 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automated SAM for Single-source Domain Generalization in Medical Image Segmentation
Jul 23, 2025Although SAM-based single-source domain generalization models for medical image segmentation can mitigate the impact of domain shift on the model in cross-domain scenarios, these models still face two major challenges. First, the segmentation of SAM is highly dependent on domain-specific expert-annotated prompts, which prevents SAM from achieving fully automated medical image segmentation and therefore limits its application in clinical settings. Second, providing poor prompts (such as bounding boxes that are too small or too large) to the SAM prompt encoder can mislead SAM into generating incorrect mask results. Therefore, we propose the FA-SAM, a single-source domain generalization framework for medical image segmentation that achieves fully automated SAM. FA-SAM introduces two key innovations: an Auto-prompted Generation Model (AGM) branch equipped with a Shallow Feature Uncertainty Modeling (SUFM) module, and an Image-Prompt Embedding Fusion (IPEF) module integrated into the SAM mask decoder. Specifically, AGM models the uncertainty distribution of shallow features through the SUFM module to generate bounding box prompts for the target domain, enabling fully automated segmentation with SAM. The IPEF module integrates multiscale information from SAM image embeddings and prompt embeddings to capture global and local details of the target object, enabling SAM to mitigate the impact of poor prompts. Extensive experiments on publicly available prostate and fundus vessel datasets validate the effectiveness of FA-SAM and highlight its potential to address the above challenges.
Towards Large-scale Generative Ranking
May 08, 2025
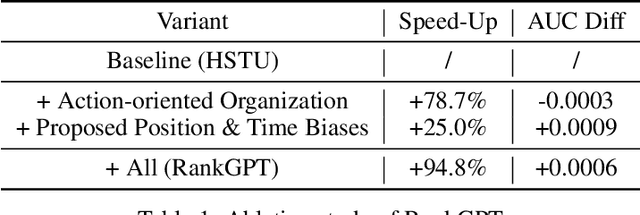
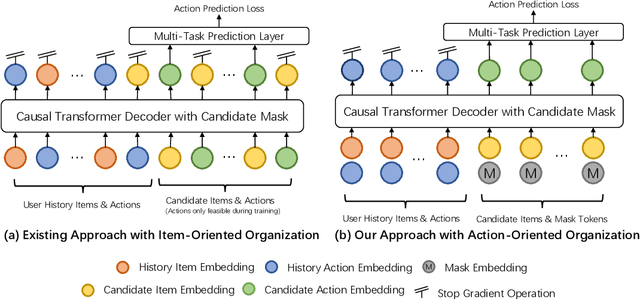

Generative recommendation has recently emerged as a promising paradigm in information retrieval. However, generative ranking systems are still understudied, particularly with respect to their effectiveness and feasibility in large-scale industrial settings. This paper investigates this topic at the ranking stage of Xiaohongshu's Explore Feed, a recommender system that serves hundreds of millions of users. Specifically, we first examine how generative ranking outperforms current industrial recommenders. Through theoretical and empirical analyses, we find that the primary improvement in effectiveness stems from the generative architecture, rather than the training paradigm. To facilitate efficient deployment of generative ranking, we introduce GenRank, a novel generative architecture for ranking. We validate the effectiveness and efficiency of our solution through online A/B experiments. The results show that GenRank achieves significant improvements in user satisfaction with nearly equivalent computational resources compared to the existing production system.
Dynamic Prompt Adjustment for Multi-Label Class-Incremental Learning
Jan 03, 2025



Significant advancements have been made in single label incremental learning (SLCIL),yet the more practical and challenging multi label class incremental learning (MLCIL) remains understudied. Recently,visual language models such as CLIP have achieved good results in classification tasks. However,directly using CLIP to solve MLCIL issue can lead to catastrophic forgetting. To tackle this issue, we integrate an improved data replay mechanism and prompt loss to curb knowledge forgetting. Specifically,our model enhances the prompt information to better adapt to multi-label classification tasks and employs confidence-based replay strategy to select representative samples. Moreover, the prompt loss significantly reduces the model's forgetting of previous knowledge. Experimental results demonstrate that our method has substantially improved the performance of MLCIL tasks across multiple benchmark datasets,validating its effectiveness.
