 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVENTURA: Adapting Image Diffusion Models for Unified Task Conditioned Navigation
Oct 01, 2025Robots must adapt to diverse human instructions and operate safely in unstructured, open-world environments. Recent Vision-Language models (VLMs) offer strong priors for grounding language and perception, but remain difficult to steer for navigation due to differences in action spaces and pretraining objectives that hamper transferability to robotics tasks. Towards addressing this, we introduce VENTURA, a vision-language navigation system that finetunes internet-pretrained image diffusion models for path planning. Instead of directly predicting low-level actions, VENTURA generates a path mask (i.e. a visual plan) in image space that captures fine-grained, context-aware navigation behaviors. A lightweight behavior-cloning policy grounds these visual plans into executable trajectories, yielding an interface that follows natural language instructions to generate diverse robot behaviors. To scale training, we supervise on path masks derived from self-supervised tracking models paired with VLM-augmented captions, avoiding manual pixel-level annotation or highly engineered data collection setups. In extensive real-world evaluations, VENTURA outperforms state-of-the-art foundation model baselines on object reaching, obstacle avoidance, and terrain preference tasks, improving success rates by 33% and reducing collisions by 54% across both seen and unseen scenarios. Notably, we find that VENTURA generalizes to unseen combinations of distinct tasks, revealing emergent compositional capabilities. Videos, code, and additional materials: https://venturapath.github.io
VIBES -- Vision Backbone Efficient Selection
Oct 11, 2024



This work tackles the challenge of efficiently selecting high-performance pre-trained vision backbones for specific target tasks. Although exhaustive search within a finite set of backbones can solve this problem, it becomes impractical for large datasets and backbone pools. To address this, we introduce Vision Backbone Efficient Selection (VIBES), which aims to quickly find well-suited backbones, potentially trading off optimality for efficiency. We propose several simple yet effective heuristics to address VIBES and evaluate them across four diverse computer vision datasets. Our results show that these approaches can identify backbones that outperform those selected from generic benchmarks, even within a limited search budget of one hour on a single GPU. We reckon VIBES marks a paradigm shift from benchmarks to task-specific optimization.
LiDAR-UDA: Self-ensembling Through Time for Unsupervised LiDAR Domain Adaptation
Sep 24, 2023We introduce LiDAR-UDA, a novel two-stage self-training-based Unsupervised Domain Adaptation (UDA) method for LiDAR segmentation. Existing self-training methods use a model trained on labeled source data to generate pseudo labels for target data and refine the predictions via fine-tuning the network on the pseudo labels. These methods suffer from domain shifts caused by different LiDAR sensor configurations in the source and target domains. We propose two techniques to reduce sensor discrepancy and improve pseudo label quality: 1) LiDAR beam subsampling, which simulates different LiDAR scanning patterns by randomly dropping beams; 2) cross-frame ensembling, which exploits temporal consistency of consecutive frames to generate more reliable pseudo labels. Our method is simple, generalizable, and does not incur any extra inference cost. We evaluate our method on several public LiDAR datasets and show that it outperforms the state-of-the-art methods by more than $3.9\%$ mIoU on average for all scenarios. Code will be available at https://github.com/JHLee0513/LiDARUDA.
TerrainNet: Visual Modeling of Complex Terrain for High-speed, Off-road Navigation
Mar 28, 2023



