 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncMesh: Fully Asynchronous Optimization for Data and Pipeline Parallelism
Jan 30, 2026Data and pipeline parallelism are key strategies for scaling neural network training across distributed devices, but their high communication cost necessitates co-located computing clusters with fast interconnects, limiting their scalability. We address this communication bottleneck by introducing asynchronous updates across both parallelism axes, relaxing the co-location requirement at the expense of introducing staleness between pipeline stages and data parallel replicas. To mitigate staleness, for pipeline parallelism, we adopt a weight look-ahead approach, and for data parallelism, we introduce an asynchronous sparse averaging method equipped with an exponential moving average based correction mechanism. We provide convergence guarantees for both sparse averaging and asynchronous updates. Experiments on large-scale language models (up to \em 1B parameters) demonstrate that our approach matches the performance of the fully synchronous baseline, while significantly reducing communication overhead.
Sharper Convergence Rates for Nonconvex Optimisation via Reduction Mappings
Jun 10, 2025



Many high-dimensional optimisation problems exhibit rich geometric structures in their set of minimisers, often forming smooth manifolds due to over-parametrisation or symmetries. When this structure is known, at least locally, it can be exploited through reduction mappings that reparametrise part of the parameter space to lie on the solution manifold. These reductions naturally arise from inner optimisation problems and effectively remove redundant directions, yielding a lower-dimensional objective. In this work, we introduce a general framework to understand how such reductions influence the optimisation landscape. We show that well-designed reduction mappings improve curvature properties of the objective, leading to better-conditioned problems and theoretically faster convergence for gradient-based methods. Our analysis unifies a range of scenarios where structural information at optimality is leveraged to accelerate convergence, offering a principled explanation for the empirical gains observed in such optimisation algorithms.
Nesterov Method for Asynchronous Pipeline Parallel Optimization
May 02, 2025Pipeline Parallelism (PP) enables large neural network training on small, interconnected devices by splitting the model into multiple stages. To maximize pipeline utilization, asynchronous optimization is appealing as it offers 100% pipeline utilization by construction. However, it is inherently challenging as the weights and gradients are no longer synchronized, leading to stale (or delayed) gradients. To alleviate this, we introduce a variant of Nesterov Accelerated Gradient (NAG) for asynchronous optimization in PP. Specifically, we modify the look-ahead step in NAG to effectively address the staleness in gradients. We theoretically prove that our approach converges at a sublinear rate in the presence of fixed delay in gradients. Our experiments on large-scale language modelling tasks using decoder-only architectures with up to 1B parameters, demonstrate that our approach significantly outperforms existing asynchronous methods, even surpassing the synchronous baseline.
Learning Visual Hierarchies with Hyperbolic Embeddings
Nov 26, 2024Structuring latent representations in a hierarchical manner enables models to learn patterns at multiple levels of abstraction. However, most prevalent image understanding models focus on visual similarity, and learning visual hierarchies is relatively unexplored. In this work, for the first time, we introduce a learning paradigm that can encode user-defined multi-level visual hierarchies in hyperbolic space without requiring explicit hierarchical labels. As a concrete example, first, we define a part-based image hierarchy using object-level annotations within and across images. Then, we introduce an approach to enforce the hierarchy using contrastive loss with pairwise entailment metrics. Finally, we discuss new evaluation metrics to effectively measure hierarchical image retrieval. Encoding these complex relationships ensures that the learned representations capture semantic and structural information that transcends mere visual similarity. Experiments in part-based image retrieval show significant improvements in hierarchical retrieval tasks, demonstrating the capability of our model in capturing visual hierarchies.
