 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Through Smoke: Surgical Desmoking for Improved Visual Perception
Mar 26, 2026Minimally invasive and robot-assisted surgery relies heavily on endoscopic imaging, yet surgical smoke produced by electrocautery and vessel-sealing instruments can severely degrade visual perception and hinder vision-based functionalities. We present a transformer-based surgical desmoking model with a physics-inspired desmoking head that jointly predicts smoke-free image and corresponding smoke map. To address the scarcity of paired smoky-to-smoke-free training data, we develop a synthetic data generation pipeline that blends artificial smoke patterns with real endoscopic images, yielding over 80,000 paired samples for supervised training. We further curate, to our knowledge, the largest paired surgical smoke dataset to date, comprising 5,817 image pairs captured with the da Vinci robotic surgical system, enabling benchmarking on high-resolution endoscopic images. Extensive experiments on both a public benchmark and our dataset demonstrate state-of-the-art performance in image reconstruction compared to existing dehazing and desmoking approaches. We also assess the impact of desmoking on downstream stereo depth estimation and instrument segmentation, highlighting both the potential benefits and current limitations of digital smoke removal methods.
On the Role of Depth in Surgical Vision Foundation Models: An Empirical Study of RGB-D Pre-training
Jan 26, 2026Vision foundation models (VFMs) have emerged as powerful tools for surgical scene understanding. However, current approaches predominantly rely on unimodal RGB pre-training, overlooking the complex 3D geometry inherent to surgical environments. Although several architectures support multimodal or geometry-aware inputs in general computer vision, the benefits of incorporating depth information in surgical settings remain underexplored. We conduct a large-scale empirical study comparing eight ViT-based VFMs that differ in pre-training domain, learning objective, and input modality (RGB vs. RGB-D). For pre-training, we use a curated dataset of 1.4 million robotic surgical images paired with depth maps generated from an off-the-shelf network. We evaluate these models under both frozen-backbone and end-to-end fine-tuning protocols across eight surgical datasets spanning object detection, segmentation, depth estimation, and pose estimation. Our experiments yield several consistent findings. Models incorporating explicit geometric tokenization, such as MultiMAE, substantially outperform unimodal baselines across all tasks. Notably, geometric-aware pre-training enables remarkable data efficiency: models fine-tuned on just 25% of labeled data consistently surpass RGB-only models trained on the full dataset. Importantly, these gains require no architectural or runtime changes at inference; depth is used only during pre-training, making adoption straightforward. These findings suggest that multimodal pre-training offers a viable path towards building more capable surgical vision systems.
Point Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
Multi-view Video-Pose Pretraining for Operating Room Surgical Activity Recognition
Feb 19, 2025



Understanding the workflow of surgical procedures in complex operating rooms requires a deep understanding of the interactions between clinicians and their environment. Surgical activity recognition (SAR) is a key computer vision task that detects activities or phases from multi-view camera recordings. Existing SAR models often fail to account for fine-grained clinician movements and multi-view knowledge, or they require calibrated multi-view camera setups and advanced point-cloud processing to obtain better results. In this work, we propose a novel calibration-free multi-view multi-modal pretraining framework called Multiview Pretraining for Video-Pose Surgical Activity Recognition PreViPS, which aligns 2D pose and vision embeddings across camera views. Our model follows CLIP-style dual-encoder architecture: one encoder processes visual features, while the other encodes human pose embeddings. To handle the continuous 2D human pose coordinates, we introduce a tokenized discrete representation to convert the continuous 2D pose coordinates into discrete pose embeddings, thereby enabling efficient integration within the dual-encoder framework. To bridge the gap between these two modalities, we propose several pretraining objectives using cross- and in-modality geometric constraints within the embedding space and incorporating masked pose token prediction strategy to enhance representation learning. Extensive experiments and ablation studies demonstrate improvements over the strong baselines, while data-efficiency experiments on two distinct operating room datasets further highlight the effectiveness of our approach. We highlight the benefits of our approach for surgical activity recognition in both multi-view and single-view settings, showcasing its practical applicability in complex surgical environments. Code will be made available at: https://github.com/CAMMA-public/PreViPS.
