 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automated SAM for Single-source Domain Generalization in Medical Image Segmentation
Jul 23, 2025Although SAM-based single-source domain generalization models for medical image segmentation can mitigate the impact of domain shift on the model in cross-domain scenarios, these models still face two major challenges. First, the segmentation of SAM is highly dependent on domain-specific expert-annotated prompts, which prevents SAM from achieving fully automated medical image segmentation and therefore limits its application in clinical settings. Second, providing poor prompts (such as bounding boxes that are too small or too large) to the SAM prompt encoder can mislead SAM into generating incorrect mask results. Therefore, we propose the FA-SAM, a single-source domain generalization framework for medical image segmentation that achieves fully automated SAM. FA-SAM introduces two key innovations: an Auto-prompted Generation Model (AGM) branch equipped with a Shallow Feature Uncertainty Modeling (SUFM) module, and an Image-Prompt Embedding Fusion (IPEF) module integrated into the SAM mask decoder. Specifically, AGM models the uncertainty distribution of shallow features through the SUFM module to generate bounding box prompts for the target domain, enabling fully automated segmentation with SAM. The IPEF module integrates multiscale information from SAM image embeddings and prompt embeddings to capture global and local details of the target object, enabling SAM to mitigate the impact of poor prompts. Extensive experiments on publicly available prostate and fundus vessel datasets validate the effectiveness of FA-SAM and highlight its potential to address the above challenges.
Correlative and Discriminative Label Grouping for Multi-Label Visual Prompt Tuning
Apr 14, 2025Modeling label correlations has always played a pivotal role in multi-label image classification (MLC), attracting significant attention from researchers. However, recent studies have overemphasized co-occurrence relationships among labels, which can lead to overfitting risk on this overemphasis, resulting in suboptimal models. To tackle