 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Centric Anthropomorphic 3D CT Phantom-Based Benchmark Dataset for Harmonization
Jul 02, 2025Artificial intelligence (AI) has introduced numerous opportunities for human assistance and task automation in medicine. However, it suffers from poor generalization in the presence of shifts in the data distribution. In the context of AI-based computed tomography (CT) analysis, significant data distribution shifts can be caused by changes in scanner manufacturer, reconstruction technique or dose. AI harmonization techniques can address this problem by reducing distribution shifts caused by various acquisition settings. This paper presents an open-source benchmark dataset containing CT scans of an anthropomorphic phantom acquired with various scanners and settings, which purpose is to foster the development of AI harmonization techniques. Using a phantom allows fixing variations attributed to inter- and intra-patient variations. The dataset includes 1378 image series acquired with 13 scanners from 4 manufacturers across 8 institutions using a harmonized protocol as well as several acquisition doses. Additionally, we present a methodology, baseline results and open-source code to assess image- and feature-level stability and liver tissue classification, promoting the development of AI harmonization strategies.
Instance-level quantitative saliency in multiple sclerosis lesion segmentation
Jun 13, 2024
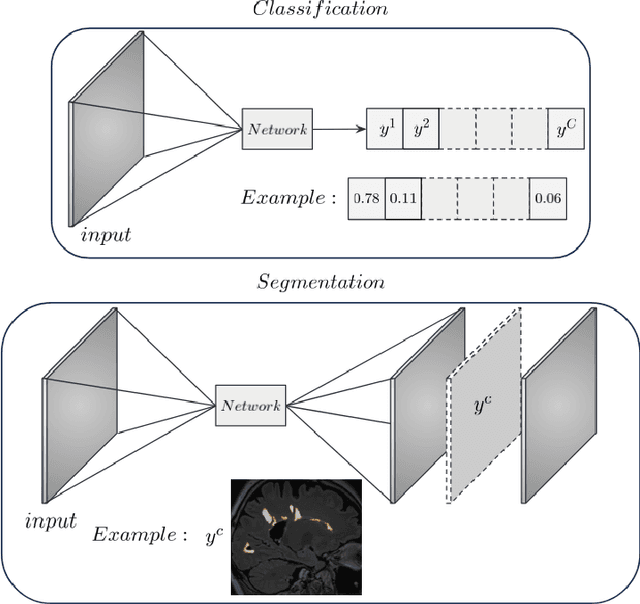


In recent years, explainable methods for artificial intelligence (XAI) have tried to reveal and describe models' decision mechanisms in the case of classification tasks. However, XAI for semantic segmentation and in particular for single instances has been little studied to date. Understanding the process underlying automatic segmentation of single instances is crucial to reveal what information was used to detect and segment a given object of interest. In this study, we proposed two instance-level explanation maps for semantic segmentation based on SmoothGrad and Grad-CAM++ methods. Then, we investigated their relevance for the detection and segmentation of white matter lesions (WML), a magnetic resonance imaging (MRI) biomarker in multiple sclerosis (MS). 687 patients diagnosed with MS for a total of 4043 FLAIR and MPRAGE MRI scans were collected at the University Hospital of Basel, Switzerland. Data were randomly split into training, validation and test sets to train a 3D U-Net for MS lesion segmentation. We observed 3050 true positive (TP), 1818 false positive (FP), and 789 false negative (FN) cases. We generated instance-level explanation maps for semantic segmentation, by developing two XAI methods based on SmoothGrad and Grad-CAM++. We investigated: 1) the distribution of gradients in saliency maps with respect to both input MRI sequences; 2) the model's response in the case of synthetic lesions; 3) the amount of perilesional tissue needed by the model to segment a lesion. Saliency maps (based on SmoothGrad) in FLAIR showed positive values inside a lesion and negative in its neighborhood. Peak values of saliency maps generated for these four groups of volumes presented distributions that differ significantly from one another, suggesting a quantitative nature of the proposed saliency. Contextual information of 7mm around the lesion border was required for their segmentation.