VidLPRO: A $\underline{Vid}$eo-$\underline{L}$anguage $\underline{P}$re-training Framework for $\underline{Ro}$botic and Laparoscopic Surgery
Sep 07, 2024We introduce VidLPRO, a novel video-language (VL) pre-training framework designed specifically for robotic and laparoscopic surgery. While existing surgical VL models primarily rely on contrastive learning, we propose a more comprehensive approach to capture the intricate temporal dynamics and align video with language. VidLPRO integrates video-text contrastive learning, video-text matching, and masked language modeling objectives to learn rich VL representations. To support this framework, we present GenSurg+, a carefully curated dataset derived from GenSurgery, comprising 17k surgical video clips paired with captions generated by GPT-4 using transcripts extracted by the Whisper model. This dataset addresses the need for large-scale, high-quality VL data in the surgical domain. Extensive experiments on benchmark datasets, including Cholec80 and AutoLaparo, demonstrate the efficacy of our approach. VidLPRO achieves state-of-the-art performance in zero-shot surgical phase recognition, significantly outperforming existing surgical VL models such as SurgVLP and HecVL. Our model demonstrates improvements of up to 21.5\% in accuracy and 15.7% in F1 score, setting a new benchmark in the field. Notably, VidLPRO exhibits robust performance even with single-frame inference, while effectively scaling with increased temporal context. Ablation studies reveal the impact of frame sampling strategies on model performance and computational efficiency. These results underscore VidLPRO's potential as a foundation model for surgical video understanding.
Curriculum learning based pre-training using Multi-Modal Contrastive Masked Autoencoders
Aug 05, 2024In this paper, we propose a new pre-training method for image understanding tasks under Curriculum Learning (CL) paradigm which leverages RGB-D. The method utilizes Multi-Modal Contrastive Masked Autoencoder and Denoising techniques. Recent approaches either use masked autoencoding (e.g., MultiMAE) or contrastive learning(e.g., Pri3D, or combine them in a single contrastive masked autoencoder architecture such as CMAE and CAV-MAE. However, none of the single contrastive masked autoencoder is applicable to RGB-D datasets. To improve the performance and efficacy of such methods, we propose a new pre-training strategy based on CL. Specifically, in the first stage, we pre-train the model using contrastive learning to learn cross-modal representations. In the second stage, we initialize the modality-specific encoders using the weights from the first stage and then pre-train the model using masked autoencoding and denoising/noise prediction used in diffusion models. Masked autoencoding focuses on reconstructing the missing patches in the input modality using local spatial correlations, while denoising learns high frequency components of the input data. Our approach is scalable, robust and suitable for pre-training with limited RGB-D datasets. Extensive experiments on multiple datasets such as ScanNet, NYUv2 and SUN RGB-D show the efficacy and superior performance of our approach. Specifically, we show an improvement of +1.0% mIoU against Mask3D on ScanNet semantic segmentation. We further demonstrate the effectiveness of our approach in low-data regime by evaluating it for semantic segmentation task against the state-of-the-art methods.
Rethinking RGB-D Fusion for Semantic Segmentation in Surgical Datasets
Jul 29, 2024



Surgical scene understanding is a key technical component for enabling intelligent and context aware systems that can transform various aspects of surgical interventions. In this work, we focus on the semantic segmentation task, propose a simple yet effective multi-modal (RGB and depth) training framework called SurgDepth, and show state-of-the-art (SOTA) results on all publicly available datasets applicable for this task. Unlike previous approaches, which either fine-tune SOTA segmentation models trained on natural images, or encode RGB or RGB-D information using RGB only pre-trained backbones, SurgDepth, which is built on top of Vision Transformers (ViTs), is designed to encode both RGB and depth information through a simple fusion mechanism. We conduct extensive experiments on benchmark datasets including EndoVis2022, AutoLapro, LapI2I and EndoVis2017 to verify the efficacy of SurgDepth. Specifically, SurgDepth achieves a new SOTA IoU of 0.86 on EndoVis 2022 SAR-RARP50 challenge and outperforms the current best method by at least 4%, using a shallow and compute efficient decoder consisting of ConvNeXt blocks.
