 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-DCNet: Dynamic Convolutional Neural Network with Contrastive Constraints for Identifying Lung Cancer Subtypes on Multi-modality Images
Jul 18, 2024



The accurate diagnosis of pathological subtypes of lung cancer is of paramount importance for follow-up treatments and prognosis managements. Assessment methods utilizing deep learning technologies have introduced novel approaches for clinical diagnosis. However, the majority of existing models rely solely on single-modality image input, leading to limited diagnostic accuracy. To this end, we propose a novel deep learning network designed to accurately classify lung cancer subtype with multi-dimensional and multi-modality images, i.e., CT and pathological images. The strength of the proposed model lies in its ability to dynamically process both paired CT-pathological image sets as well as independent CT image sets, and consequently optimize the pathology-related feature extractions from CT images. This adaptive learning approach enhances the flexibility in processing multi-dimensional and multi-modality datasets and results in performance elevating in the model testing phase. We also develop a contrastive constraint module, which quantitatively maps the cross-modality associations through network training, and thereby helps to explore the "gold standard" pathological information from the corresponding CT scans. To evaluate the effectiveness, adaptability, and generalization ability of our model, we conducted extensive experiments on a large-scale multi-center dataset and compared our model with a series of state-of-the-art classification models. The experimental results demonstrated the superiority of our model for lung cancer subtype classification, showcasing significant improvements in accuracy metrics such as ACC, AUC, and F1-score.
A Region-Shrinking-Based Acceleration for Classification-Based Derivative-Free Optimization
Sep 20, 2023



Derivative-free optimization algorithms play an important role in scientific and engineering design optimization problems, especially when derivative information is not accessible. In this paper, we study the framework of classification-based derivative-free optimization algorithms. By introducing a concept called hypothesis-target shattering rate, we revisit the computational complexity upper bound of this type of algorithms. Inspired by the revisited upper bound, we propose an algorithm named "RACE-CARS", which adds a random region-shrinking step compared with "SRACOS" (Hu et al., 2017).. We further establish a theorem showing the acceleration of region-shrinking. Experiments on the synthetic functions as well as black-box tuning for language-model-as-a-service demonstrate empirically the efficiency of "RACE-CARS". An ablation experiment on the introduced hyperparameters is also conducted, revealing the mechanism of "RACE-CARS" and putting forward an empirical hyperparameter-tuning guidance.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Classification of lung cancer subtypes on CT images with synthetic pathological priors
Aug 09, 2023



The accurate diagnosis on pathological subtypes for lung cancer is of significant importance for the follow-up treatments and prognosis managements. In this paper, we propose self-generating hybrid feature network (SGHF-Net) for accurately classifying lung cancer subtypes on computed tomography (CT) images. Inspired by studies stating that cross-scale associations exist in the image patterns between the same case's CT images and its pathological images, we innovatively developed a pathological feature synthetic module (PFSM), which quantitatively maps cross-modality associations through deep neural networks, to derive the "gold standard" information contained in the corresponding pathological images from CT images. Additionally, we designed a radiological feature extraction module (RFEM) to directly acquire CT image information and integrated it with the pathological priors under an effective feature fusion framework, enabling the entire classification model to generate more indicative and specific pathologically related features and eventually output more accurate predictions. The superiority of the proposed model lies in its ability to self-generate hybrid features that contain multi-modality image information based on a single-modality input. To evaluate the effectiveness, adaptability, and generalization ability of our model, we performed extensive experiments on a large-scale multi-center dataset (i.e., 829 cases from three hospitals) to compare our model and a series of state-of-the-art (SOTA) classification models. The experimental results demonstrated the superiority of our model for lung cancer subtypes classification with significant accuracy improvements in terms of accuracy (ACC), area under the curve (AUC), and F1 score.
