 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext Generation Active Learning: Mixture of LLMs in the Loop
Jan 22, 2026With the rapid advancement and strong generalization capabilities of large language models (LLMs), they have been increasingly incorporated into the active learning pipelines as annotators to reduce annotation costs. However, considering the annotation quality, labels generated by LLMs often fall short of real-world applicability. To address this, we propose a novel active learning framework, Mixture of LLMs in the Loop Active Learning, replacing human annotators with labels generated through a Mixture-of-LLMs-based annotation model, aimed at enhancing LLM-based annotation robustness by aggregating the strengths of multiple LLMs. To further mitigate the impact of the noisy labels, we introduce annotation discrepancy and negative learning to identify the unreliable annotations and enhance learning effectiveness. Extensive experiments demonstrate that our framework achieves performance comparable to human annotation and consistently outperforms single-LLM baselines and other LLM-ensemble-based approaches. Moreover, our framework is built on lightweight LLMs, enabling it to operate fully on local machines in real-world applications.
IdentityStory: Taming Your Identity-Preserving Generator for Human-Centric Story Generation
Dec 29, 2025Recent visual generative models enable story generation with consistent characters from text, but human-centric story generation faces additional challenges, such as maintaining detailed and diverse human face consistency and coordinating multiple characters across different images. This paper presents IdentityStory, a framework for human-centric story generation that ensures consistent character identity across multiple sequential images. By taming identity-preserving generators, the framework features two key components: Iterative Identity Discovery, which extracts cohesive character identities, and Re-denoising Identity Injection, which re-denoises images to inject identities while preserving desired context. Experiments on the ConsiStory-Human benchmark demonstrate that IdentityStory outperforms existing methods, particularly in face consistency, and supports multi-character combinations. The framework also shows strong potential for applications such as infinite-length story generation and dynamic character composition.
ALScope: A Unified Toolkit for Deep Active Learning
Aug 06, 2025Deep Active Learning (DAL) reduces annotation costs by selecting the most informative unlabeled samples during training. As real-world applications become more complex, challenges stemming from distribution shifts (e.g., open-set recognition) and data imbalance have gained increasing attention, prompting the development of numerous DAL algorithms. However, the lack of a unified platform has hindered fair and systematic evaluation under diverse conditions. Therefore, we present a new DAL platform ALScope for classification tasks, integrating 10 datasets from computer vision (CV) and natural language processing (NLP), and 21 representative DAL algorithms, including both classical baselines and recent approaches designed to handle challenges such as distribution shifts and data imbalance. This platform supports flexible configuration of key experimental factors, ranging from algorithm and dataset choices to task-specific factors like out-of-distribution (OOD) sample ratio, and class imbalance ratio, enabling comprehensive and realistic evaluation. We conduct extensive experiments on this platform under various settings. Our findings show that: (1) DAL algorithms' performance varies significantly across domains and task settings; (2) in non-standard scenarios such as imbalanced and open-set settings, DAL algorithms show room for improvement and require further investigation; and (3) some algorithms achieve good performance, but require significantly longer selection time.
Decoupled Multimodal Prototypes for Visual Recognition with Missing Modalities
May 13, 2025



Multimodal learning enhances deep learning models by enabling them to perceive and understand information from multiple data modalities, such as visual and textual inputs. However, most existing approaches assume the availability of all modalities, an assumption that often fails in real-world applications. Recent works have introduced learnable missing-case-aware prompts to mitigate performance degradation caused by missing modalities while reducing the need for extensive model fine-tuning. Building upon the effectiveness of missing-case-aware handling for missing modalities, we propose a novel decoupled prototype-based output head, which leverages missing-case-aware class-wise prototypes tailored for each individual modality. This approach dynamically adapts to different missing modality scenarios and can be seamlessly integrated with existing prompt-based methods. Extensive experiments demonstrate that our proposed output head significantly improves performance across a wide range of missing-modality scenarios and varying missing rates.