this problem, we advocate for balancing correlative and discriminative relationships among labels to mitigate the risk of overfitting and enhance model performance. To this end, we propose the Multi-Label Visual Prompt Tuning framework, a novel and parameter-efficient method that groups classes into multiple class subsets according to label co-occurrence and mutual exclusivity relationships, and then models them respectively to balance the two relationships. In this work, since each group contains multiple classes, multiple prompt tokens are adopted within Vision Transformer (ViT) to capture the correlation or discriminative label relationship within each group, and effectively learn correlation or discriminative representations for class subsets. On the other hand, each group contains multiple group-aware visual representations that may correspond to multiple classes, and the mixture of experts (MoE) model can cleverly assign them from the group-aware to the label-aware, adaptively obtaining label-aware representation, which is more conducive to classification. Experiments on multiple benchmark datasets show that our proposed approach achieves competitive results and outperforms SOTA methods on multiple pre-trained models.
CGMatch: A Different Perspective of Semi-supervised Learning
Mar 04, 2025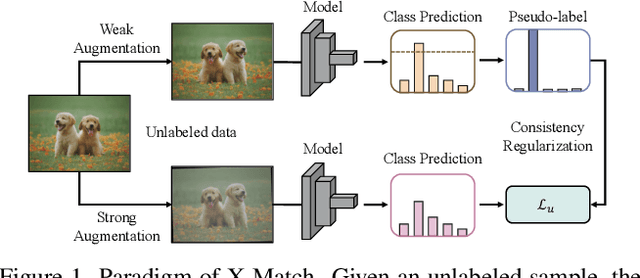
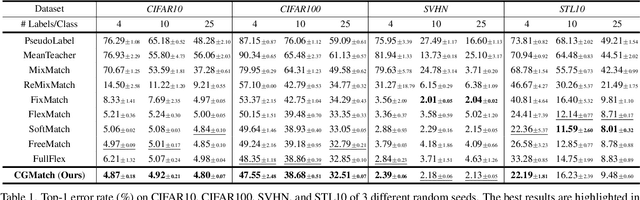
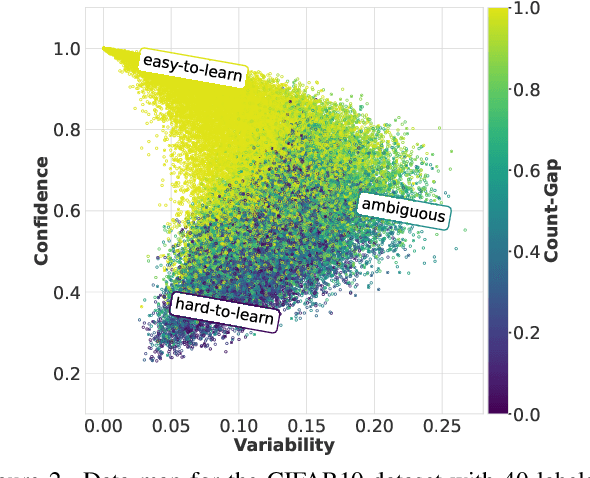

Semi-supervised learning (SSL) has garnered significant attention due to its ability to leverage limited labeled data and a large amount of unlabeled data to improve model generalization performance. Recent approaches achieve impressive successes by combining ideas from both consistency regularization and pseudo-labeling. However, these methods tend to underperform in the more realistic situations with relatively scarce labeled data. We argue that this issue arises because existing methods rely solely on the model's confidence, making them challenging to accurately assess the model's state and identify unlabeled examples contributing to the training phase when supervision information is limited, especially during the early stages