 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAR-RARP50: Segmentation of surgical instrumentation and Action Recognition on Robot-Assisted Radical Prostatectomy Challenge
Dec 31, 2023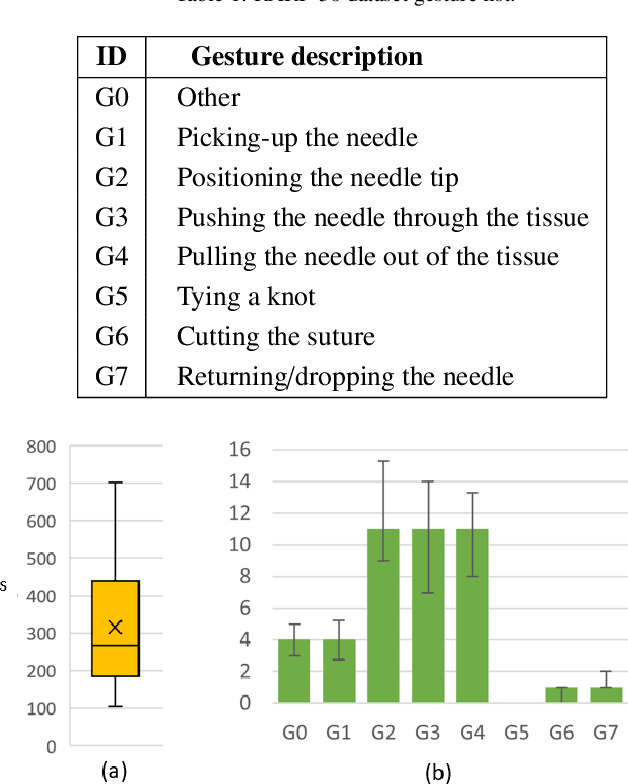
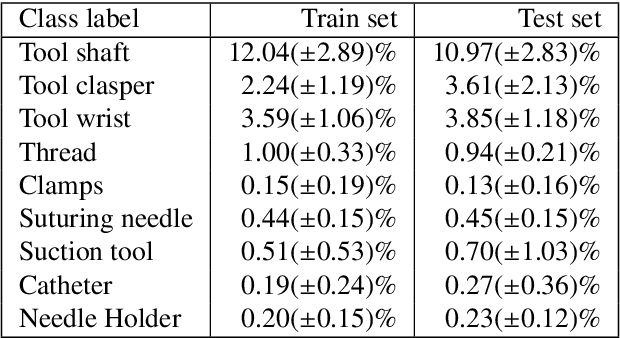
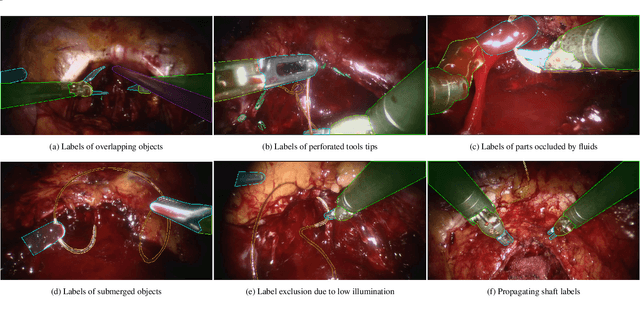
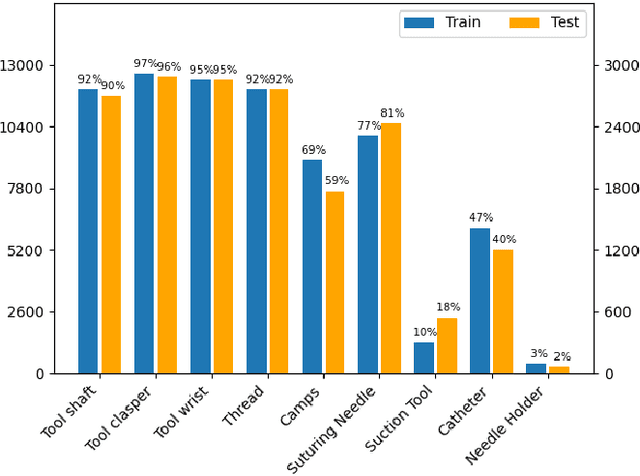
Surgical tool segmentation and action recognition are fundamental building blocks in many computer-assisted intervention applications, ranging from surgical skills assessment to decision support systems. Nowadays, learning-based action recognition and segmentation approaches outperform classical methods, relying, however, on large, annotated datasets. Furthermore, action recognition and tool segmentation algorithms are often trained and make predictions in isolation from each other, without exploiting potential cross-task relationships. With the EndoVis 2022 SAR-RARP50 challenge, we release the first multimodal, publicly available, in-vivo, dataset for surgical action recognition and semantic instrumentation segmentation, containing 50 suturing video segments of Robotic Assisted Radical Prostatectomy (RARP). The aim of the challenge is twofold. First, to enable researchers to leverage the scale of the provided dataset and develop robust and highly accurate single-task action recognition and tool segmentation approaches in the surgical domain. Second, to further explore the potential of multitask-based learning approaches and determine their comparative advantage against their single-task counterparts. A total of 12 teams participated in the challenge, contributing 7 action recognition methods, 9 instrument segmentation techniques, and 4 multitask approaches that integrated both action recognition and instrument segmentation.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.