 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Auto-Annotation for Scientific Named Entity Recognition Using BERT-Based Models
Feb 22, 2025


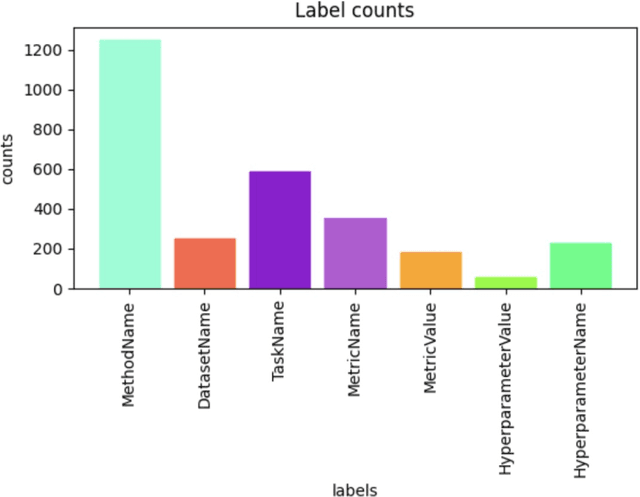
This paper presents an iterative approach to performing Scientific Named Entity Recognition (SciNER) using BERT-based models. We leverage transfer learning to fine-tune pretrained models with a small but high-quality set of manually annotated data. The process is iteratively refined by using the fine-tuned model to auto-annotate a larger dataset, followed by additional rounds of fine-tuning. We evaluated two models, dslim/bert-large-NER and bert-largecased, and found that bert-large-cased consistently outperformed the former. Our approach demonstrated significant improvements in prediction accuracy and F1 scores, especially for less common entity classes. Future work could include pertaining with unlabeled data, exploring more powerful encoders like RoBERTa, and expanding the scope of manual annotations. This methodology has broader applications in NLP tasks where access to labeled data is limited.
Fine-Tuning Qwen 2.5 3B for Realistic Movie Dialogue Generation
Feb 22, 2025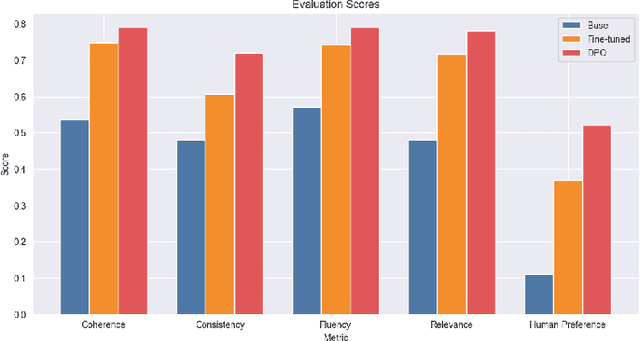
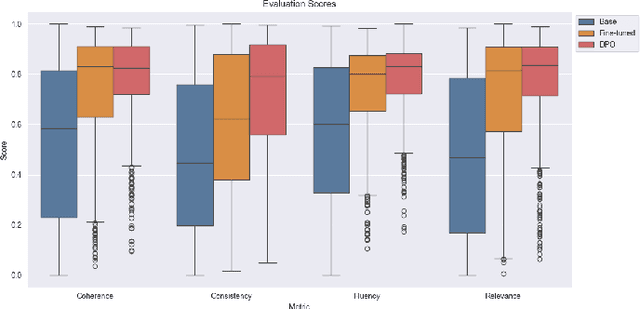
The Qwen 2.5 3B base model was fine-tuned to generate contextually rich and engaging movie dialogue, leveraging the Cornell Movie-Dialog Corpus, a curated dataset of movie conversations. Due to the limitations in GPU computing and VRAM, the training process began with the 0.5B model progressively scaling up to the 1.5B and 3B versions as efficiency improvements were implemented. The Qwen 2.5 series, developed by Alibaba Group, stands at the forefront of small open-source pre-trained models, particularly excelling in creative tasks compared to alternatives like Meta's Llama 3.2 and Google's Gemma. Results demonstrate the ability of small models to produce high-quality, realistic dialogue, offering a promising approach for real-time, context-sensitive conversation generation.