of model training. In this paper, we propose a novel SSL model called CGMatch, which, for the first time, incorporates a new metric known as Count-Gap (CG). We demonstrate that CG is effective in discovering unlabeled examples beneficial for model training. Along with confidence, a commonly used metric in SSL, we propose a fine-grained dynamic selection (FDS) strategy. This strategy dynamically divides the unlabeled dataset into three subsets with different characteristics: easy-to-learn set, ambiguous set, and hard-to-learn set. By selective filtering subsets, and applying corresponding regularization with selected subsets, we mitigate the negative impact of incorrect pseudo-labels on model optimization and generalization. Extensive experimental results on several common SSL benchmarks indicate the effectiveness of CGMatch especially when the labeled data are particularly limited. Source code is available at https://github.com/BoCheng-96/CGMatch.
A new framework for X-ray absorption spectroscopy data analysis based on machine learning: XASDAML
Feb 23, 2025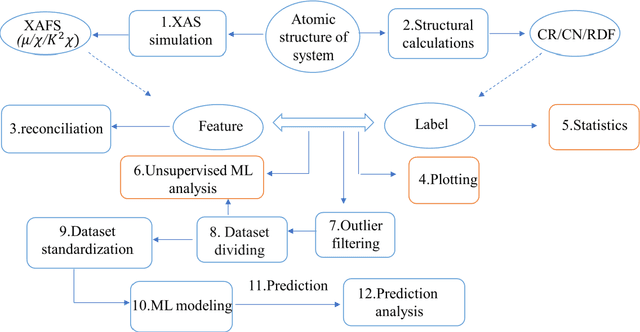
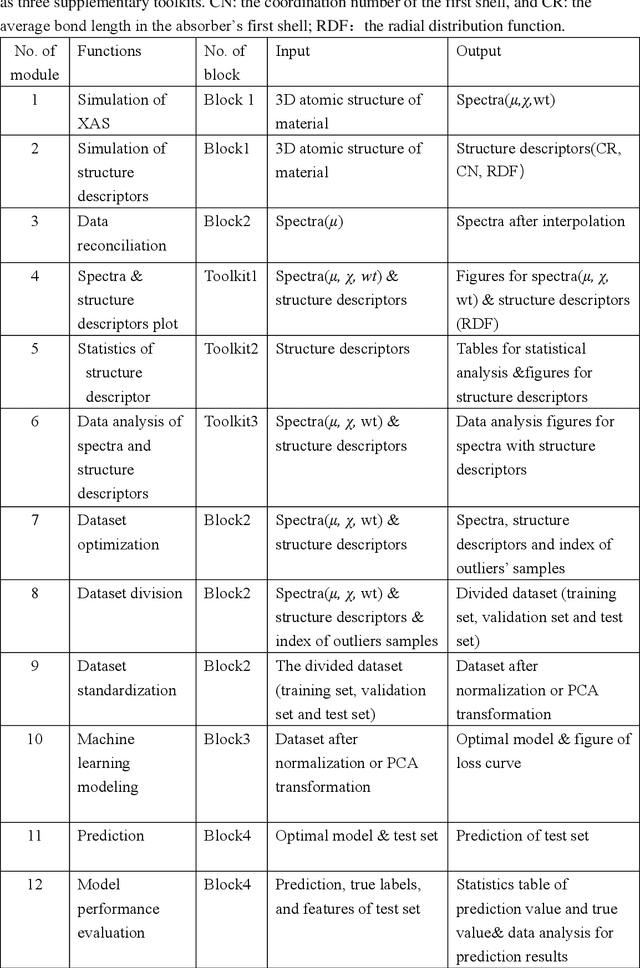

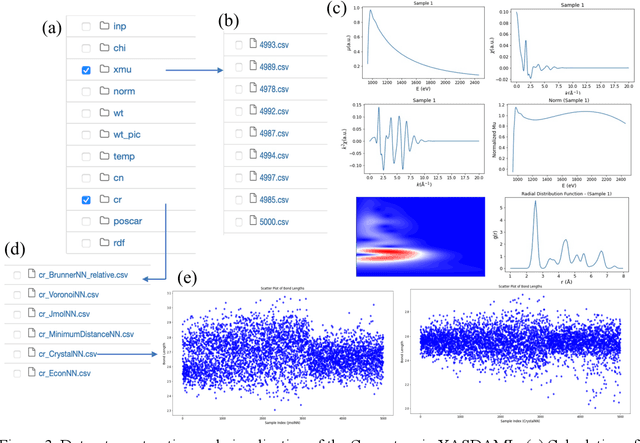
X-ray absorption spectroscopy (XAS) is a powerful technique to probe the electronic and structural properties of materials. With the rapid growth in both the volume and complexity of XAS datasets driven by advancements in synchrotron radiation facilities, there is an increasing demand for advanced computational tools capable of efficiently analyzing large-scale data. To address these needs, we introduce XASDAML,a flexible, machine learning based framework that integrates the entire data-processing workflow-including dataset construction for spectra and structural descriptors, data filtering, ML modeling, prediction, and model evaluation-into a unified platform. Additionally, it supports comprehensive statistical analysis, leveraging methods such as principal component analysis and clustering to reveal potential patterns and relationships within large datasets. Each module operates independently, allowing users to modify or upgrade modules in response to evolving research