Guiding Neural Collapse: Optimising Towards the Nearest Simplex Equiangular Tight Frame
Nov 02, 2024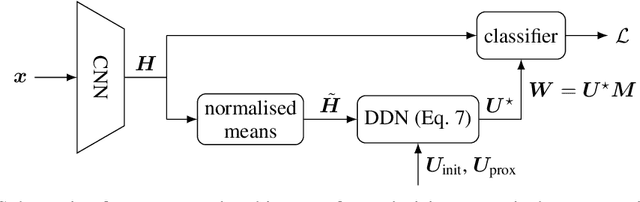
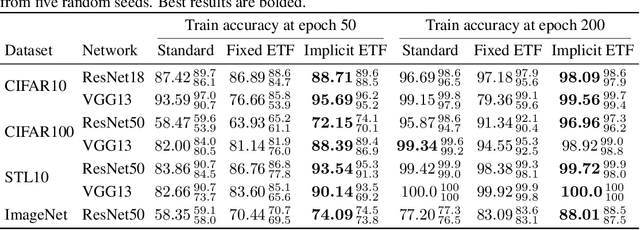
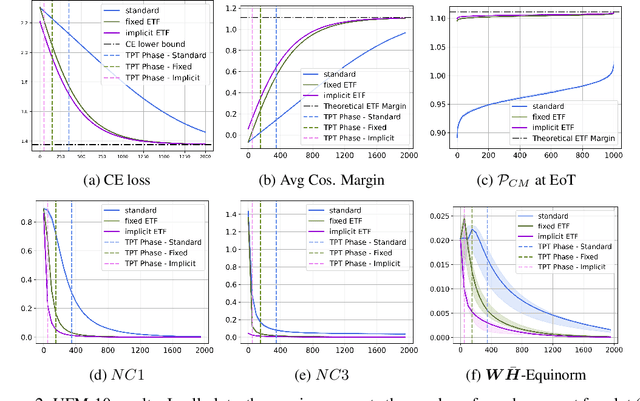
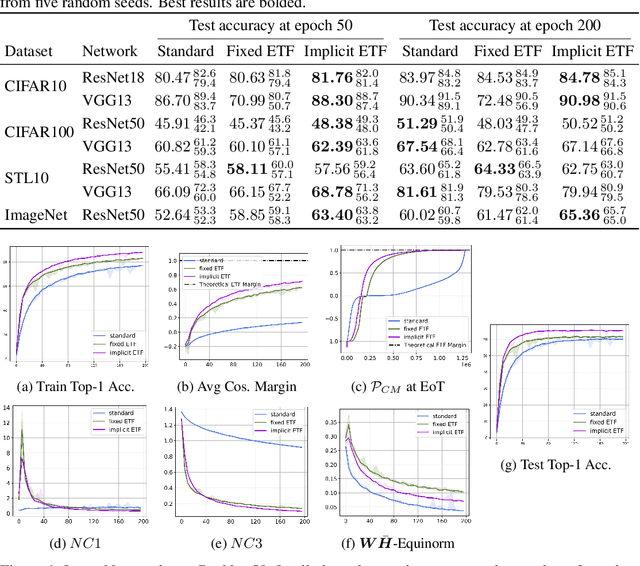
Neural Collapse (NC) is a recently observed phenomenon in neural networks that characterises the solution space of the final classifier layer when trained until zero training loss. Specifically, NC suggests that the final classifier layer converges to a Simplex Equiangular Tight Frame (ETF), which maximally separates the weights corresponding to each class. By duality, the penultimate layer feature means also converge to the same simplex ETF. Since this simple symmetric structure is optimal, our idea is to utilise this property to improve convergence speed. Specifically, we introduce the notion of nearest simplex ETF geometry for the penultimate layer features at any given training iteration, by formulating it as a Riemannian optimisation. Then, at each iteration, the classifier weights are implicitly set to the nearest simplex ETF by solving this inner-optimisation, which is encapsulated within a declarative node to allow backpropagation. Our experiments on synthetic and real-world architectures for classification tasks demonstrate that our approach accelerates convergence and enhances training stability.