HiTSKT: A Hierarchical Transformer Model for Session-Aware Knowledge Tracing
Dec 23, 2022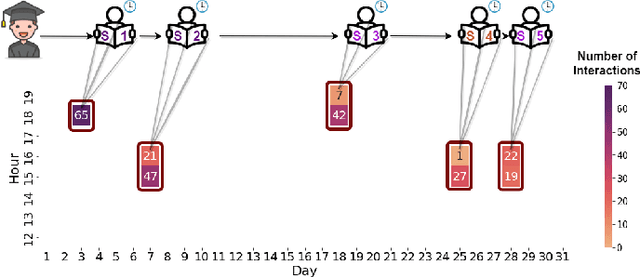
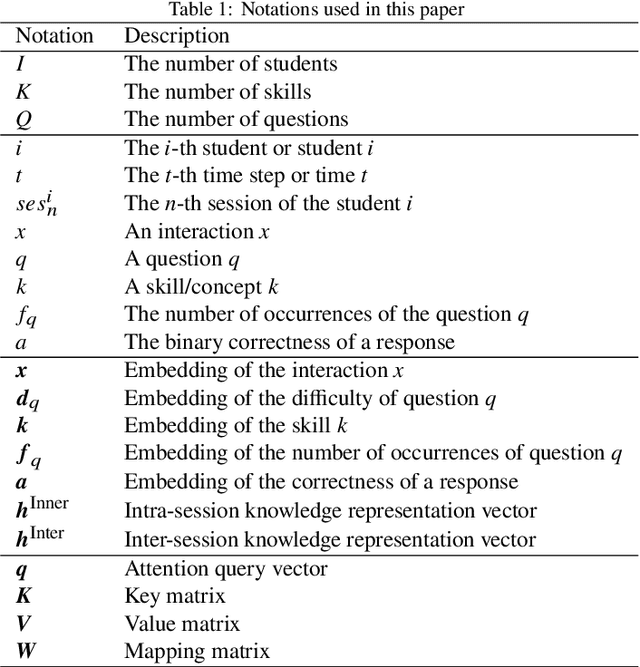
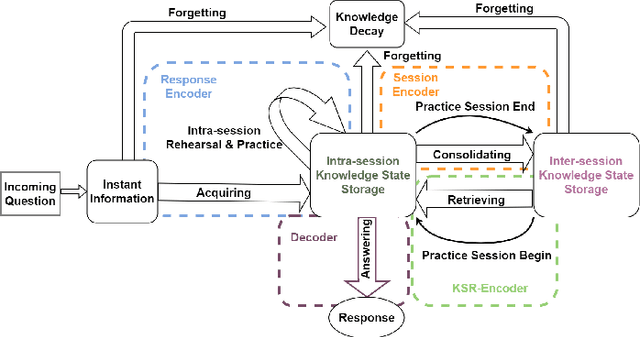
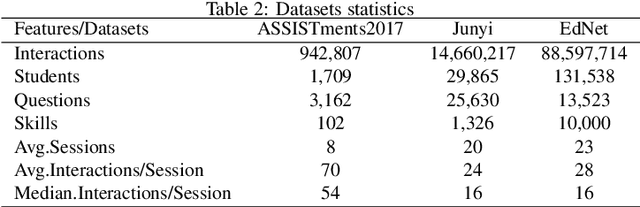
Knowledge tracing (KT) aims to leverage students' learning histories to estimate their mastery levels on a set of pre-defined skills, based on which the corresponding future performance can be accurately predicted. In practice, a student's learning history comprises answers to sets of massed questions, each known as a session, rather than merely being a sequence of independent answers. Theoretically, within and across these sessions, students' learning dynamics can be very different. Therefore, how to effectively model the dynamics of students' knowledge states within and across the sessions is crucial for handling the KT problem. Most existing KT models treat student's learning records as a single continuing sequence, without capturing the sessional shift of students' knowledge state. To address the above issue, we propose a novel hierarchical transformer model, named HiTSKT, comprises an interaction(-level) encoder to capture the knowledge a student acquires within a session, and a session(-level) encoder to summarise acquired knowledge across the past sessions. To predict an interaction in the current session, a knowledge retriever integrates the summarised past-session knowledge with the previous interactions' information into proper knowledge representations. These representations are then used to compute the student's current knowledge state. Additionally, to model the student's long-term forgetting behaviour across the sessions, a power-law-decay attention mechanism is designed and deployed in the session encoder, allowing it to emphasize more on the recent sessions. Extensive experiments on three public datasets demonstrate that HiTSKT achieves new state-of-the-art performance on all the datasets compared with six state-of-the-art KT models.
