 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGNet: Large-scale Reasoning-based Affordance Segmentation Benchmark towards General Grasping
Jul 31, 2025



General robotic grasping systems require accurate object affordance perception in diverse open-world scenarios following human instructions. However, current studies suffer from the problem of lacking reasoning-based large-scale affordance prediction data, leading to considerable concern about open-world effectiveness. To address this limitation, we build a large-scale grasping-oriented affordance segmentation benchmark with human-like instructions, named RAGNet. It contains 273k images, 180 categories, and 26k reasoning instructions. The images cover diverse embodied data domains, such as wild, robot, ego-centric, and even simulation data. They are carefully annotated with an affordance map, while the difficulty of language instructions is largely increased by removing their category name and only providing functional descriptions. Furthermore, we propose a comprehensive affordance-based grasping framework, named AffordanceNet, which consists of a VLM pre-trained on our massive affordance data and a grasping network that conditions an affordance map to grasp the target. Extensive experiments on affordance segmentation benchmarks and real-robot manipulation tasks show that our model has a powerful open-world generalization ability. Our data and code is available at https://github.com/wudongming97/AffordanceNet.
Fully Automated SAM for Single-source Domain Generalization in Medical Image Segmentation
Jul 23, 2025Although SAM-based single-source domain generalization models for medical image segmentation can mitigate the impact of domain shift on the model in cross-domain scenarios, these models still face two major challenges. First, the segmentation of SAM is highly dependent on domain-specific expert-annotated prompts, which prevents SAM from achieving fully automated medical image segmentation and therefore limits its application in clinical settings. Second, providing poor prompts (such as bounding boxes that are too small or too large) to the SAM prompt encoder can mislead SAM into generating incorrect mask results. Therefore, we propose the FA-SAM, a single-source domain generalization framework for medical image segmentation that achieves fully automated SAM. FA-SAM introduces two key innovations: an Auto-prompted Generation Model (AGM) branch equipped with a Shallow Feature Uncertainty Modeling (SUFM) module, and an Image-Prompt Embedding Fusion (IPEF) module integrated into the SAM mask decoder. Specifically, AGM models the uncertainty distribution of shallow features through the SUFM module to generate bounding box prompts for the target domain, enabling fully automated segmentation with SAM. The IPEF module integrates multiscale information from SAM image embeddings and prompt embeddings to capture global and local details of the target object, enabling SAM to mitigate the impact of poor prompts. Extensive experiments on publicly available prostate and fundus vessel datasets validate the effectiveness of FA-SAM and highlight its potential to address the above challenges.
TopoPoint: Enhance Topology Reasoning via Endpoint Detection in Autonomous Driving
May 23, 2025Topology reasoning, which unifies perception and structured reasoning, plays a vital role in understanding intersections for autonomous driving. However, its performance heavily relies on the accuracy of lane detection, particularly at connected lane endpoints. Existing methods often suffer from lane endpoints deviation, leading to incorrect topology construction. To address this issue, we propose TopoPoint, a novel framework that explicitly detects lane endpoints and jointly reasons over endpoints and lanes for robust topology reasoning. During training, we independently initialize point and lane query, and proposed Point-Lane Merge Self-Attention to enhance global context sharing through incorporating geometric distances between points and lanes as an attention mask . We further design Point-Lane Graph Convolutional Network to enable mutual feature aggregation between point and lane query. During inference, we introduce Point-Lane Geometry Matching algorithm that computes distances between detected points and lanes to refine lane endpoints, effectively mitigating endpoint deviation. Extensive experiments on the OpenLane-V2 benchmark demonstrate that TopoPoint achieves state-of-the-art performance in topology reasoning (48.8 on OLS). Additionally, we propose DET$_p$ to evaluate endpoint detection, under which our method significantly outperforms existing approaches (52.6 v.s. 45.2 on DET$_p$). The code is released at https://github.com/Franpin/TopoPoint.