Self-Supervision Improves Diffusion Models for Tabular Data Imputation
Jul 25, 2024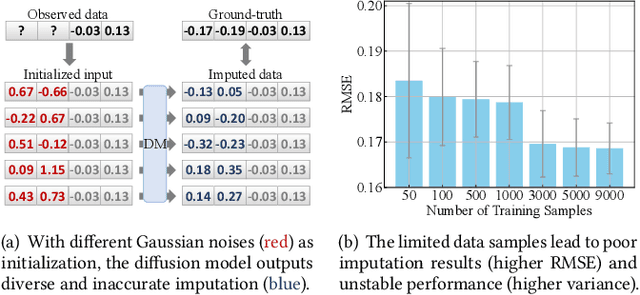
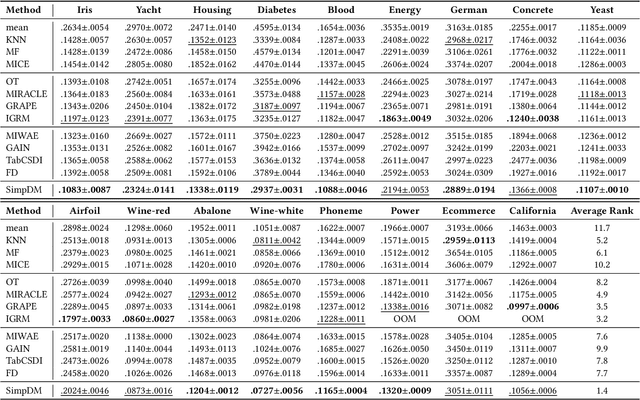
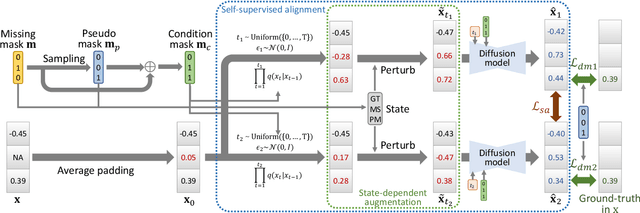
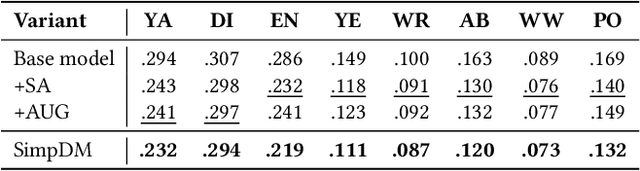
The ubiquity of missing data has sparked considerable attention and focus on tabular data imputation methods. Diffusion models, recognized as the cutting-edge technique for data generation, demonstrate significant potential in tabular data imputation tasks. However, in pursuit of diversity, vanilla diffusion models often exhibit sensitivity to initialized noises, which hinders the models from generating stable and accurate imputation results. Additionally, the sparsity inherent in tabular data poses challenges for diffusion models in accurately modeling the data manifold, impacting the robustness of these models for data imputation. To tackle these challenges, this paper introduces an advanced diffusion model named Self-supervised imputation Diffusion Model (SimpDM for brevity), specifically tailored for tabular data imputation tasks. To mitigate sensitivity to noise, we introduce a self-supervised alignment mechanism that aims to regularize the model, ensuring consistent and stable imputation predictions. Furthermore, we introduce a carefully devised state-dependent data augmentation strategy within SimpDM, enhancing the robustness of the diffusion model when dealing with limited data. Extensive experiments demonstrate that SimpDM matches or outperforms state-of-the-art imputation methods across various scenarios.