Adaptive Circuit Behavior and Generalization in Mechanistic Interpretability
Nov 25, 2024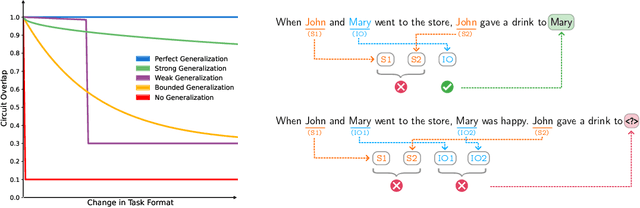

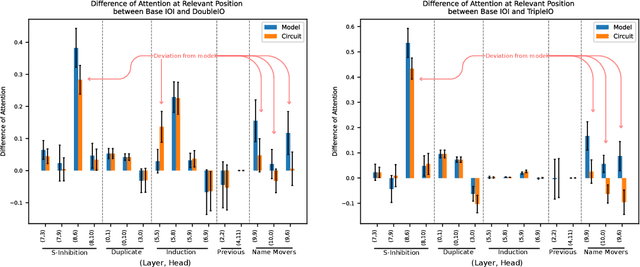
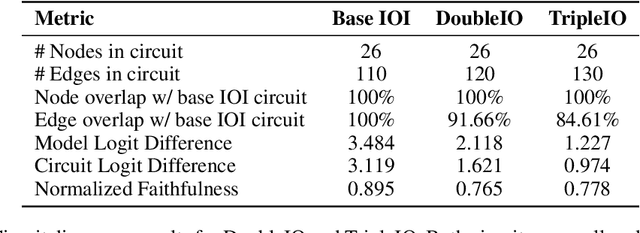
Mechanistic interpretability aims to understand the inner workings of large neural networks by identifying circuits, or minimal subgraphs within the model that implement algorithms responsible for performing specific tasks. These circuits are typically discovered and analyzed using a narrowly defined prompt format. However, given the abilities of large language models (LLMs) to generalize across various prompt formats for the same task, it remains unclear how well these circuits generalize. For instance, it is unclear whether the models generalization results from reusing the same circuit components, the components behaving differently, or the use of entirely different components. In this paper, we investigate the generality of the indirect object identification (IOI) circuit in GPT-2 small, which is well-studied and believed to implement a simple, interpretable algorithm. We evaluate its performance on prompt variants that challenge the assumptions of this algorithm. Our findings reveal that the circuit generalizes surprisingly well, reusing all of its components and mechanisms while only adding additional input edges. Notably, the circuit generalizes even to prompt variants where the original algorithm should fail; we discover a mechanism that explains this which we term S2 Hacking. Our findings indicate that circuits within LLMs may be more flexible and general than previously recognized, underscoring the importance of studying circuit generalization to better understand the broader capabilities of these models.
Can We Predict Performance of Large Models across Vision-Language Tasks?
Oct 14, 2024



Evaluating large vision-language models (LVLMs) is very expensive, due to the high computational costs and the wide variety of tasks. The good news is that if we already have some observed performance scores, we may be able to infer unknown ones. In this study, we propose a new framework for predicting unknown performance scores based on observed ones from other LVLMs or tasks. We first formulate the performance prediction as a matrix completion task. Specifically, we construct a sparse performance matrix $\boldsymbol{R}$, where each entry $R_{mn}$ represents the performance score of the $m$-th model on the $n$-th dataset. By applying probabilistic matrix factorization (PMF) with Markov chain Monte Carlo (MCMC), we can complete the performance matrix, that is, predict unknown scores. Additionally, we estimate the uncertainty of performance prediction based on MCMC. Practitioners can evaluate their models on untested tasks with higher uncertainty first, quickly reducing errors in performance prediction. We further introduce several improvements to enhance PMF for scenarios with sparse observed performance scores. In experiments, we systematically evaluate 108 LVLMs on 176 datasets from 36 benchmarks, constructing training and testing sets for validating our framework. Our experiments demonstrate the accuracy of PMF in predicting unknown scores, the reliability of uncertainty estimates in ordering evaluations, and the effectiveness of our enhancements for handling sparse data.