needs or technological advances. Moreover, the platform provides a user-friendly interface via Jupyter Notebook, making it accessible to researchers at varying levels of expertise. The versatility and effectiveness of XASDAML are exemplified by its application to a copper dataset, where it efficiently manages large and complex data, supports both supervised and unsupervised machine learning models, provides comprehensive statistics for structural descriptors, generates spectral plots, and accurately predicts coordination numbers and bond lengths. Furthermore, the platform streamlining the integration of XAS with machine learning and lowering the barriers to entry for new users.
Bidirectional Uncertainty-Aware Region Learning for Semi-Supervised Medical Image Segmentation
Feb 11, 2025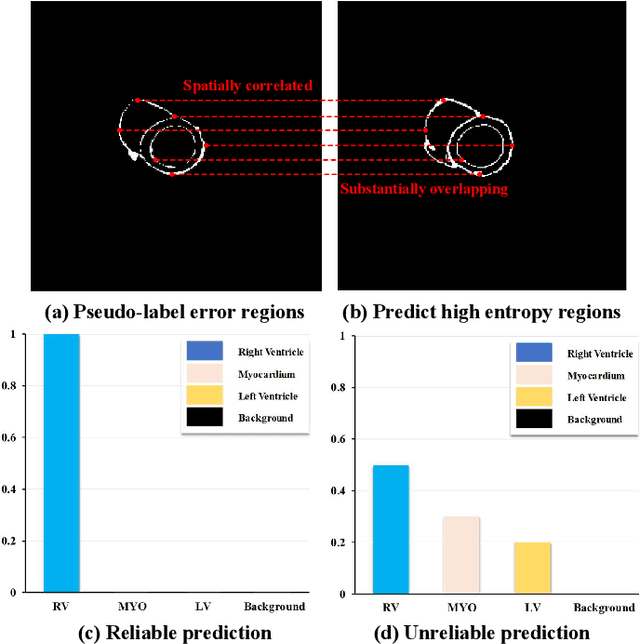
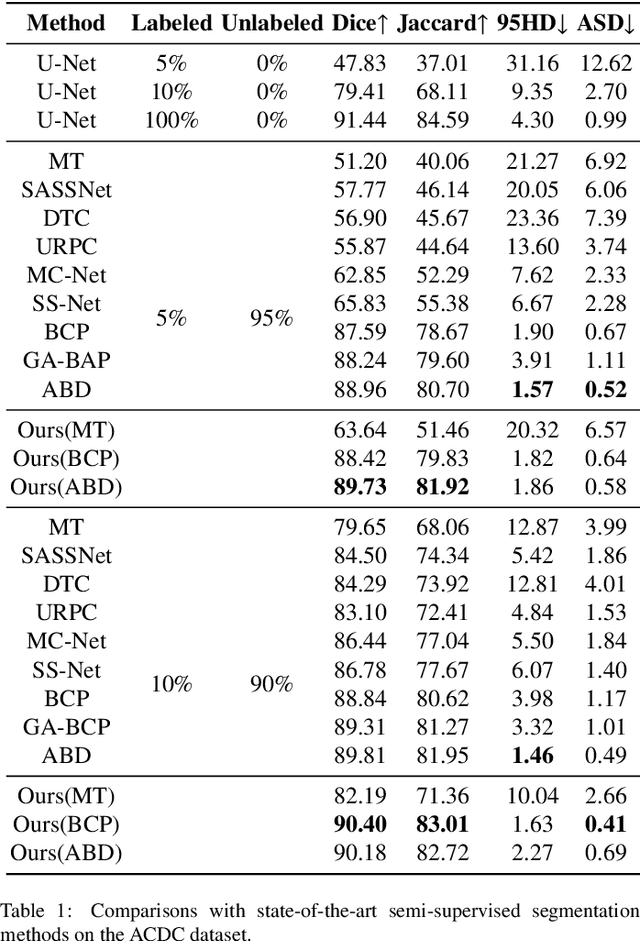
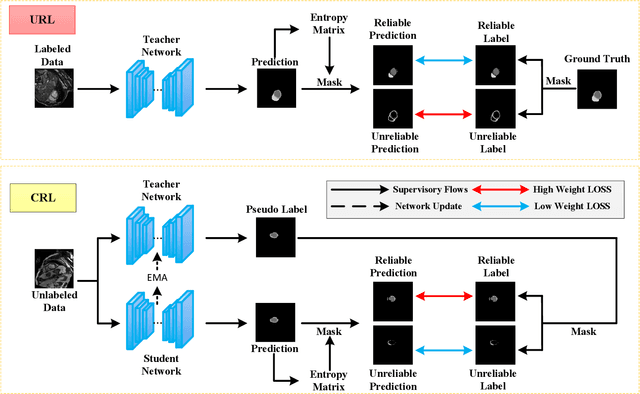
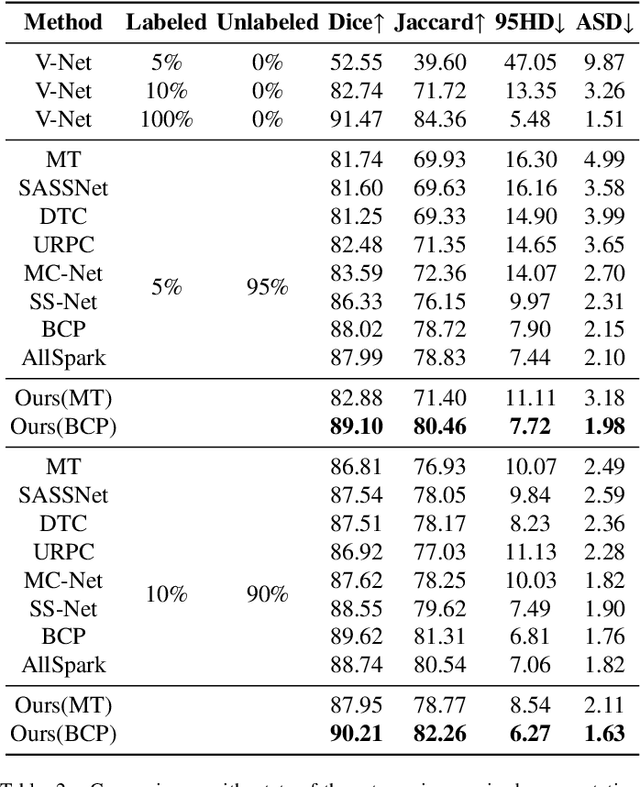
In semi-supervised medical image segmentation, the poor quality of unlabeled data and the uncertainty in the model's predictions lead to models that inevitably produce erroneous pseudo-labels. These errors accumulate throughout model training, thereby weakening the model's performance. We found that these erroneous pseudo-labels are typically concentrated in high-uncertainty regions. Traditional methods improve performance by directly discarding pseudo-labels in these regions, but this can also result in neglecting potentially valuable training data. To alleviate this problem, we propose a bidirectional uncertainty-aware region learning strategy. In training labeled data, we focus on high-uncertainty regions, using precise label information to guide the model's learning in potentially uncontrollable areas. Meanwhile, in the training of unlabeled data, we concentrate on low-uncertainty regions to reduce the interference of erroneous pseudo-labels on the model. Through this bidirectional learning strategy, the model's overall performance has significantly improved. Extensive experiments show that our proposed method achieves significant performance improvement on different medical image segmentation tasks.