Learning Semantic Textual Similarity via Topic-informed Discrete Latent Variables
Nov 07, 2022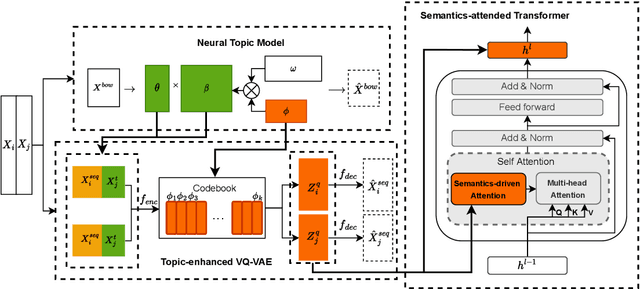
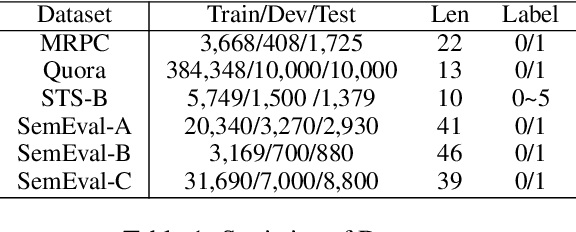
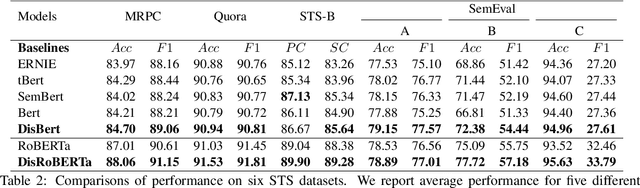
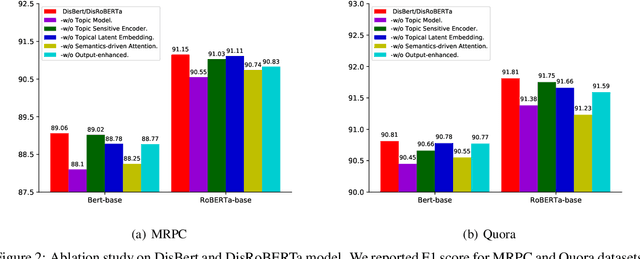
Recently, discrete latent variable models have received a surge of interest in both Natural Language Processing (NLP) and Computer Vision (CV), attributed to their comparable performance to the continuous counterparts in representation learning, while being more interpretable in their predictions. In this paper, we develop a topic-informed discrete latent variable model for semantic textual similarity, which learns a shared latent space for sentence-pair representation via vector quantization. Compared with previous models limited to local semantic contexts, our model can explore richer semantic information via topic modeling. We further boost the performance of semantic similarity by injecting the quantized representation into a transformer-based language model with a well-designed semantic-driven attention mechanism. We demonstrate, through extensive experiments across various English language datasets, that our model is able to surpass several strong neural baselines in semantic textual similarity tasks.