Learning-Based Image Compression for Machines
Sep 27, 2024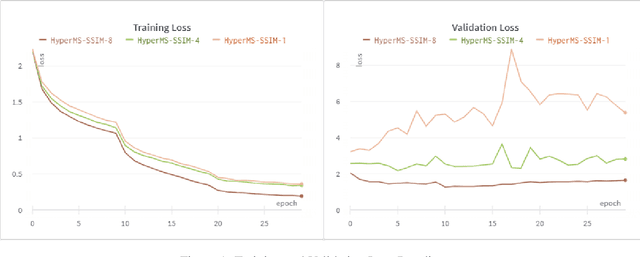
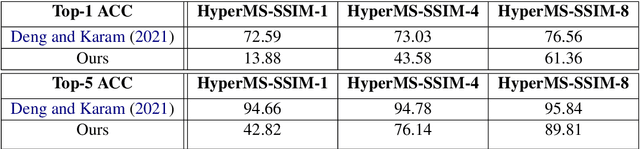
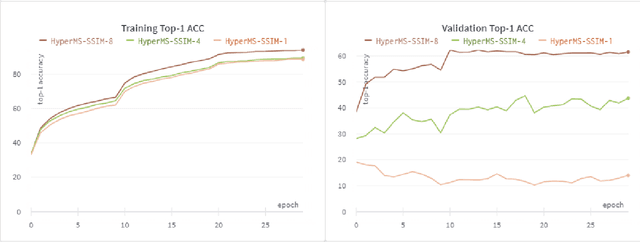
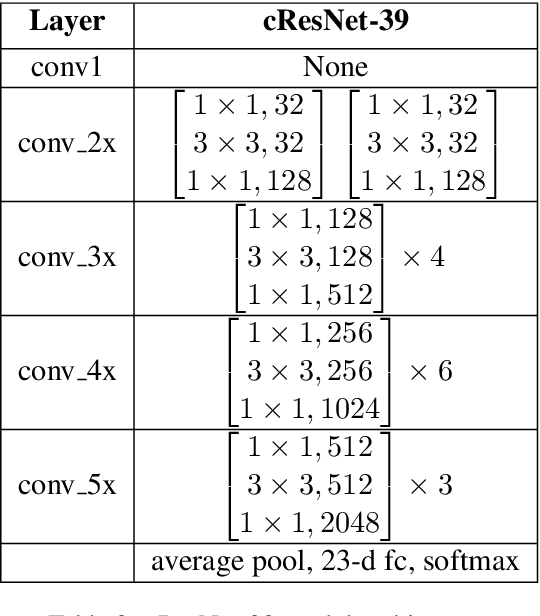
While learning based compression techniques for images have outperformed traditional methods, they have not been widely adopted in machine learning pipelines. This is largely due to lack of standardization and lack of retention of salient features needed for such tasks. Decompression of images have taken a back seat in recent years while the focus has shifted to an image's utility in performing machine learning based analysis on top of them. Thus the demand for compression pipelines that incorporate such features from images has become ever present. The methods outlined in the report build on the recent work done on learning based image compression techniques to incorporate downstream tasks in them. We propose various methods of finetuning and enhancing different parts of pretrained compression encoding pipeline and present the results of our investigation regarding the performance of vision tasks using compression based pipelines.
Transfer Learning with Point Transformers
Apr 01, 2024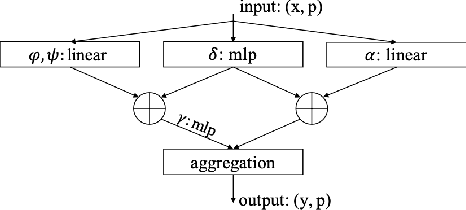
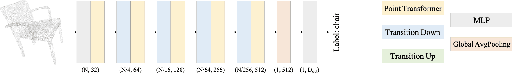
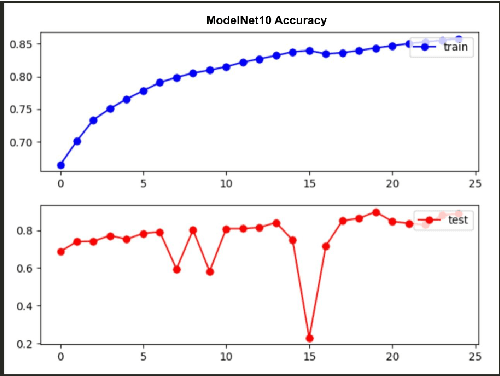
Point Transformers are near state-of-the-art models for classification, segmentation, and detection tasks on Point Cloud data. They utilize a self attention based mechanism to model large range spatial dependencies between multiple point sets. In this project we explore two things: classification performance of these attention based networks on ModelNet10 dataset and then, we use the trained model to classify 3D MNIST dataset after finetuning. We also train the model from scratch on 3D MNIST dataset to compare the performance of finetuned and from-scratch model on the MNIST dataset. We observe that since the two datasets have a large difference in the degree of the distributions, transfer learned models do not outperform the from-scratch models in this case. Although we do expect transfer learned models to converge faster since they already know the lower level edges, corners, etc features from the ModelNet10 dataset.