Self-supervised Learning via Cluster Distance Prediction for Operating Room Context Awareness
Jul 07, 2024Semantic segmentation and activity classification are key components to creating intelligent surgical systems able to understand and assist clinical workflow. In the Operating Room, semantic segmentation is at the core of creating robots aware of clinical surroundings, whereas activity classification aims at understanding OR workflow at a higher level. State-of-the-art semantic segmentation and activity recognition approaches are fully supervised, which is not scalable. Self-supervision can decrease the amount of annotated data needed. We propose a new 3D self-supervised task for OR scene understanding utilizing OR scene images captured with ToF cameras. Contrary to other self-supervised approaches, where handcrafted pretext tasks are focused on 2D image features, our proposed task consists of predicting the relative 3D distance of image patches by exploiting the depth maps. Learning 3D spatial context generates discriminative features for our downstream tasks. Our approach is evaluated on two tasks and datasets containing multi-view data captured from clinical scenarios. We demonstrate a noteworthy improvement of performance on both tasks, specifically on low-regime data where utility of self-supervised learning is the highest.
AdaEmbed: Semi-supervised Domain Adaptation in the Embedding Space
Jan 23, 2024Semi-supervised domain adaptation (SSDA) presents a critical hurdle in computer vision, especially given the frequent scarcity of labeled data in real-world settings. This scarcity often causes foundation models, trained on extensive datasets, to underperform when applied to new domains. AdaEmbed, our newly proposed methodology for SSDA, offers a promising solution to these challenges. Leveraging the potential of unlabeled data, AdaEmbed facilitates the transfer of knowledge from a labeled source domain to an unlabeled target domain by learning a shared embedding space. By generating accurate and uniform pseudo-labels based on the established embedding space, the model overcomes the limitations of conventional SSDA, thus enhancing performance significantly. Our method's effectiveness is validated through extensive