Effective use of camera-based vision systems is essential for robust performance in autonomous off-road driving, particularly in the high-speed regime. Despite success in structured, on-road settings, current end-to-end approaches for scene prediction have yet to be successfully adapted for complex outdoor terrain. To this end, we present TerrainNet, a vision-based terrain perception system for semantic and geometric terrain prediction for aggressive, off-road navigation. The approach relies on several key insights and practical considerations for achieving reliable terrain modeling. The network includes a multi-headed output representation to capture fine- and coarse-grained terrain features necessary for estimating traversability. Accurate depth estimation is achieved using self-supervised depth completion with multi-view RGB and stereo inputs. Requirements for real-time performance and fast inference speeds are met using efficient, learned image feature projections. Furthermore, the model is trained on a large-scale, real-world off-road dataset collected across a variety of diverse outdoor environments. We show how TerrainNet can also be used for costmap prediction and provide a detailed framework for integration into a planning module. We demonstrate the performance of TerrainNet through extensive comparison to current state-of-the-art baselines for camera-only scene prediction. Finally, we showcase the effectiveness of integrating TerrainNet within a complete autonomous-driving stack by conducting a real-world vehicle test in a challenging off-road scenario.
Few-shot Weakly-Supervised Object Detection via Directional Statistics
Mar 25, 2021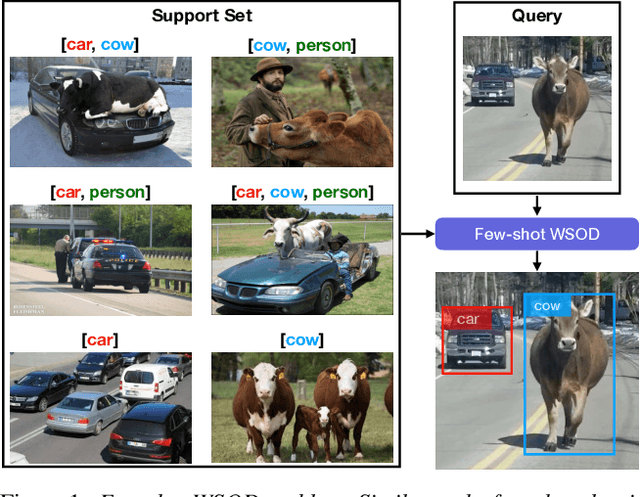
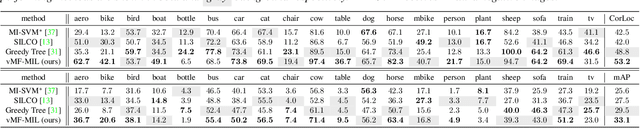
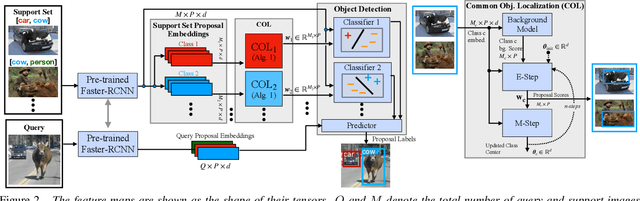

Detecting novel objects from few examples has become an emerging topic in computer vision recently. However, these methods need fully annotated training images to learn new object categories which limits their applicability in real world scenarios such as field robotics. In this work, we propose a probabilistic multiple instance learning approach for few-shot Common Object Localization (COL) and few-shot Weakly Supervised Object Detection (WSOD). In these tasks, only image-level labels, which are much cheaper to acquire, are available. We find that operating on features extracted from the last layer of a pre-trained Faster-RCNN is more effective compared to previous episodic learning based few-shot COL methods. Our model simultaneously learns the distribution of the novel objects and localizes them via expectation-maximization steps. As a probabilistic model, we employ von Mises-Fisher (vMF) distribution which captures the semantic information better than Gaussian distribution when applied to the pre-trained embedding space. When the novel objects are localized, we utilize them to learn a linear appearance model to detect novel classes in new images. Our extensive experiments show that the proposed method, despite being simple, outperforms strong baselines in few-shot COL and WSOD, as well as large-scale WSOD tasks.
A Robotic 3D Perception System for Operating Room Environment Awareness
Mar 30, 2020

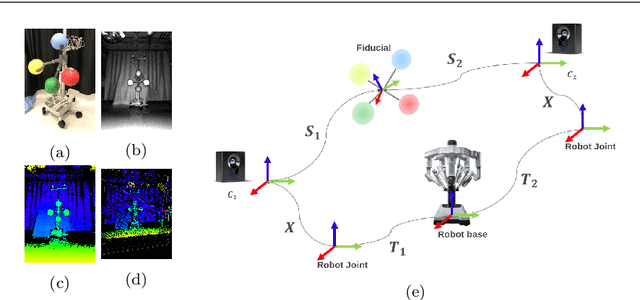

Purpose: We describe a 3D multi-view perception system for the da Vinci surgical system to enable Operating room (OR) scene understanding and context awareness. Methods: Our proposed system is comprised of four Time-of-Flight (ToF) cameras rigidly attached to strategic locations on the daVinci Xi patient side cart (PSC). The cameras are registered to the robot's kinematic chain by performing a one-time calibration routine and therefore, information from all cameras can be fused and represented in one common coordinate frame. Based on this architecture, a multi-view 3D scene semantic segmentation algorithm is created to enable recognition of common and salient objects/equipment and surgical activities in a da Vinci OR. Our proposed 3D semantic segmentation method has been trained and validated on a novel densely annotated dataset that has been captured from clinical scenarios. Results: The results show that our proposed architecture has acceptable registration error ($3.3\%\pm1.4\%$ of object-camera distance) and can robustly improve scene segmentation performance (mean Intersection Over Union - mIOU) for less frequently appearing classes ($\ge 0.013$) compared to a single-view method. Conclusion: We present the first dynamic multi-view perception system with a novel segmentation architecture, which can be used as a building block technology for applications such as surgical workflow analysis, automation of surgical sub-tasks and advanced guidance systems.
In Defense of Graph Inference Algorithms for Weakly Supervised Object Localization
Mar 18, 2020
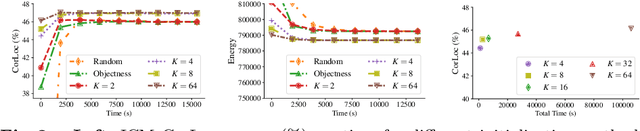