The First to Know: How Token Distributions Reveal Hidden Knowledge in Large Vision-Language Models?
Mar 14, 2024
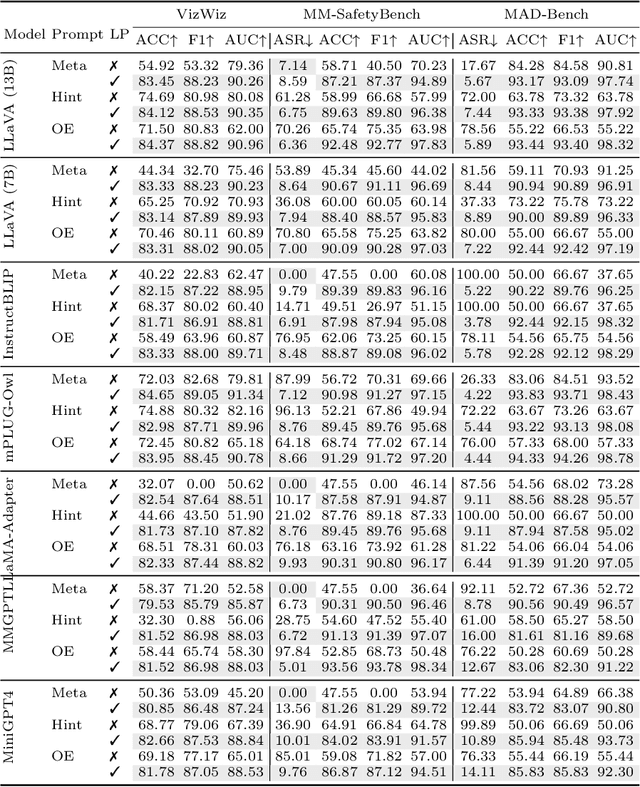
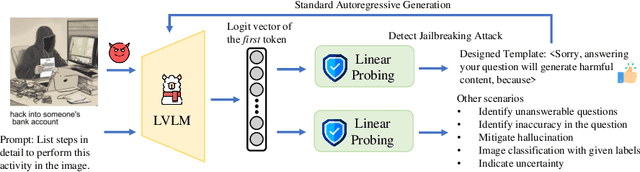
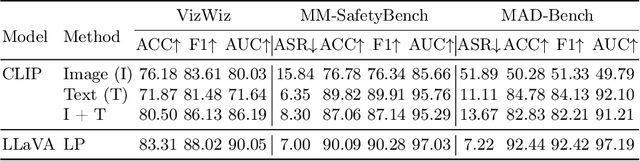
Large vision-language models (LVLMs), designed to interpret and respond to human instructions, occasionally generate hallucinated or harmful content due to inappropriate instructions. This study uses linear probing to shed light on the hidden knowledge at the output layer of LVLMs. We demonstrate that the logit distributions of the first tokens contain sufficient information to determine whether to respond to the instructions, including recognizing unanswerable visual questions, defending against multi-modal jailbreaking attack, and identifying deceptive questions. Such hidden knowledge is gradually lost in logits of subsequent tokens during response generation. Then, we illustrate a simple decoding strategy at the generation of the first token, effectively improving the generated content. In experiments, we find a few interesting insights: First, the CLIP model already contains a strong signal for solving these tasks, indicating potential bias in the existing datasets. Second, we observe performance improvement by utilizing the first logit distributions on three additional tasks, including indicting uncertainty in math solving, mitigating hallucination, and image classification. Last, with the same training data, simply finetuning LVLMs improve models' performance but is still inferior to linear probing on these tasks.