EDUE: Expert Disagreement-Guided One-Pass Uncertainty Estimation for Medical Image Segmentation
Mar 25, 2024
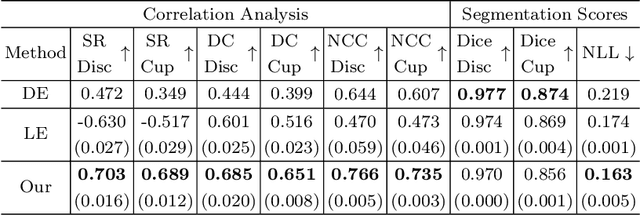
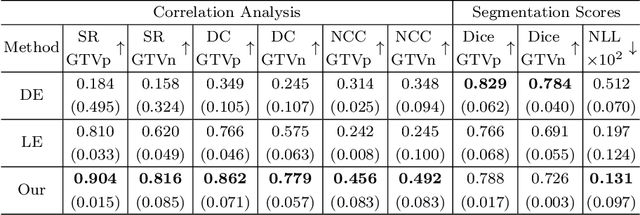

Deploying deep learning (DL) models in medical applications relies on predictive performance and other critical factors, such as conveying trustworthy predictive uncertainty. Uncertainty estimation (UE) methods provide potential solutions for evaluating prediction reliability and improving the model confidence calibration. Despite increasing interest in UE, challenges persist, such as the need for explicit methods to capture aleatoric uncertainty and align uncertainty estimates with real-life disagreements among domain experts. This paper proposes an Expert Disagreement-Guided Uncertainty Estimation (EDUE) for medical image segmentation. By leveraging variability in ground-truth annotations from multiple raters, we guide the model during training and incorporate random sampling-based strategies to enhance calibration confidence. Our method achieves 55% and 23% improvement in correlation on average with expert disagreements at the image and pixel levels, respectively, better calibration, and competitive segmentation performance compared to the state-of-the-art deep ensembles, requiring only a single forward pass.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Uncovering Unique Concept Vectors through Latent Space Decomposition
Jul 14, 2023Interpreting the inner workings of deep learning models is crucial for establishing trust and ensuring model safety. Concept-based explanations have emerged as a superior approach that is more interpretable than feature attribution estimates such as pixel saliency. However, defining the concepts for the interpretability analysis biases the explanations by the user's expectations on the concepts. To address this, we propose a novel post-hoc unsupervised method that automatically uncovers the concepts learned by deep models during training. By decomposing the latent space of a layer in singular vectors and refining them by unsupervised clustering, we uncover concept vectors aligned with directions of high variance that are relevant to the model prediction, and that point to semantically distinct concepts. Our extensive experiments reveal that the majority of our concepts are readily understandable to humans, exhibit coherency, and bear relevance to the task at hand. Moreover, we showcase the practical utility of our method in dataset exploration, where our concept vectors successfully identify outlier training samples affected by various confounding factors. This novel exploration technique has remarkable versatility to data types and model architectures and it will facilitate the identification of biases and the discovery of sources of error within training data.
Disentangling Neuron Representations with Concept Vectors
Apr 19, 2023



Mechanistic interpretability aims to understand how models store representations by breaking down neural networks into interpretable units. However, the occurrence of polysemantic neurons, or neurons that respond to multiple unrelated features, makes interpreting individual neurons challenging. This has led to the search for meaningful vectors, known as concept vectors, in activation space instead of individual neurons. The main contribution of this paper is a method to disentangle polysemantic neurons into concept vectors encapsulating distinct features. Our method can search for fine-grained concepts according to the user's desired level of concept separation. The analysis shows that polysemantic neurons can be disentangled into directions consisting of linear combinations of neurons. Our evaluations show that the concept vectors found encode coherent, human-understandable features.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Overview of the HECKTOR Challenge at MICCAI 2021: Automatic Head and Neck Tumor Segmentation and Outcome Prediction in PET/CT Images