Weakly Supervised Object Localization (WSOL) methods have become increasingly popular since they only require image level labels as opposed to expensive bounding box annotations required by fully supervised algorithms. Typically, a WSOL model is first trained to predict class generic objectness scores on an off-the-shelf fully supervised source dataset and then it is progressively adapted to learn the objects in the weakly supervised target dataset. In this work, we argue that learning only an objectness function is a weak form of knowledge transfer and propose to learn a classwise pairwise similarity function that directly compares two input proposals as well. The combined localization model and the estimated object annotations are jointly learned in an alternating optimization paradigm as is typically done in standard WSOL methods. In contrast to the existing work that learns pairwise similarities, our proposed approach optimizes a unified objective with convergence guarantee and it is computationally efficient for large-scale applications. Experiments on the COCO and ILSVRC 2013 detection datasets show that the performance of the localization model improves significantly with the inclusion of pairwise similarity function. For instance, in the ILSVRC dataset, the Correct Localization (CorLoc) performance improves from 72.7% to 78.2% which is a new state-of-the-art for weakly supervised object localization task.
Intra Order-preserving Functions for Calibration of Multi-Class Neural Networks
Mar 15, 2020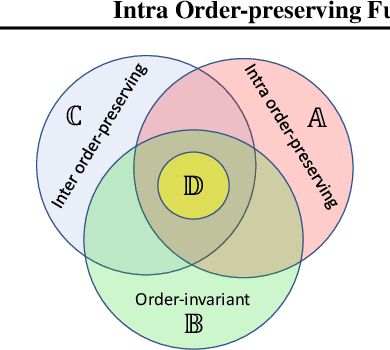

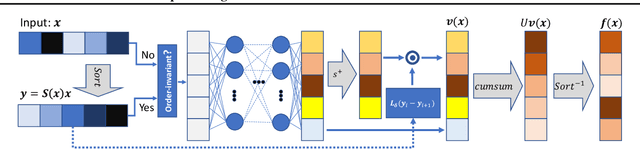

Predicting calibrated confidence scores for multi-class deep networks is important for avoiding rare but costly mistakes. A common approach is to learn a post-hoc calibration function that transforms the output of the original network into calibrated confidence scores while maintaining the network's accuracy. However, previous post-hoc calibration techniques work only with simple calibration functions, potentially lacking sufficient representation to calibrate the complex function landscape of deep networks. In this work, we aim to learn general post-hoc calibration functions that can preserve the top-k predictions of any deep network. We call this family of functions intra order-preserving functions. We propose a new neural network architecture that represents a class of intra order-preserving functions by combining common neural network components. Additionally, we introduce order-invariant and diagonal sub-families, which can act as regularization for better generalization when the training data size is small. We show the effectiveness of the proposed method across a wide range of datasets and classifiers. Our method outperforms state-of-the-art post-hoc calibration methods, namely temperature scaling and Dirichlet calibration, in multiple settings.
MMTM: Multimodal Transfer Module for CNN Fusion
Nov 20, 2019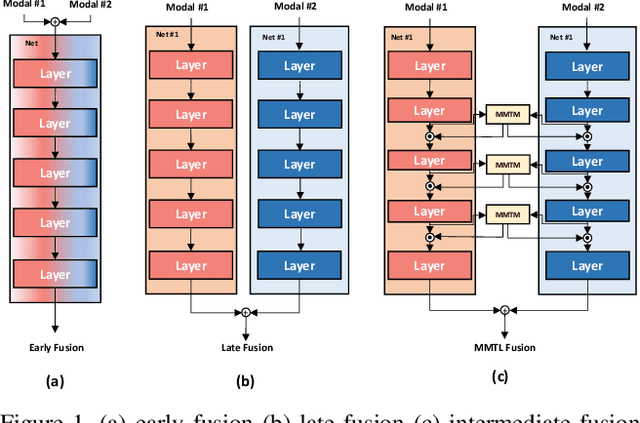