Dynamic Prompt Adjustment for Multi-Label Class-Incremental Learning
Jan 03, 2025



Significant advancements have been made in single label incremental learning (SLCIL),yet the more practical and challenging multi label class incremental learning (MLCIL) remains understudied. Recently,visual language models such as CLIP have achieved good results in classification tasks. However,directly using CLIP to solve MLCIL issue can lead to catastrophic forgetting. To tackle this issue, we integrate an improved data replay mechanism and prompt loss to curb knowledge forgetting. Specifically,our model enhances the prompt information to better adapt to multi-label classification tasks and employs confidence-based replay strategy to select representative samples. Moreover, the prompt loss significantly reduces the model's forgetting of previous knowledge. Experimental results demonstrate that our method has substantially improved the performance of MLCIL tasks across multiple benchmark datasets,validating its effectiveness.
Domain Adaptive Lung Nodule Detection in X-ray Image
Jul 28, 2024Medical images from different healthcare centers exhibit varied data distributions, posing significant challenges for adapting lung nodule detection due to the domain shift between training and application phases. Traditional unsupervised domain adaptive detection methods often struggle with this shift, leading to suboptimal outcomes. To overcome these challenges, we introduce a novel domain adaptive approach for lung nodule detection that leverages mean teacher self-training and contrastive learning. First, we propose a hierarchical contrastive learning strategy to refine nodule representations and enhance the distinction between nodules and background. Second, we introduce a nodule-level domain-invariant feature learning (NDL) module to capture domain-invariant features through adversarial learning across different domains. Additionally, we propose a new annotated dataset of X-ray images to aid in advancing lung nodule detection research. Extensive experiments conducted on multiple X-ray datasets demonstrate the efficacy of our approach in mitigating domain shift impacts.