The HoloLens in Medicine: A systematic Review and Taxonomy
Sep 06, 2022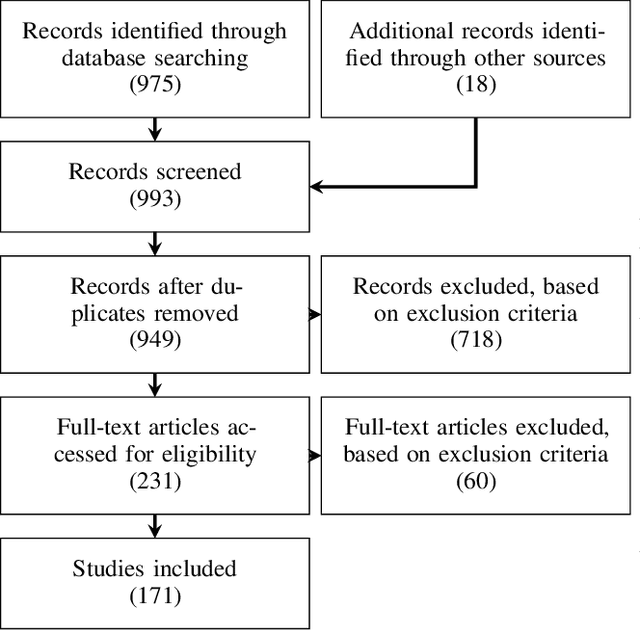
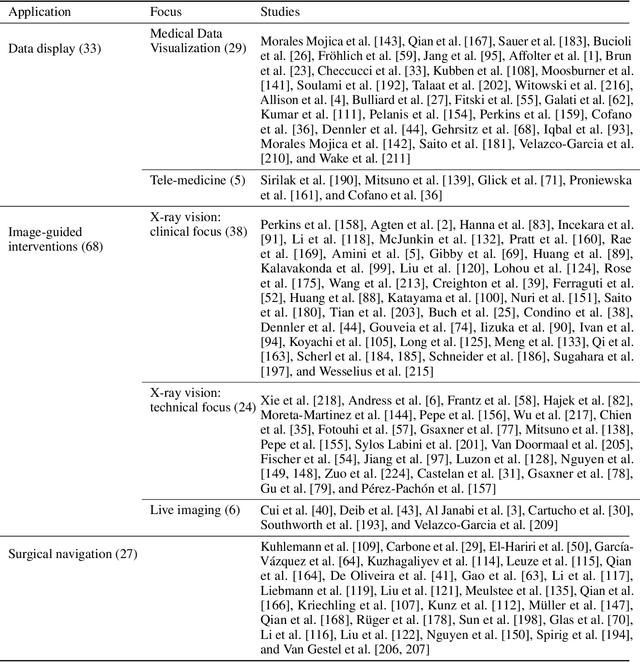
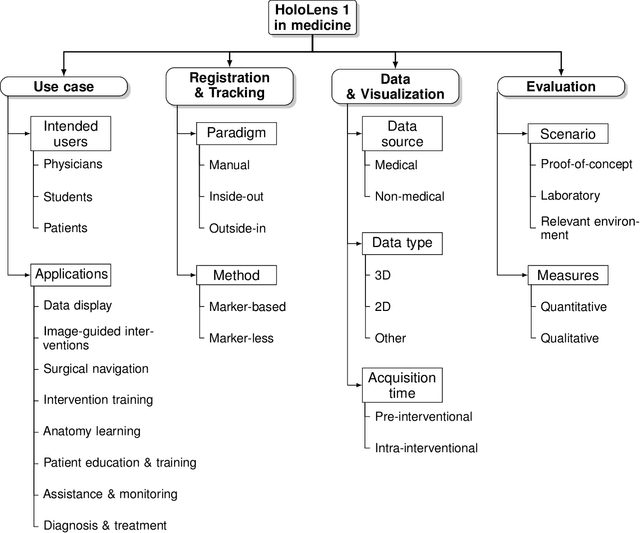

The HoloLens (Microsoft Corp., Redmond, WA), a head-worn, optically see-through augmented reality display, is the main player in the recent boost in medical augmented reality research. In medical settings, the HoloLens enables the physician to obtain immediate insight into patient information, directly overlaid with their view of the clinical scenario, the medical student to gain a better understanding of complex anatomies or procedures, and even the patient to execute therapeutic tasks with improved, immersive guidance. In this systematic review, we provide a comprehensive overview of the usage of the first-generation HoloLens within the medical domain, from its release in March 2016, until the year of 2021, were attention is shifting towards it's successor, the HoloLens 2. We identified 171 relevant publications through a systematic search of the PubMed and Scopus databases. We analyze these publications in regard to their intended use case, technical methodology for registration and tracking, data sources, visualization as well as validation and evaluation. We find that, although the feasibility of using the HoloLens in various medical scenarios has been shown, increased efforts in the areas of precision, reliability, usability, workflow and perception are necessary to establish AR in clinical practice.