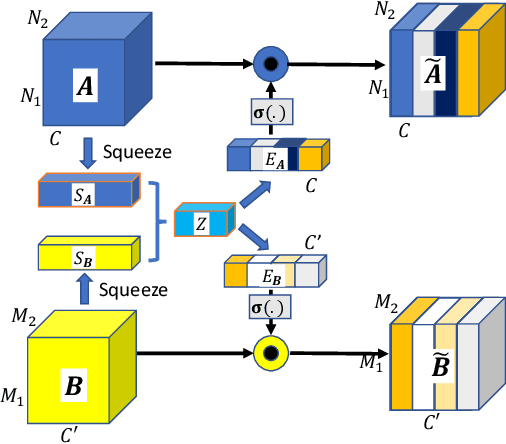
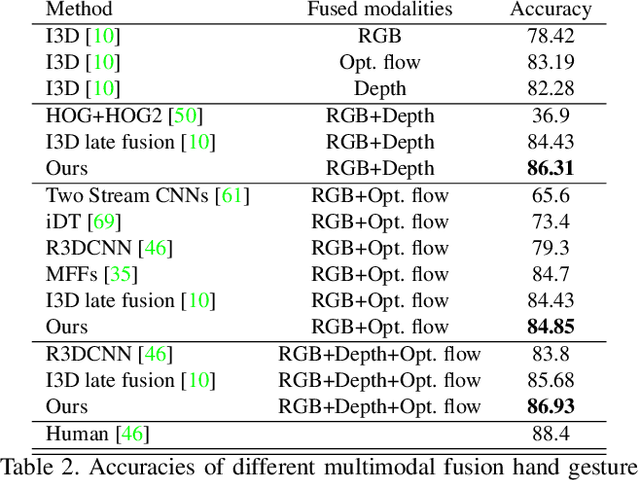
In late fusion, each modality is processed in a separate unimodal Convolutional Neural Network (CNN) stream and the scores of each modality are fused at the end. Due to its simplicity late fusion is still the predominant approach in many state-of-the-art multimodal applications. In this paper, we present a simple neural network module for leveraging the knowledge from multiple modalities in convolutional neural networks. The propose unit, named Multimodal Transfer Module (MMTM), can be added at different levels of the feature hierarchy, enabling slow modality fusion. Using squeeze and excitation operations, MMTM utilizes the knowledge of multiple modalities to recalibrate the channel-wise features in each CNN stream. Despite other intermediate fusion methods, the proposed module could be used for feature modality fusion in convolution layers with different spatial dimensions. Another advantage of the proposed method is that it could be added among unimodal branches with minimum changes in the their network architectures, allowing each branch to be initialized with existing pretrained weights. Experimental results show that our framework improves the recognition accuracy of well-known multimodal networks. We demonstrate state-of-the-art or competitive performance on four datasets that span the task domains of dynamic hand gesture recognition, speech enhancement, and action recognition with RGB and body joints.
Learning to Find Common Objects Across Image Collections
Apr 29, 2019

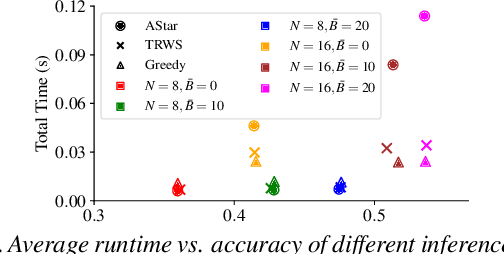
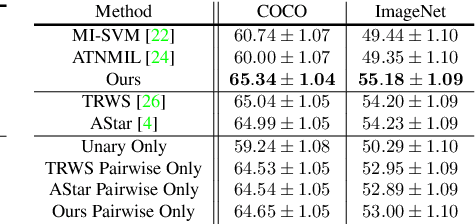
We address the problem of finding a set of images containing a common, but unknown, object category from a collection of image proposals. Our formulation assumes that we are given a collection of bags where each bag is a set of image proposals. Our goal is to select one image from each bag such that the selected images are of the same object category. We model the selection as an energy minimization problem with unary and pairwise potential functions. Inspired by recent few-shot learning algorithms, we propose an approach to learn the potential functions directly from the data. Furthermore, we propose a fast and simple greedy inference algorithm for energy minimization. We evaluate our approach on few-shot common object recognition and object co-localization tasks. Our experiments show that learning the pairwise and unary terms greatly improves the performance of the model over several well-known methods for these tasks. The proposed greedy optimization algorithm achieves performance comparable to state-of-the-art structured inference algorithms while being ~10 times faster. The code is publicly available on https://github.com/haamoon/finding_common_object.