 14M frames and 414K social comments, resulting in a dataset with 13.2K videos, 674 tags and 260K high-quality QA pairs. We evaluate 18 Video LLMs (open-source and proprietary, driving-specific and general-purpose) on our road event understanding benchmark. We also demonstrate RoadSocial's utility in improving road event understanding capabilities of general-purpose Video LLMs.
CrackUDA: Incremental Unsupervised Domain Adaptation for Improved Crack Segmentation in Civil Structures
Dec 20, 2024Crack segmentation plays a crucial role in ensuring the structural integrity and seismic safety of civil structures. However, existing crack segmentation algorithms encounter challenges in maintaining accuracy with domain shifts across datasets. To address this issue, we propose a novel deep network that employs incremental training with unsupervised domain adaptation (UDA) using adversarial learning, without a significant drop in accuracy in the source domain. Our approach leverages an encoder-decoder architecture, consisting of both domain-invariant and domain-specific parameters. The encoder learns shared crack features across all domains, ensuring robustness to domain variations. Simultaneously, the decoder's domain-specific parameters capture domain-specific features unique to each domain. By combining these components, our model achieves improved crack segmentation performance. Furthermore, we introduce BuildCrack, a new crack dataset comparable to sub-datasets of the well-established CrackSeg9K dataset in terms of image count and crack percentage. We evaluate our proposed approach against state-of-the-art UDA methods using different sub-datasets of CrackSeg9K and our custom dataset. Our experimental results demonstrate a significant improvement in crack segmentation accuracy and generalization across target domains compared to other UDA methods - specifically, an improvement of 0.65 and 2.7 mIoU on source and target domains respectively.
MoRAG -- Multi-Fusion Retrieval Augmented Generation for Human Motion
Sep 18, 2024
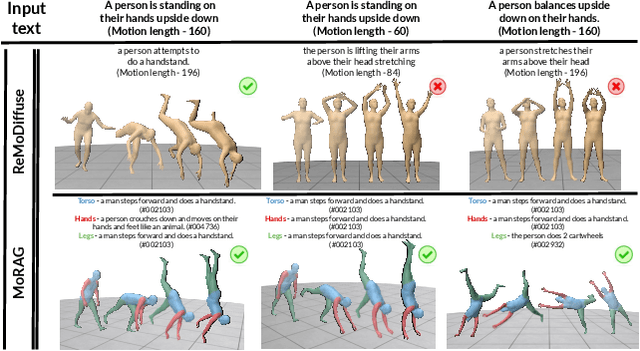
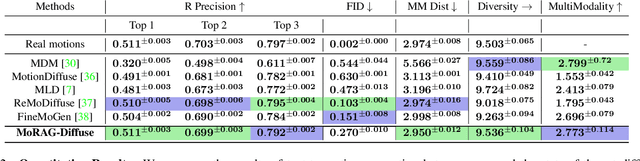
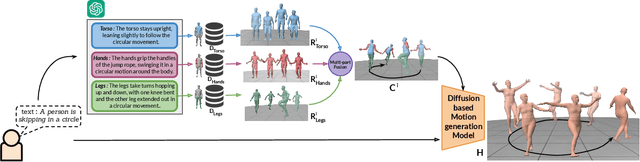
We introduce MoRAG, a novel multi-part fusion based retrieval-augmented generation strategy for text-based human motion generation. The method enhances motion diffusion models by leveraging additional knowledge obtained through an improved motion retrieval process. By effectively prompting large language models (LLMs), we address spelling errors and rephrasing issues in motion retrieval. Our approach utilizes a multi-part retrieval strategy to improve the generalizability of motion retrieval across the language space. We create diverse samples through the spatial composition of the retrieved motions. Furthermore, by utilizing low-level, part-specific motion information, we can construct motion samples for unseen text descriptions. Our experiments demonstrate that our framework can serve as a plug-and-play module, improving the performance of motion diffusion models. Code, pretrained models and sample videos will be made available at: https://motion-rag.github.io/
Transfer-LMR: Heavy-Tail Driving Behavior Recognition in Diverse Traffic Scenarios
May 08, 2024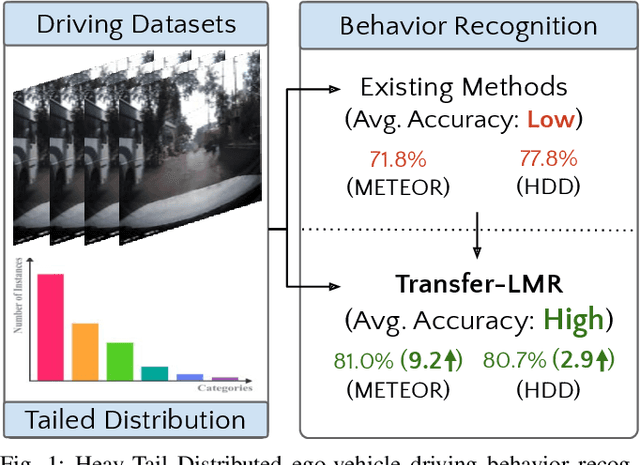
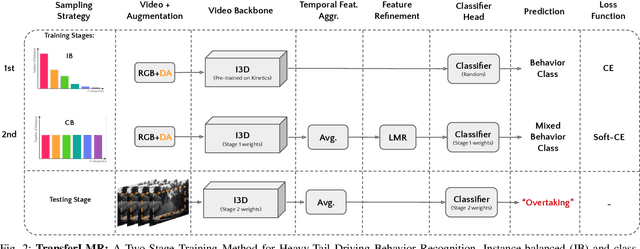
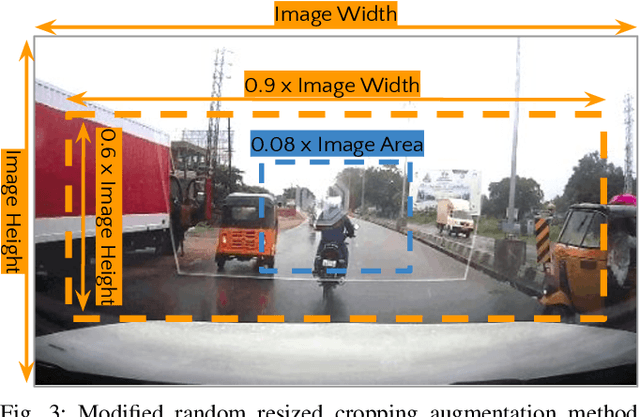

Recognizing driving behaviors is important for downstream tasks such as reasoning, planning, and navigation. Existing video recognition approaches work well for common behaviors (e.g. "drive straight", "brake", "turn left/right"). However, the performance is sub-par for underrepresented/rare behaviors typically found in tail of the behavior class distribution. To address this shortcoming, we propose Transfer-LMR, a modular training routine for improving the recognition performance across all driving behavior classes. We extensively evaluate our approach on METEOR and HDD datasets that contain rich yet heavy-tailed distribution of driving behaviors and span diverse traffic scenarios. The experimental results demonstrate the efficacy of our approach, especially for recognizing underrepresented/rare driving behaviors.