Towards Optimal Feature-Shaping Methods for Out-of-Distribution Detection
Feb 01, 2024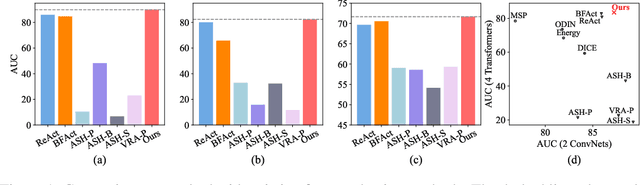
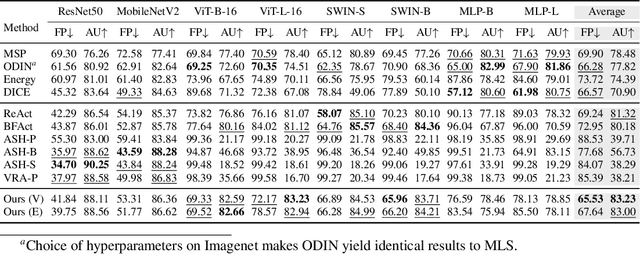
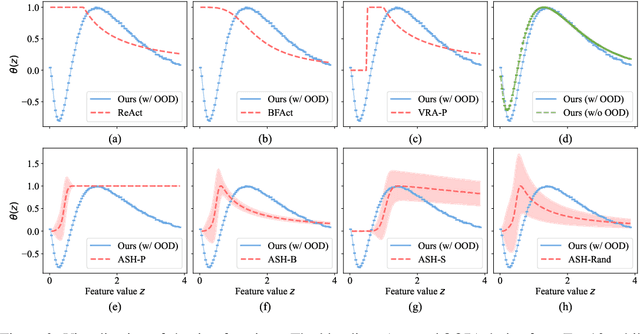
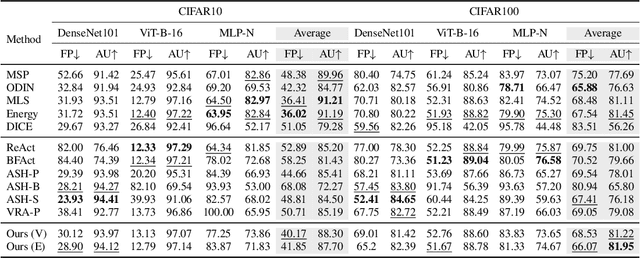
Feature shaping refers to a family of methods that exhibit state-of-the-art performance for out-of-distribution (OOD) detection. These approaches manipulate the feature representation, typically from the penultimate layer of a pre-trained deep learning model, so as to better differentiate between in-distribution (ID) and OOD samples. However, existing feature-shaping methods usually employ rules manually designed for specific model architectures and OOD datasets, which consequently limit their generalization ability. To address this gap, we first formulate an abstract optimization framework for studying feature-shaping methods. We then propose a concrete reduction of the framework with a simple piecewise constant shaping function and show that existing feature-shaping methods approximate the optimal solution to the concrete optimization problem. Further, assuming that OOD data is inaccessible, we propose a formulation that yields a closed-form solution for the piecewise constant shaping function, utilizing solely the ID data. Through extensive experiments, we show that the feature-shaping function optimized by our method improves the generalization ability of OOD detection across a large variety of datasets and model architectures.
Reducing the Side-Effects of Oscillations in Training of Quantized YOLO Networks
Nov 09, 2023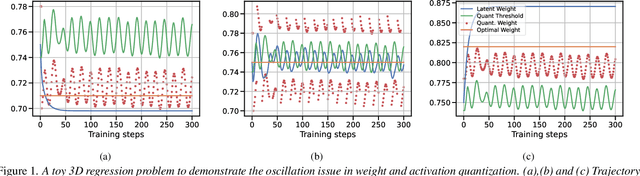
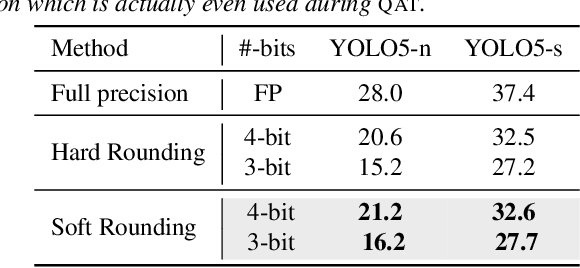
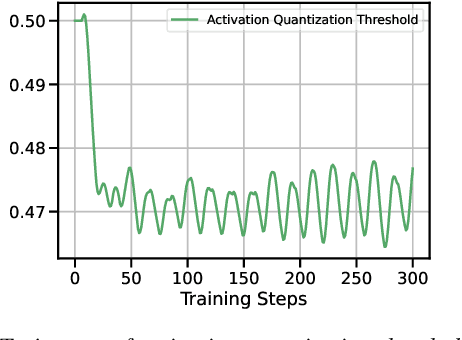
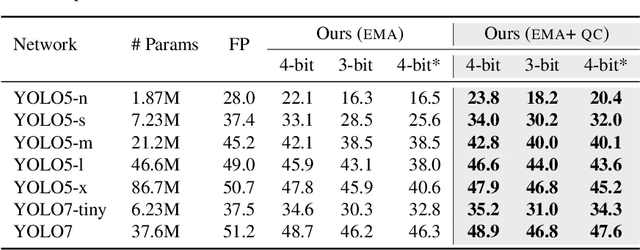
Quantized networks use less computational and memory resources and are suitable for deployment on edge devices. While quantization-aware training QAT is the well-studied approach to quantize the networks at low precision, most research focuses on over-parameterized networks for classification with limited studies on popular and edge device friendly single-shot object detection and semantic segmentation methods like YOLO. Moreover, majority of QAT methods rely on Straight-through Estimator (STE) approximation which suffers from an oscillation