Domain Adaptive Lung Nodule Detection in X-ray Image
Jul 28, 2024Medical images from different healthcare centers exhibit varied data distributions, posing significant challenges for adapting lung nodule detection due to the domain shift between training and application phases. Traditional unsupervised domain adaptive detection methods often struggle with this shift, leading to suboptimal outcomes. To overcome these challenges, we introduce a novel domain adaptive approach for lung nodule detection that leverages mean teacher self-training and contrastive learning. First, we propose a hierarchical contrastive learning strategy to refine nodule representations and enhance the distinction between nodules and background. Second, we introduce a nodule-level domain-invariant feature learning (NDL) module to capture domain-invariant features through adversarial learning across different domains. Additionally, we propose a new annotated dataset of X-ray images to aid in advancing lung nodule detection research. Extensive experiments conducted on multiple X-ray datasets demonstrate the efficacy of our approach in mitigating domain shift impacts.
Text-Region Matching for Multi-Label Image Recognition with Missing Labels
Jul 26, 2024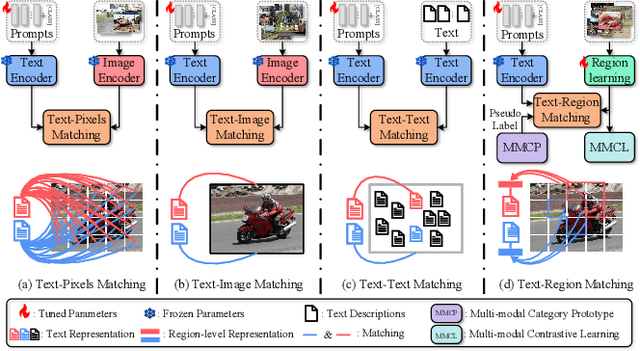
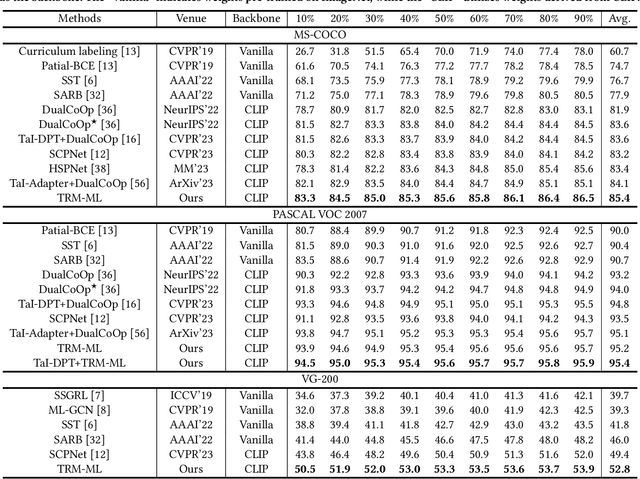
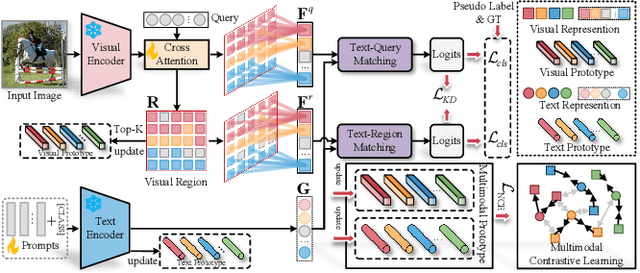
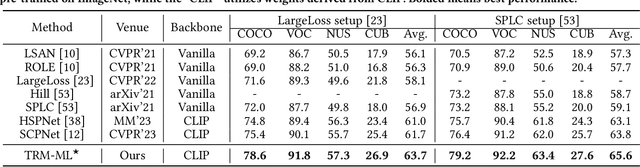
Recently, large-scale visual language pre-trained (VLP) models have demonstrated impressive performance across various downstream tasks. Motivated by these advancements, pioneering efforts have emerged in multi-label image recognition with missing labels, leveraging VLP prompt-tuning technology. However, they usually cannot match text and vision features well, due to complicated semantics gaps and missing labels in a multi-label image. To tackle this challenge, we propose \textbf{T}ext-\textbf{R}egion \textbf{M}atching for optimizing \textbf{M}ulti-\textbf{L}abel prompt tuning, namely TRM-ML, a novel method for enhancing meaningful cross-modal matching. Compared to existing methods, we advocate exploring the information of category-aware regions rather than the entire image or pixels, which contributes to bridging the semantic gap between textual and visual representations in a one-to-one matching manner. Concurrently, we further introduce multimodal contrastive learning to narrow the semantic gap between textual and visual modalities and establish intra-class and inter-class relationships. Additionally, to deal with missing labels, we propose a multimodal category prototype that leverages intra- and inter-category semantic relationships to estimate unknown labels, facilitating pseudo-label generation. Extensive experiments on the MS-COCO, PASCAL VOC, Visual Genome, NUS-WIDE, and CUB-200-211 benchmark datasets demonstrate that our proposed framework outperforms the state-of-the-art methods by a significant margin. Our code is available here\href{https://github.com/yu-gi-oh-leilei/TRM-ML}{\raisebox{-1pt}{\faGithub}}.