Adaptive Cross Batch Normalization for Metric Learning
Mar 30, 2023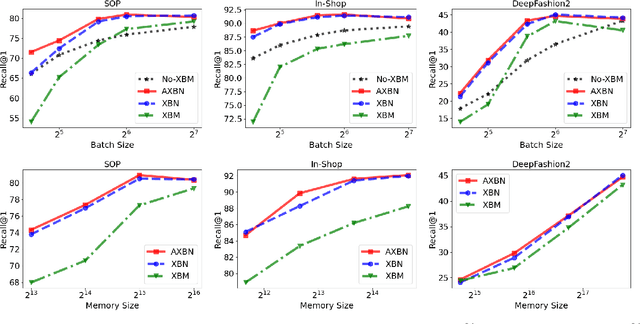
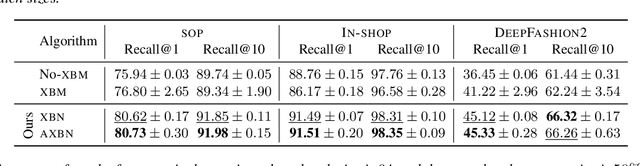


Metric learning is a fundamental problem in computer vision whereby a model is trained to learn a semantically useful embedding space via ranking losses. Traditionally, the effectiveness of a ranking loss depends on the minibatch size, and is, therefore, inherently limited by the memory constraints of the underlying hardware. While simply accumulating the embeddings across minibatches has proved useful (Wang et al. [2020]), we show that it is equally important to ensure that the accumulated embeddings are up to date. In particular, it is necessary to circumvent the representational drift between the accumulated embeddings and the feature embeddings at the current training iteration as the learnable parameters are being updated. In this paper, we model representational drift as distribution misalignment and tackle it using moment matching. The result is a simple method for updating the stored embeddings to match the first and second moments of the current embeddings at each training iteration. Experiments on three popular image retrieval datasets, namely, SOP, In-Shop, and DeepFashion2, demonstrate that our approach significantly improves the performance in all scenarios.
Understanding and Improving the Role of Projection Head in Self-Supervised Learning
Dec 22, 2022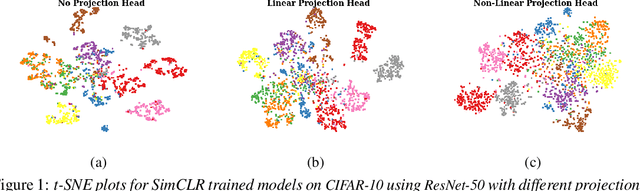
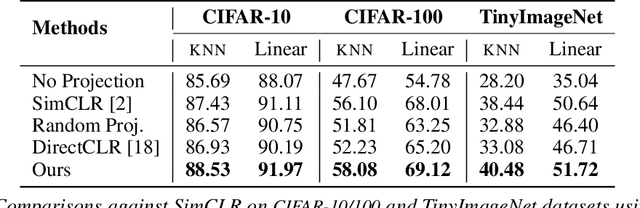
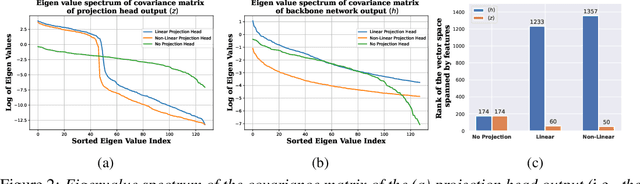
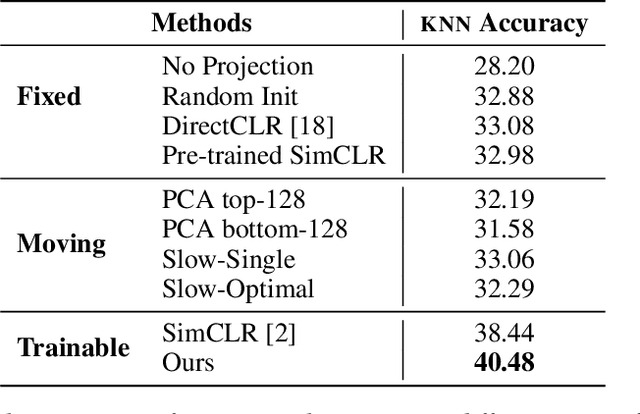
Self-supervised learning (SSL) aims to produce useful feature representations without access to any human-labeled data annotations. Due to the success of recent SSL methods based on contrastive learning, such as SimCLR, this problem has gained popularity. Most current contrastive learning approaches append a parametrized projection head to the end of some backbone network to optimize the InfoNCE objective and then discard the learned projection head after training. This raises a fundamental question: Why is a learnable projection head required if we are to discard it after training? In this work, we first perform a systematic study on the behavior of SSL training focusing on the role of the projection head layers. By formulating the projection head as a parametric component for the InfoNCE objective rather than a part of the network, we present an alternative optimization scheme for training contrastive learning based SSL frameworks. Our experimental study on multiple image classification datasets demonstrates the effectiveness of the proposed approach over alternatives in the SSL literature.
