 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Assured: Rethinking Annotation Strategies in Imaging AI
Jul 26, 2024



This paper does not describe a novel method. Instead, it studies an essential foundation for reliable benchmarking and ultimately real-world application of AI-based image analysis: generating high-quality reference annotations. Previous research has focused on crowdsourcing as a means of outsourcing annotations. However, little attention has so far been given to annotation companies, specifically regarding their internal quality assurance (QA) processes. Therefore, our aim is to evaluate the influence of QA employed by annotation companies on annotation quality and devise methodologies for maximizing data annotation efficacy. Based on a total of 57,648 instance segmented images obtained from a total of 924 annotators and 34 QA workers from four annotation companies and Amazon Mechanical Turk (MTurk), we derived the following insights: (1) Annotation companies perform better both in terms of quantity and quality compared to the widely used platform MTurk. (2) Annotation companies' internal QA only provides marginal improvements, if any. However, improving labeling instructions instead of investing in QA can substantially boost annotation performance. (3) The benefit of internal QA depends on specific image characteristics. Our work could enable researchers to derive substantially more value from a fixed annotation budget and change the way annotation companies conduct internal QA.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Labeling instructions matter in biomedical image analysis
Jul 20, 2022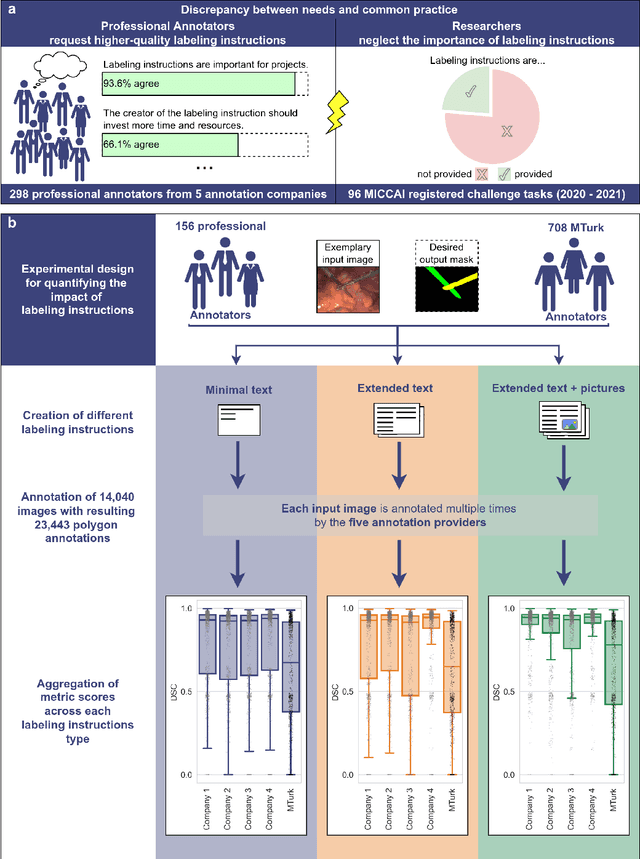
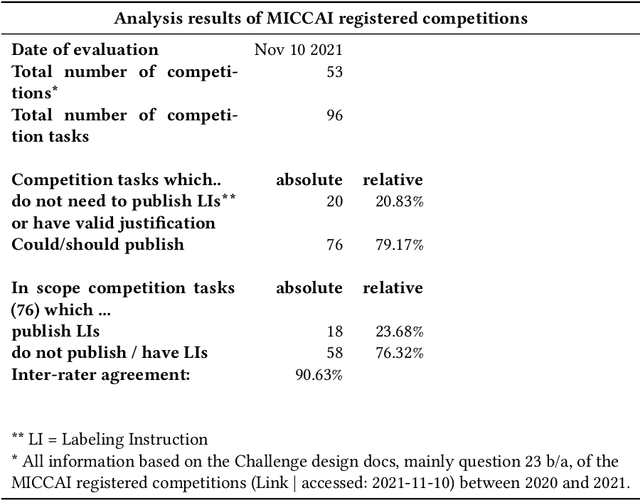
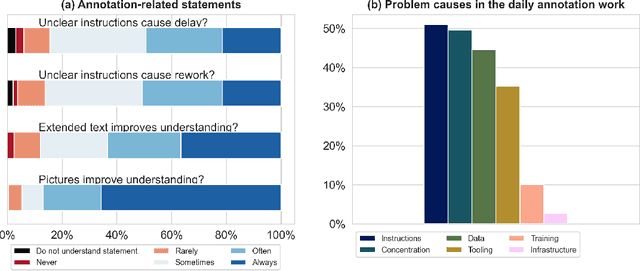
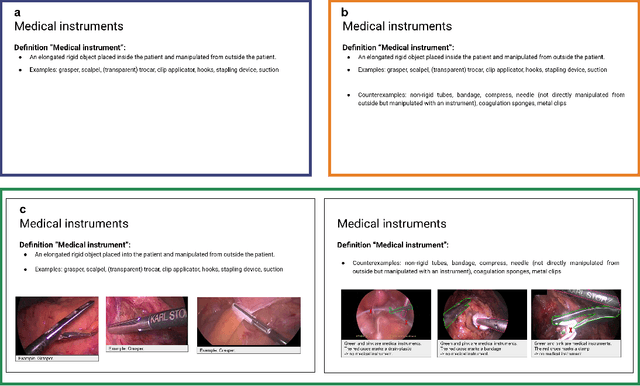
Biomedical image analysis algorithm validation depends on high-quality annotation of reference datasets, for which labeling instructions are key. Despite their importance, their optimization remains largely unexplored. Here, we present the first systematic study of labeling instructions and their impact on annotation quality in the field. Through comprehensive examination of professional practice and international competitions registered at the MICCAI Society, we uncovered a discrepancy between annotators' needs for labeling instructions and their current quality and availability. Based on an analysis of 14,040 images annotated by 156 annotators from four professional companies and 708 Amazon Mechanical Turk (MTurk) crowdworkers using instructions with different information density levels, we further found that including exemplary images significantly boosts annotation performance compared to text-only descriptions, while solely extending text descriptions does not. Finally, professional annotators constantly outperform MTurk crowdworkers. Our study raises awareness for the need of quality standards in biomedical image analysis labeling instructions.