SpliceMix: A Cross-scale and Semantic Blending Augmentation Strategy for Multi-label Image Classification
Nov 26, 2023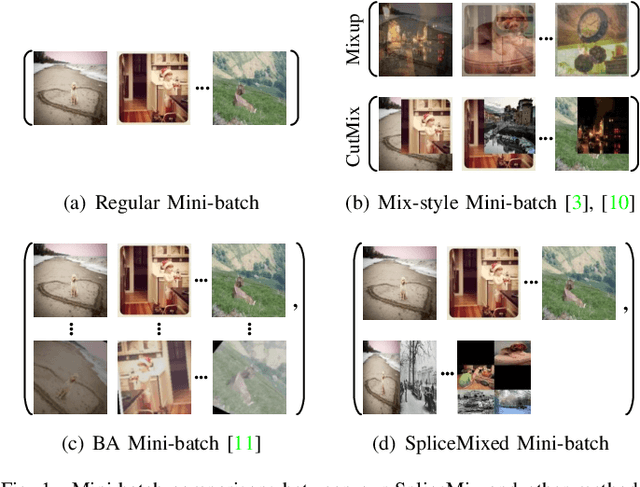
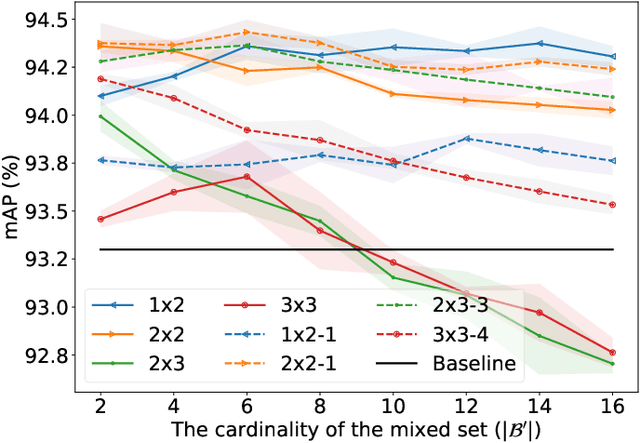
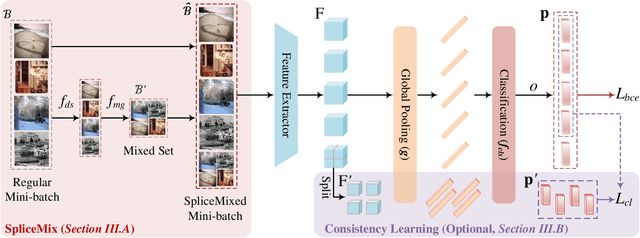

Recently, Mix-style data augmentation methods (e.g., Mixup and CutMix) have shown promising performance in various visual tasks. However, these methods are primarily designed for single-label images, ignoring the considerable discrepancies between single- and multi-label images, i.e., a multi-label image involves multiple co-occurred categories and fickle object scales. On the other hand, previous multi-label image classification (MLIC) methods tend to design elaborate models, bringing expensive computation. In this paper, we introduce a simple but effective augmentation strategy for multi-label image classification, namely SpliceMix. The "splice" in our method is two-fold: 1) Each mixed image is a splice of several downsampled images in the form of a grid, where the semantics of images attending to mixing are blended without object deficiencies for alleviating co-occurred bias; 2) We splice mixed images and the original mini-batch to form a new SpliceMixed mini-batch, which allows an image with different scales to contribute to training together. Furthermore, such splice in our SpliceMixed mini-batch enables interactions between mixed images and original regular images. We also offer a simple and non-parametric extension based on consistency learning (SpliceMix-CL) to show the flexible extensibility of our SpliceMix. Extensive experiments on various tasks demonstrate that only using SpliceMix with a baseline model (e.g., ResNet) achieves better performance than state-of-the-art methods. Moreover, the generalizability of our SpliceMix is further validated by the improvements in current MLIC methods when married with our SpliceMix. The code is available at https://github.com/zuiran/SpliceMix.