Neural Attention-Aware Hierarchical Topic Model
Oct 14, 2021
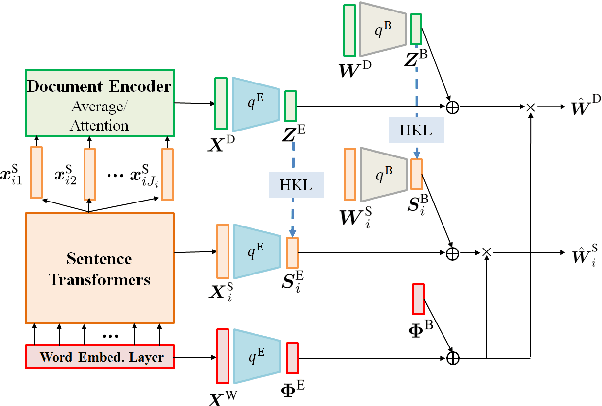


Neural topic models (NTMs) apply deep neural networks to topic modelling. Despite their success, NTMs generally ignore two important aspects: (1) only document-level word count information is utilized for the training, while more fine-grained sentence-level information is ignored, and (2) external semantic knowledge regarding documents, sentences and words are not exploited for the training. To address these issues, we propose a variational autoencoder (VAE) NTM model that jointly reconstructs the sentence and document word counts using combinations of bag-of-words (BoW) topical embeddings and pre-trained semantic embeddings. The pre-trained embeddings are first transformed into a common latent topical space to align their semantics with the BoW embeddings. Our model also features hierarchical KL divergence to leverage embeddings of each document to regularize those of their sentences, thereby paying more attention to semantically relevant sentences. Both quantitative and qualitative experiments have shown the efficacy of our model in 1) lowering the reconstruction errors at both the sentence and document levels, and 2) discovering more coherent topics from real-world datasets.
Transformer over Pre-trained Transformer for Neural Text Segmentation with Enhanced Topic Coherence
Oct 14, 2021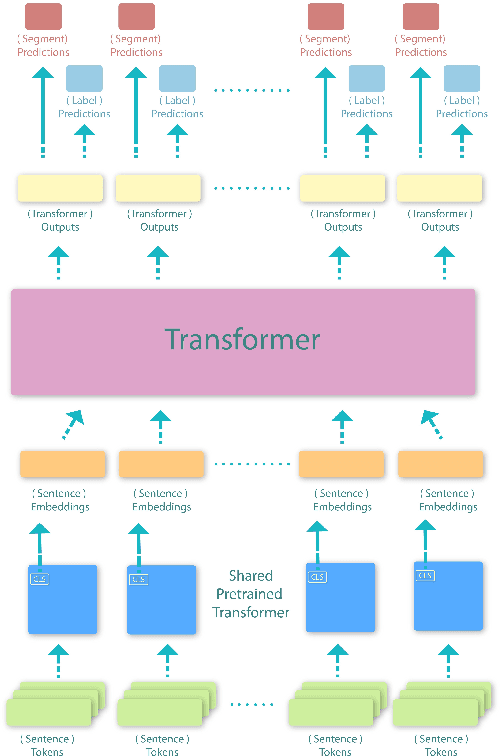


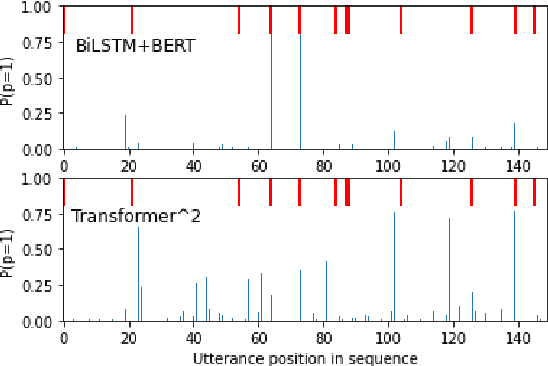
This paper proposes a transformer over transformer framework, called Transformer$^2$, to perform neural text segmentation. It consists of two components: bottom-level sentence encoders using pre-trained transformers, and an upper-level transformer-based segmentation model based on the sentence embeddings. The bottom-level component transfers the pre-trained knowledge learned from large