CGMatch: A Different Perspective of Semi-supervised Learning
Mar 04, 2025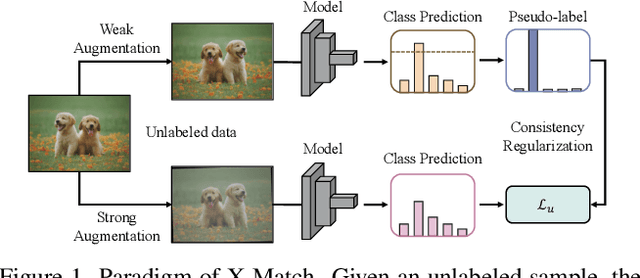
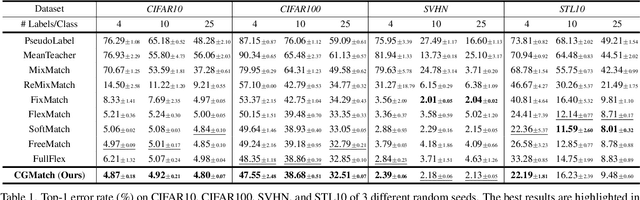
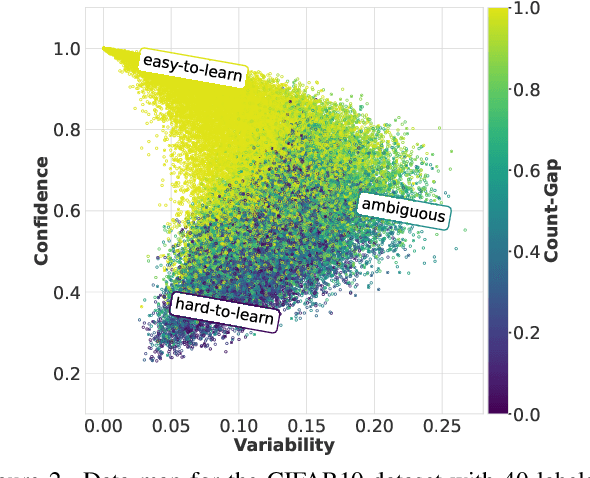

Semi-supervised learning (SSL) has garnered significant attention due to its ability to leverage limited labeled data and a large amount of unlabeled data to improve model generalization performance. Recent approaches achieve impressive successes by combining ideas from both consistency regularization and pseudo-labeling. However, these methods tend to underperform in the more realistic situations with relatively scarce labeled data. We argue that this issue arises because existing methods rely solely on the model's confidence, making them challenging to accurately assess the model's state and identify unlabeled examples contributing to the training phase when supervision information is limited, especially during the early stages of model training. In this paper, we propose a novel SSL model called CGMatch, which, for the first time, incorporates a new metric known as Count-Gap (CG). We demonstrate that CG is effective in discovering unlabeled examples beneficial for model training. Along with confidence, a commonly used metric in SSL, we propose a fine-grained dynamic selection (FDS) strategy. This strategy dynamically divides the unlabeled dataset into three subsets with different characteristics: easy-to-learn set, ambiguous set, and hard-to-learn set. By selective filtering subsets, and applying corresponding regularization with selected subsets, we mitigate the negative impact of incorrect pseudo-labels on model optimization and generalization. Extensive experimental results on several common SSL benchmarks indicate the effectiveness of CGMatch especially when the labeled data are particularly limited. Source code is available at https://github.com/BoCheng-96/CGMatch.
Multi-Label Bayesian Active Learning with Inter-Label Relationships
Nov 26, 2024The primary challenge of multi-label active learning, differing it from multi-class active learning, lies in assessing the informativeness of an indefinite number of labels while also accounting for the inherited label correlation. Existing studies either require substantial computational resources to leverage correlations or fail to fully explore label dependencies. Additionally, real-world scenarios often require addressing intrinsic biases stemming from imbalanced data distributions. In this paper, we propose a new multi-label active learning strategy to address both challenges. Our method incorporates progressively updated positive and negative correlation matrices to capture co-occurrence and disjoint relationships within the label space of annotated samples, enabling a holistic assessment of uncertainty rather than treating labels as isolated elements. Furthermore, alongside diversity, our model employs ensemble pseudo labeling and beta scoring rules to address data imbalances. Extensive experiments on four realistic datasets demonstrate that our strategy consistently achieves more reliable and superior performance, compared to several established methods.
Neural Topic Modeling with Large Language Models in the Loop
Nov 13, 2024Topic modeling is a fundamental task in natural language processing, allowing the discovery of latent thematic structures in text corpora. While Large Language Models (LLMs) have demonstrated promising capabilities in topic discovery, their direct application to topic modeling suffers from issues such as incomplete topic coverage, misalignment of topics, and inefficiency. To address these limitations, we propose LLM-ITL, a novel LLM-in-the-loop framework that integrates LLMs with many existing Neural Topic Models (NTMs). In LLM-ITL, global topics and document representations are learned through the NTM, while an LLM refines the topics via a confidence-weighted Optimal Transport (OT)-based alignment objective. This process enhances the interpretability and coherence of the learned topics, while maintaining the efficiency of NTMs. Extensive experiments demonstrate that LLM-ITL can help NTMs significantly improve their topic interpretability while maintaining the quality of document representation.