Semantic-Aware Dual Contrastive Learning for Multi-label Image Classification
Jul 27, 2023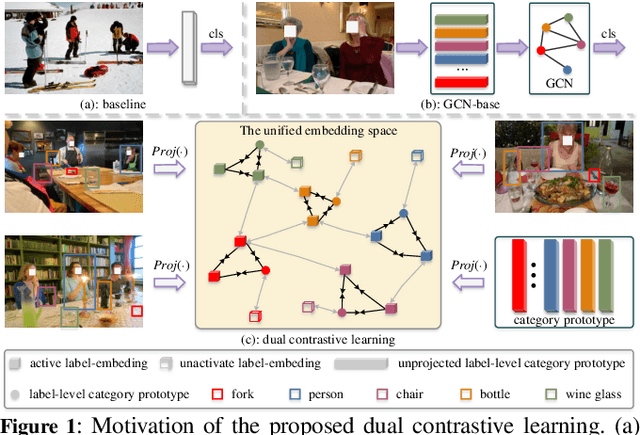
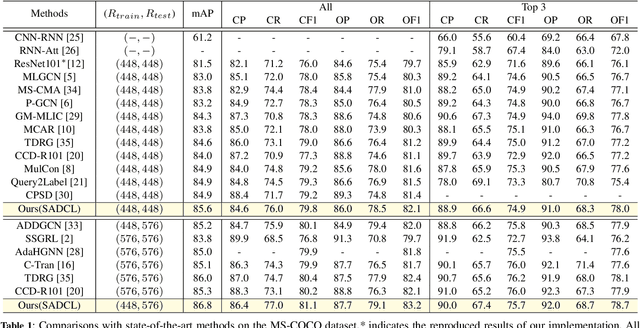
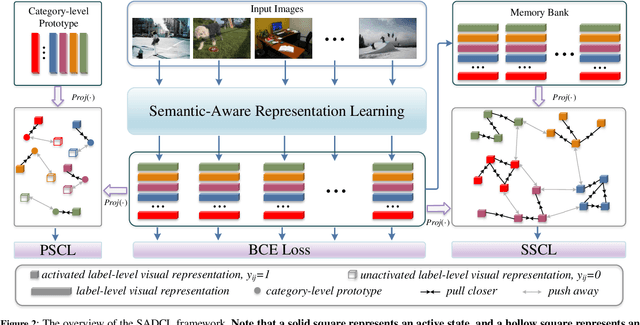
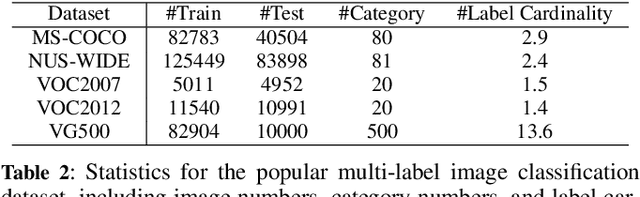
Extracting image semantics effectively and assigning corresponding labels to multiple objects or attributes for natural images is challenging due to the complex scene contents and confusing label dependencies. Recent works have focused on modeling label relationships with graph and understanding object regions using class activation maps (CAM). However, these methods ignore the complex intra- and inter-category relationships among specific semantic features, and CAM is prone to generate noisy information. To this end, we propose a novel semantic-aware dual contrastive learning framework that incorporates sample-to-sample contrastive learning (SSCL) as well as prototype-to-sample contrastive learning (PSCL). Specifically, we leverage semantic-aware representation learning to extract category-related local discriminative features and construct category prototypes. Then based on SSCL, label-level visual representations of the same category are aggregated together, and features belonging to distinct categories are separated. Meanwhile, we construct a novel PSCL module to narrow the distance between positive samples and category prototypes and push negative samples away from the corresponding category prototypes. Finally, the discriminative label-level features related to the image content are accurately captured by the joint training of the above three parts. Experiments on five challenging large-scale public datasets demonstrate that our proposed method is effective and outperforms the state-of-the-art methods. Code and supplementary materials are released on https://github.com/yu-gi-oh-leilei/SADCL.