experiments on benchmark datasets such as DomainNet, Office-Home, and VisDA-C, where AdaEmbed consistently outperforms all the baselines, setting a new state of the art for SSDA. With its straightforward implementation and high data efficiency, AdaEmbed stands out as a robust and pragmatic solution for real-world scenarios, where labeled data is scarce. To foster further research and application in this area, we are sharing the codebase of our unified framework for semi-supervised domain adaptation.
SAR-RARP50: Segmentation of surgical instrumentation and Action Recognition on Robot-Assisted Radical Prostatectomy Challenge
Dec 31, 2023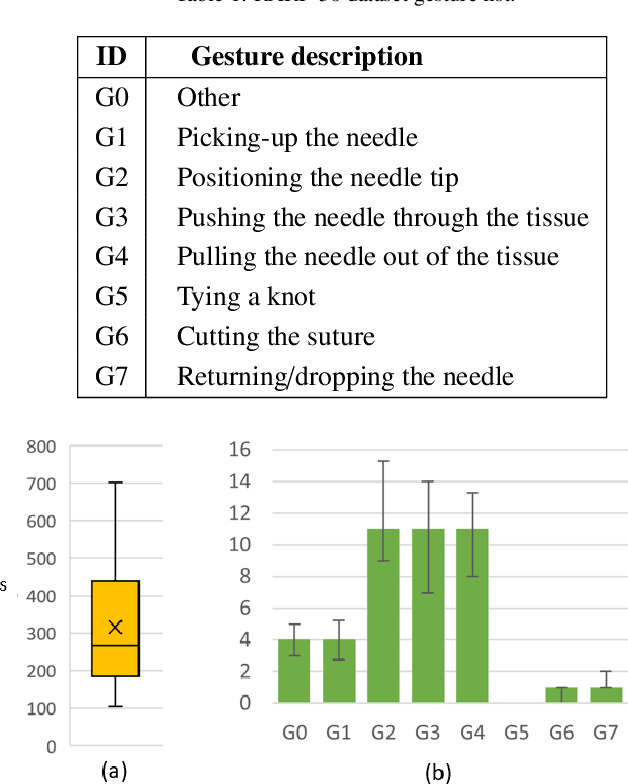
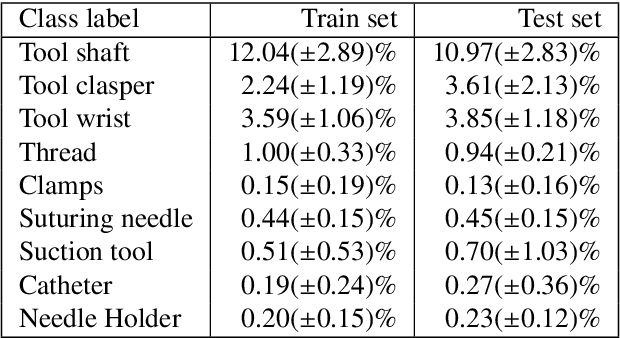
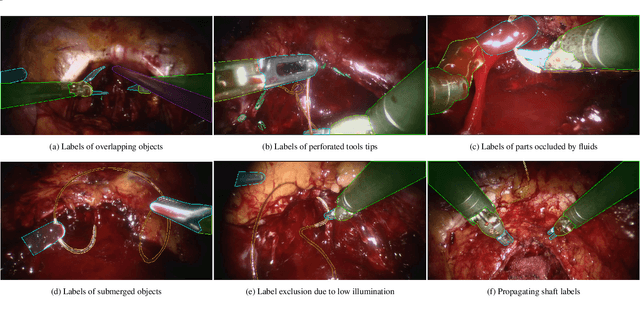
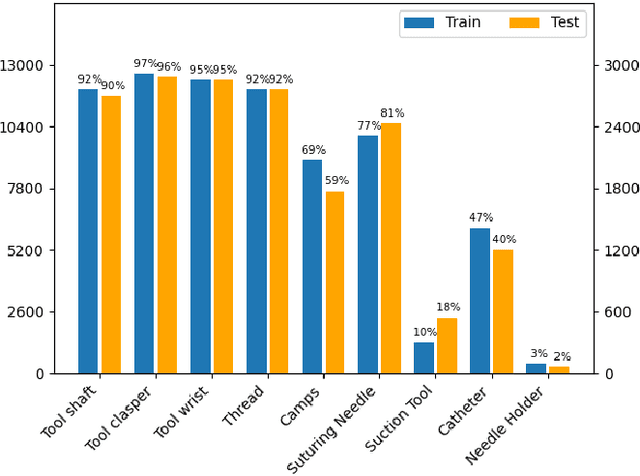
Surgical tool segmentation and action recognition are fundamental building blocks in many computer-assisted intervention applications, ranging from surgical skills assessment to decision support systems. Nowadays, learning-based action recognition and segmentation approaches outperform classical methods, relying, however, on large, annotated datasets. Furthermore, action recognition and tool segmentation algorithms are often trained and make predictions in isolation from each other, without exploiting potential cross-task relationships. With the EndoVis 2022 SAR-RARP50 challenge, we release the first multimodal, publicly available, in-vivo, dataset for surgical action recognition and semantic instrumentation segmentation, containing 50 suturing video segments of Robotic Assisted Radical Prostatectomy (RARP). The aim of the challenge is twofold. First, to enable researchers to leverage the scale of the provided dataset and develop robust and highly accurate single-task action recognition and tool segmentation approaches in the surgical domain. Second, to further explore the potential of multitask-based learning approaches and determine their comparative advantage against their single-task counterparts. A total of 12 teams participated in the challenge, contributing 7 action recognition methods, 9 instrument segmentation techniques, and 4 multitask approaches that integrated both action recognition and instrument segmentation.