external corpora under both single and pair-wise supervised NLP tasks to model the sentence embeddings for the documents. Given the sentence embeddings, the upper-level transformer is trained to recover the segmentation boundaries as well as the topic labels of each sentence. Equipped with a multi-task loss and the pre-trained knowledge, Transformer$^2$ can better capture the semantic coherence within the same segments. Our experiments show that (1) Transformer$^2$ manages to surpass state-of-the-art text segmentation models in terms of a commonly-used semantic coherence measure; (2) in most cases, both single and pair-wise pre-trained knowledge contribute to the model performance; (3) bottom-level sentence encoders pre-trained on specific languages yield better performance than those pre-trained on specific domains.
Leveraging Information Bottleneck for Scientific Document Summarization
Oct 04, 2021
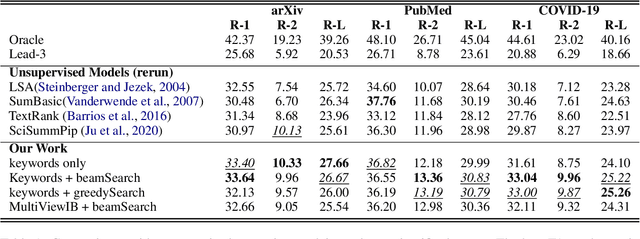
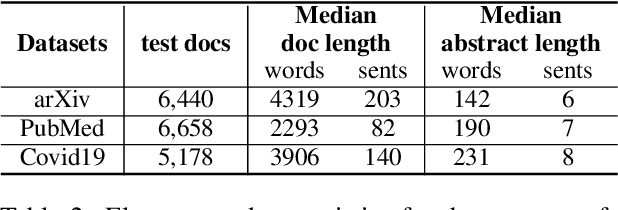
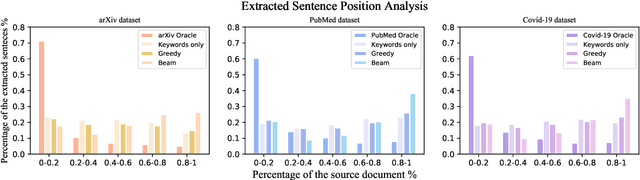
This paper presents an unsupervised extractive approach to summarize scientific long documents based on the Information Bottleneck principle. Inspired by previous work which uses the Information Bottleneck principle for sentence compression, we extend it to document level summarization with two separate steps. In the first step, we use signal(s) as queries to retrieve the key content from the source document. Then, a pre-trained language model conducts further sentence search and edit to return the final extracted summaries. Importantly, our work can be flexibly extended to a multi-view framework by different signals. Automatic evaluation on three scientific document datasets verifies the effectiveness of the proposed framework. The further human evaluation suggests that the extracted summaries cover more content aspects than previous systems.