Text-Region Matching for Multi-Label Image Recognition with Missing Labels
Jul 26, 2024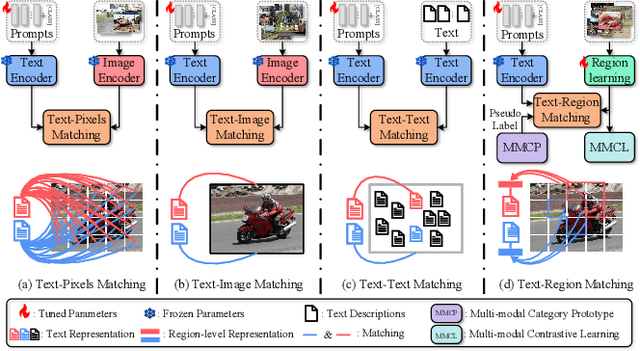
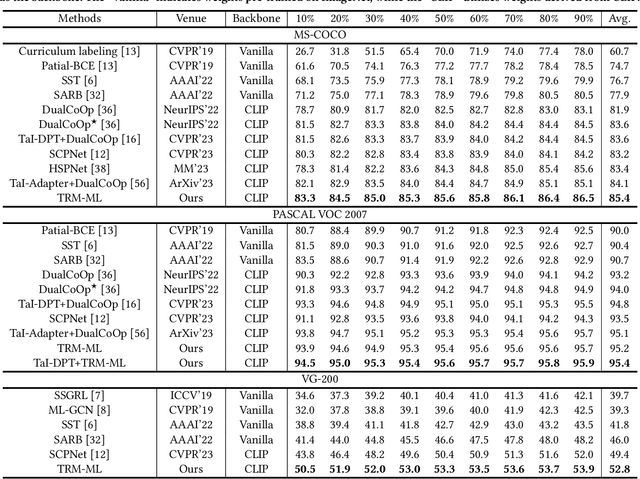
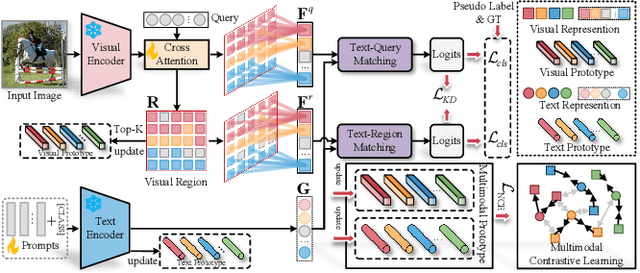
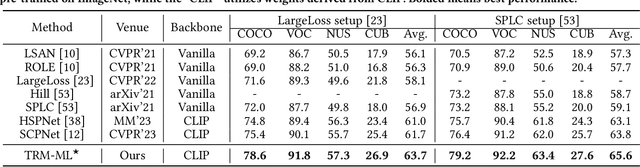
Recently, large-scale visual language pre-trained (VLP) models have demonstrated impressive performance across various downstream tasks. Motivated by these advancements, pioneering efforts have emerged in multi-label image recognition with missing labels, leveraging VLP prompt-tuning technology. However, they usually cannot match text and vision features well, due to complicated semantics gaps and missing labels in a multi-label image. To tackle this challenge, we propose \textbf{T}ext-\textbf{R}egion \textbf{M}atching for optimizing \textbf{M}ulti-\textbf{L}abel prompt tuning, namely TRM-ML, a novel method for enhancing meaningful cross-modal matching. Compared to existing methods, we advocate exploring the information of category-aware regions rather than the entire image or pixels, which contributes to bridging the semantic gap between textual and visual representations in a one-to-one matching manner. Concurrently, we further introduce multimodal contrastive learning to narrow the semantic gap between textual and visual modalities and establish intra-class and inter-class relationships. Additionally, to deal with missing labels, we propose a multimodal category prototype that leverages intra- and inter-category semantic relationships to estimate unknown labels, facilitating pseudo-label generation. Extensive experiments on the MS-COCO, PASCAL VOC, Visual Genome, NUS-WIDE, and CUB-200-211 benchmark datasets demonstrate that our proposed framework outperforms the state-of-the-art methods by a significant margin. Our code is available here\href{https://github.com/yu-gi-oh-leilei/TRM-ML}{\raisebox{-1pt}{\faGithub}}.
Semantics Guided Disentangled GAN for Chest X-ray Image Rib Segmentation
Jul 22, 2024The label annotations for chest X-ray image rib segmentation are time consuming and laborious, and the labeling quality heavily relies on medical knowledge of annotators. To reduce the dependency on annotated data, existing works often utilize generative adversarial network (GAN) to generate training data. However, GAN-based methods overlook the nuanced information specific to individual organs, which degrades the generation quality of chest X-ray image. Hence, we propose a novel Semantics guided Disentangled GAN (SD-GAN), which can generate the high-quality training data by fully utilizing the semantic information of different organs, for chest X-ray image rib segmentation. In particular, we use three ResNet50 branches to disentangle features of different organs, then use a decoder to combine features and generate corresponding images. To ensure that the generated images correspond to the input organ labels in semantics tags, we employ a semantics guidance module to perform semantic guidance on the generated images. To evaluate the efficacy of SD-GAN in generating high-quality samples, we introduce modified TransUNet(MTUNet), a specialized segmentation network designed for multi-scale contextual information extracting and multi-branch decoding, effectively tackling the challenge of organ overlap. We also propose a new chest X-ray image dataset (CXRS). It includes 1250 samples from various medical institutions. Lungs, clavicles, and 24 ribs are simultaneously annotated on each chest X-ray image. The visualization and quantitative results demonstrate the efficacy of SD-GAN in generating high-quality chest X-ray image-mask pairs. Using generated data, our trained MTUNet overcomes the limitations of the data scale and outperforms other segmentation networks.