DiffX: Guide Your Layout to Cross-Modal Generative Modeling
Jul 28, 2024


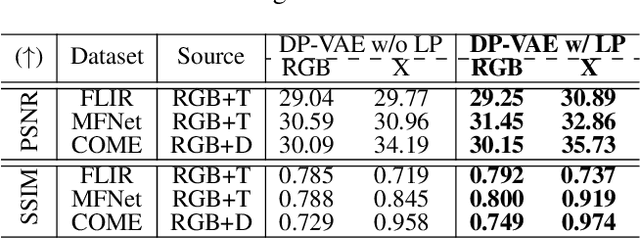
Diffusion models have made significant strides in language-driven and layout-driven image generation. However, most diffusion models are limited to visible RGB image generation. In fact, human perception of the world is enriched by diverse viewpoints, including chromatic contrast, thermal illumination, and depth information. In this paper, we introduce a novel diffusion model for general layout-guided cross-modal ``RGB+X'' generation, called DiffX. Firstly, we construct the cross-modal image datasets with text description by using LLaVA for image captioning, supplemented by manual corrections. Notably, DiffX presents a simple yet effective cross-modal generative modeling pipeline, which conducts diffusion and denoising processes in the modality-shared latent space, facilitated by our Dual Path Variational AutoEncoder (DP-VAE). Moreover, we introduce the joint-modality embedder, which incorporates a gated cross-attention mechanism to link layout and text conditions. Meanwhile, the advanced Long-CLIP is employed for long caption embedding to improve user guidance. Through extensive experiments, DiffX demonstrates robustness and flexibility in cross-modal generation across three RGB+X datasets: FLIR, MFNet, and COME15K, guided by various layout types. It also shows the potential for adaptive generation of ``RGB+X+Y'' or more diverse modalities. Our code and constructed cross-modal image datasets are available at https://github.com/zeyuwang-zju/DiffX.
LLM Reading Tea Leaves: Automatically Evaluating Topic Models with Large Language Models
Jun 13, 2024



Topic modeling has been a widely used tool for unsupervised text analysis. However, comprehensive evaluations of a topic model remain challenging. Existing evaluation methods are either less comparable across different models (e.g., perplexity) or focus on only one specific aspect of a model (e.g., topic quality or document representation quality) at a time, which is insufficient to reflect the overall model performance. In this paper, we propose WALM (Words Agreement with Language Model), a new evaluation method for topic modeling that comprehensively considers the semantic quality of document representations and topics in a joint manner, leveraging the power of large language models (LLMs). With extensive experiments involving different types of topic models, WALM is shown to align with human judgment and can serve as a complementary evaluation method to the existing ones, bringing a new perspective to topic modeling. Our software package will be available at https://github.com/Xiaohao-Yang/Topic_Model_Evaluation, which can be integrated with many widely used topic models.
MTS-Net: Dual-Enhanced Positional Multi-Head Self-Attention for 3D CT Diagnosis of May-Thurner Syndrome
Jun 07, 2024May-Thurner Syndrome (MTS), also known as iliac vein compression syndrome or Cockett's syndrome, is a condition potentially impacting over 20 percent of the population, leading to an increased risk of iliofemoral deep venous thrombosis. In this paper, we present a 3D-based deep learning approach called MTS-Net for diagnosing May-Thurner Syndrome using CT scans. To effectively capture the spatial-temporal relationship among CT scans and emulate the clinical process of diagnosing MTS, we propose a novel attention module called the dual-enhanced positional multi-head self-attention (DEP-MHSA). The proposed DEP-MHSA reconsiders the role of positional embedding and incorporates a dual-enhanced positional embedding in both attention weights and residual connections. Further, we establish a new dataset, termed MTS-CT, consisting of 747 subjects. Experimental results demonstrate that our proposed approach achieves state-of-the-art MTS diagnosis results, and our self-attention design facilitates the spatial-temporal modeling. We believe that our DEP-MHSA is more suitable to handle CT image sequence modeling and the proposed dataset enables future research on MTS diagnosis. We make our code and dataset publicly available at: https://github.com/Nutingnon/MTS_dep_mhsa.