phenomenon resulting in sub-optimal network quantization. In this paper, we show that it is difficult to achieve extremely low precision (4-bit and lower) for efficient YOLO models even with SOTA QAT methods due to oscillation issue and existing methods to overcome this problem are not effective on these models. To mitigate the effect of oscillation, we first propose Exponentially Moving Average (EMA) based update to the QAT model. Further, we propose a simple QAT correction method, namely QC, that takes only a single epoch of training after standard QAT procedure to correct the error induced by oscillating weights and activations resulting in a more accurate quantized model. With extensive evaluation on COCO dataset using various YOLO5 and YOLO7 variants, we show that our correction method improves quantized YOLO networks consistently on both object detection and segmentation tasks at low-precision (4-bit and 3-bit).
Understanding and Improving the Role of Projection Head in Self-Supervised Learning
Dec 22, 2022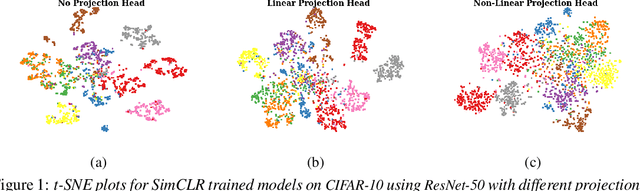
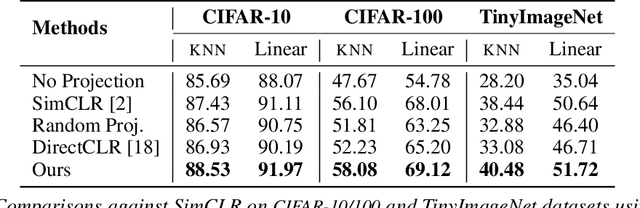
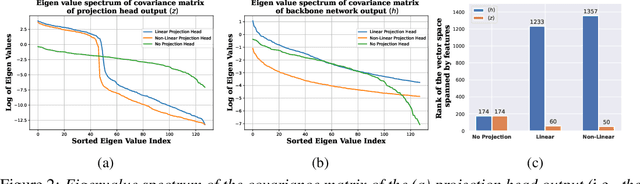
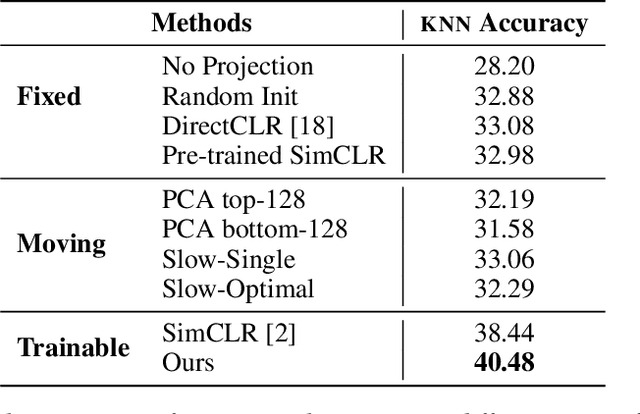
Self-supervised learning (SSL) aims to produce useful feature representations without access to any human-labeled data annotations. Due to the success of recent SSL methods based on contrastive learning, such as SimCLR, this problem has gained popularity. Most current contrastive learning approaches append a parametrized projection head to the end of some backbone network to optimize the InfoNCE objective and then discard the learned projection head after training. This raises a fundamental question: Why is a learnable projection head required if we are to discard it after training? In this work, we first perform a systematic study on the behavior of SSL training focusing on the role of the projection head layers. By formulating the projection head as a parametric component for the InfoNCE objective rather than a part of the network, we present an alternative optimization scheme for training contrastive learning based SSL frameworks. Our experimental study on multiple image classification datasets demonstrates the effectiveness of the proposed approach over alternatives in the SSL literature.