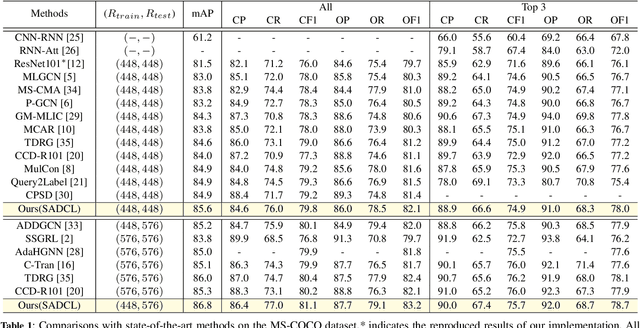
Semantic-Aware Dual Contrastive Learning for Multi-label Image Classification
Jul 27, 2023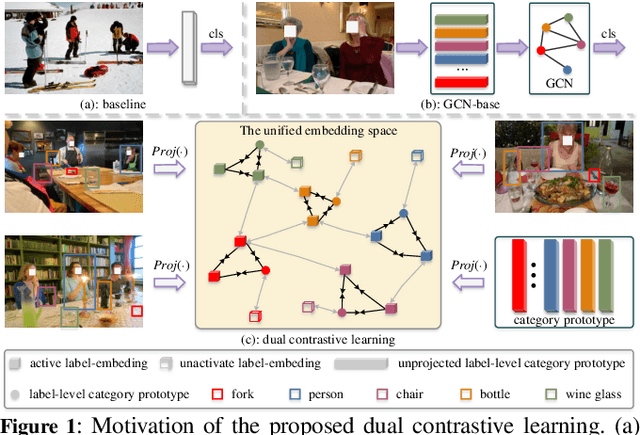
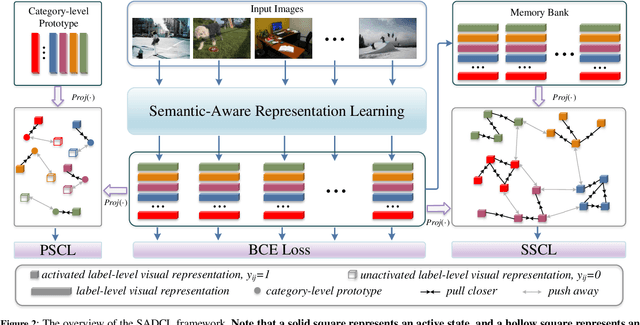
Extracting image semantics effectively and assigning corresponding labels to multiple objects or attributes for natural images is challenging due to the complex scene contents and confusing label dependencies. Recent works have focused on modeling label relationships with graph and understanding object regions using class activation maps (CAM). However, these methods ignore the complex intra- and inter-category relationships among specific semantic features, and CAM is prone to generate noisy information. To this end, we propose a novel semantic-aware dual contrastive learning framework that incorporates sample-to-sample contrastive learning (SSCL) as well as prototype-to-sample contrastive learning (PSCL). Specifically, we leverage semantic-aware representation learning to extract category-related local discriminative features and construct category prototypes. Then based on SSCL, label-level visual representations of the same category are aggregated together, and features belonging to distinct categories are separated. Meanwhile, we construct a novel PSCL module to narrow the distance between positive samples and category prototypes and push negative samples away from the corresponding category prototypes. Finally, the discriminative label-level features related to the image content are accurately captured by the joint training of the above three parts. Experiments on five challenging large-scale public datasets demonstrate that our proposed method is effective and outperforms the state-of-the-art methods. Code and supplementary materials are released on https://github.com/yu-gi-oh-leilei/SADCL.