Jan 11, 2022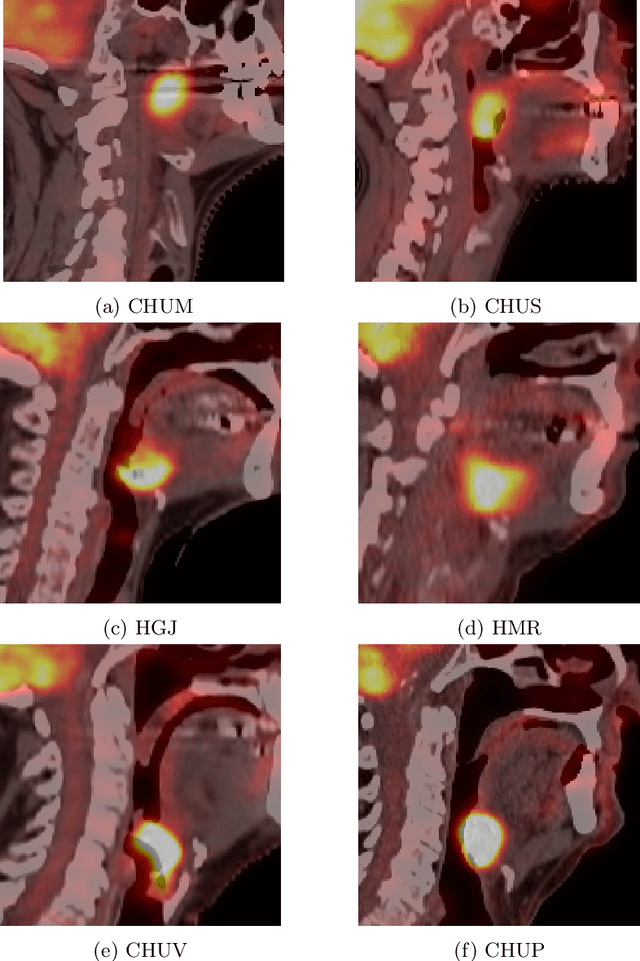
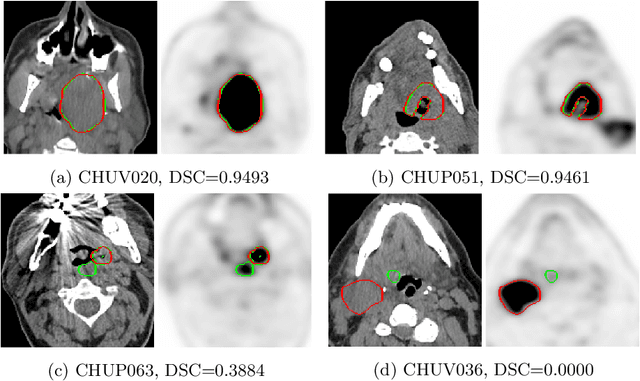
This paper presents an overview of the second edition of the HEad and neCK TumOR (HECKTOR) challenge, organized as a satellite event of the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) 2021. The challenge is composed of three tasks related to the automatic analysis of PET/CT images for patients with Head and Neck cancer (H&N), focusing on the oropharynx region. Task 1 is the automatic segmentation of H&N primary Gross Tumor Volume (GTVt) in FDG-PET/CT images. Task 2 is the automatic prediction of Progression Free Survival (PFS) from the same FDG-PET/CT. Finally, Task 3 is the same as Task 2 with ground truth GTVt annotations provided to the participants. The data were collected from six centers for a total of 325 images, split into 224 training and 101 testing cases. The interest in the challenge was highlighted by the important participation with 103 registered teams and 448 result submissions. The best methods obtained a Dice Similarity Coefficient (DSC) of 0.7591 in the first task, and a Concordance index (C-index) of 0.7196 and 0.6978 in Tasks 2 and 3, respectively. In all tasks, simplicity of the approach was found to be key to ensure generalization performance. The comparison of the PFS prediction performance in Tasks 2 and 3 suggests that providing the GTVt contour was not crucial to achieve best results, which indicates that fully automatic methods can be used. This potentially obviates the need for GTVt contouring, opening avenues for reproducible and large scale radiomics studies including thousands potential subjects.
Guiding CNNs towards Relevant Concepts by Multi-task and Adversarial Learning
Aug 04, 2020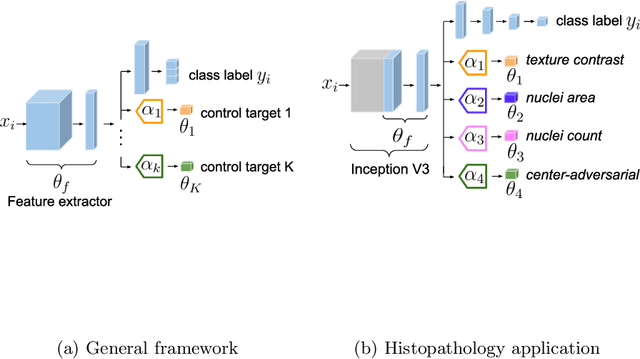

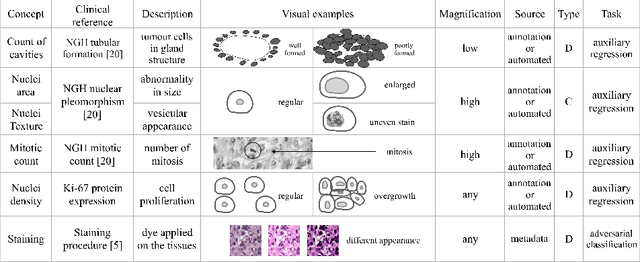
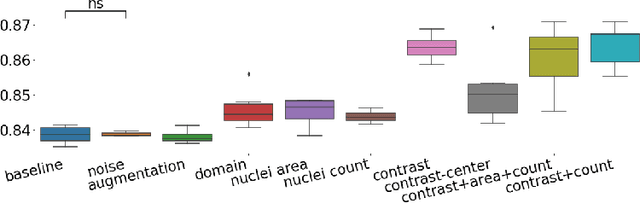
The opaqueness of deep learning limits its deployment in critical application scenarios such as cancer grading in medical images. In this paper, a framework for guiding CNN training is built on top of successful existing techniques of hard parameter sharing, with the main goal of explicitly introducing expert knowledge in the training objectives. The learning process is guided by identifying concepts that are relevant or misleading for the task. Relevant concepts are encouraged to appear in the representation through multi-task learning. Undesired and misleading concepts are discouraged by a gradient reversal operation. In this way, a shift in the deep representations can be corrected to match the clinicians' assumptions. The application on breast lymph nodes histopathology data from the Camelyon challenge shows a significant increase in the generalization performance on unseen patients (from 0.839 to 0.864 average AUC, $\text{p-value} = 0,0002$) when the internal representations are controlled by prior knowledge regarding the acquisition center and visual features of the tissue. The code will be shared for reproducibility on our GitHub repository.