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022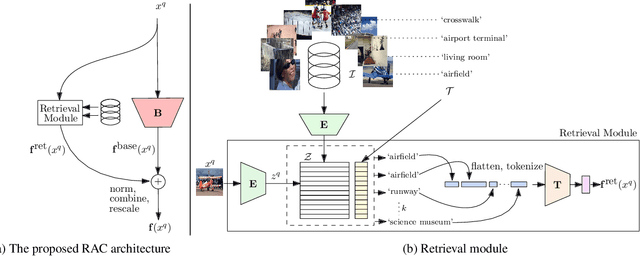
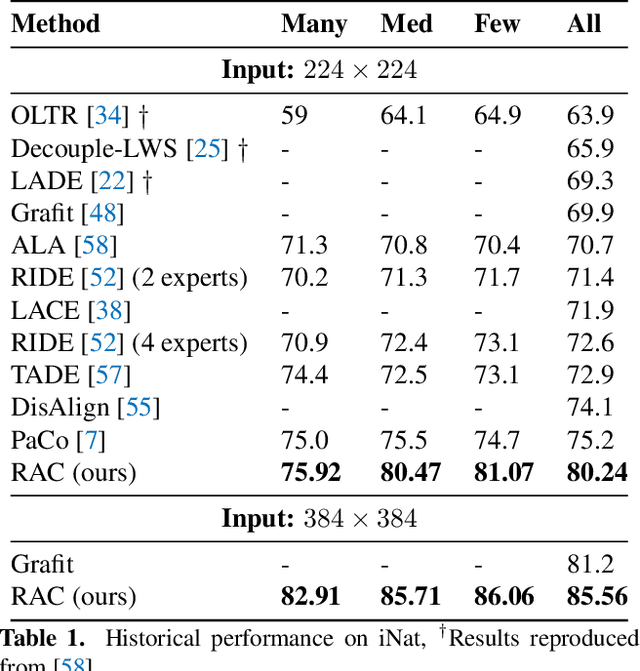
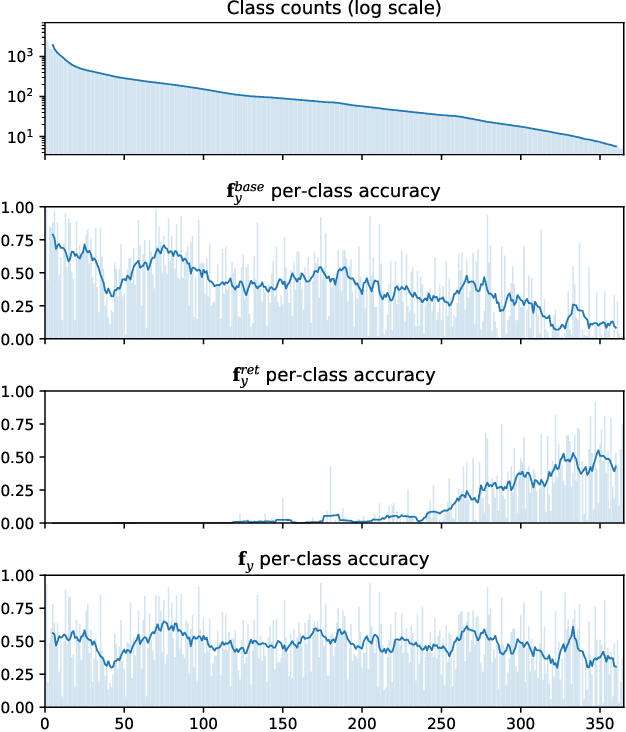
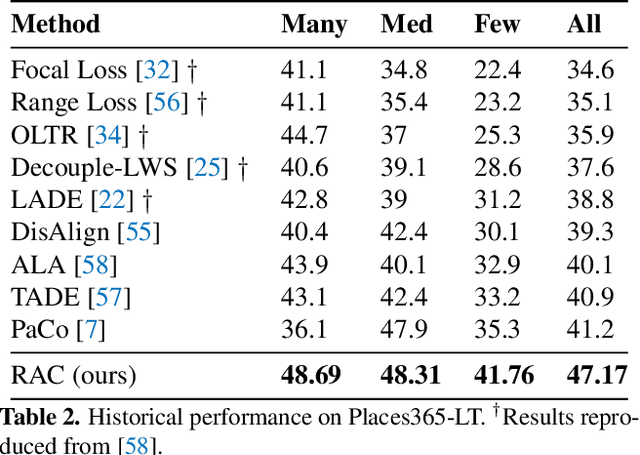
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
Few-shot Weakly-Supervised Object Detection via Directional Statistics
Mar 25, 2021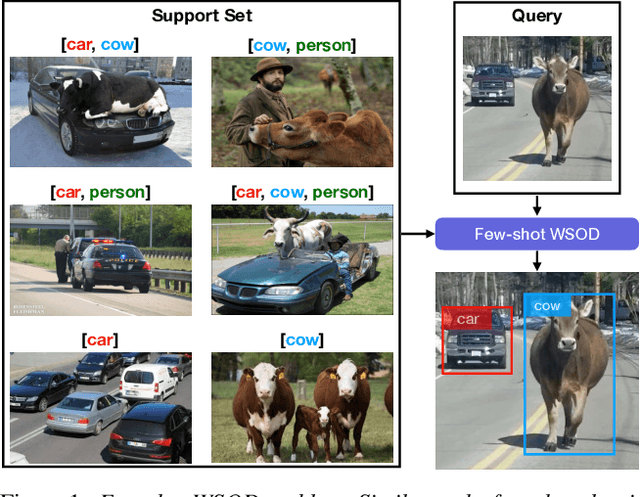
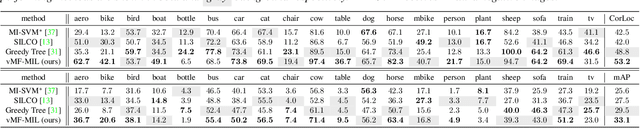
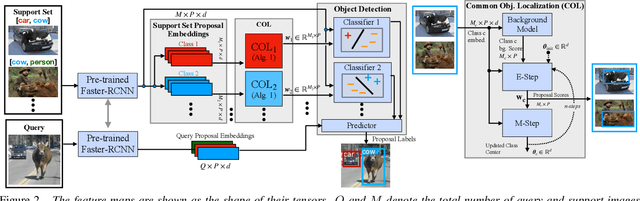

Detecting novel objects from few examples has become an emerging topic in computer vision recently. However, these methods need fully annotated training images to learn new object categories which limits their applicability in real world scenarios such as field robotics. In this work, we propose a probabilistic multiple instance learning approach for few-shot Common Object Localization (COL) and few-shot Weakly Supervised Object Detection (WSOD). In these tasks, only image-level labels, which are much cheaper to acquire, are available. We find that operating on features extracted from the last layer of a pre-trained Faster-RCNN is more effective compared to previous episodic learning based few-shot COL methods. Our model simultaneously learns the distribution of the novel objects and localizes them via expectation-maximization steps. As a probabilistic model, we employ von Mises-Fisher (vMF) distribution which captures the semantic information better than Gaussian distribution when applied to the pre-trained embedding space. When the novel objects are localized, we utilize them to learn a linear appearance model to detect novel classes in new images. Our extensive experiments show that the proposed method, despite being simple, outperforms strong baselines in few-shot COL and WSOD, as well as large-scale WSOD tasks.