Domain Adaptive Lung Nodule Detection in X-ray Image
Jul 28, 2024Medical images from different healthcare centers exhibit varied data distributions, posing significant challenges for adapting lung nodule detection due to the domain shift between training and application phases. Traditional unsupervised domain adaptive detection methods often struggle with this shift, leading to suboptimal outcomes. To overcome these challenges, we introduce a novel domain adaptive approach for lung nodule detection that leverages mean teacher self-training and contrastive learning. First, we propose a hierarchical contrastive learning strategy to refine nodule representations and enhance the distinction between nodules and background. Second, we introduce a nodule-level domain-invariant feature learning (NDL) module to capture domain-invariant features through adversarial learning across different domains. Additionally, we propose a new annotated dataset of X-ray images to aid in advancing lung nodule detection research. Extensive experiments conducted on multiple X-ray datasets demonstrate the efficacy of our approach in mitigating domain shift impacts.
Text-Region Matching for Multi-Label Image Recognition with Missing Labels
Jul 26, 2024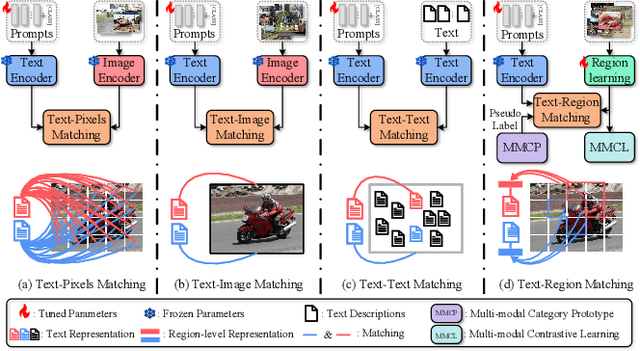
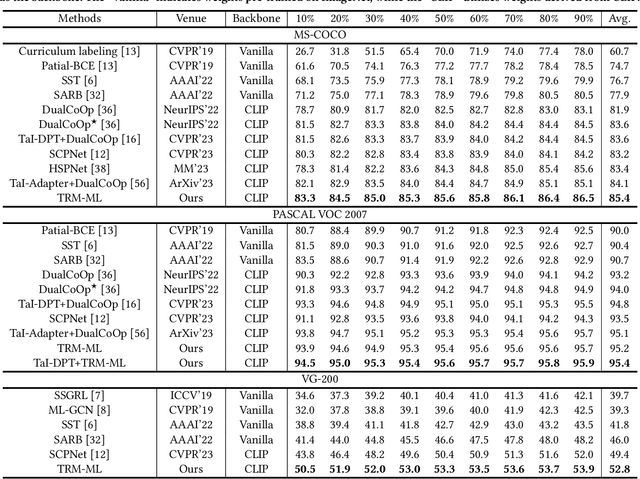
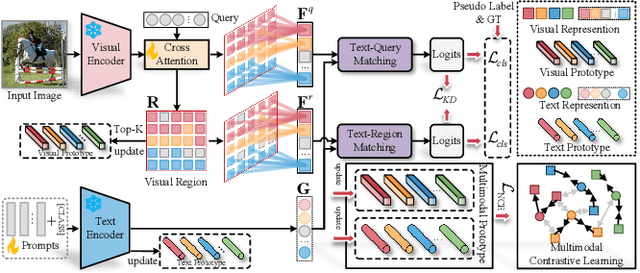
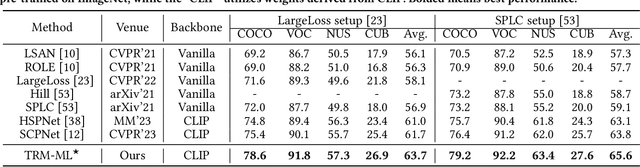
Recently, large-scale visual language pre-trained (VLP) models have demonstrated impressive performance across various downstream tasks. Motivated by these advancements, pioneering efforts have emerged in multi-label image recognition with missing labels, leveraging VLP prompt-tuning technology. However, they usually cannot match text and vision features well, due to complicated semantics gaps and missing labels in a multi-label image. To tackle this challenge, we propose \textbf{T}ext-\textbf{R}egion \textbf{M}atching for optimizing \textbf{M}ulti-\textbf{L}abel prompt tuning, namely TRM-ML, a novel method for enhancing meaningful cross-modal matching. Compared to existing methods, we advocate exploring the information of category-aware regions rather than the entire image or pixels, which contributes to bridging the semantic gap between textual and visual representations in a one-to-one matching manner. Concurrently, we further introduce multimodal contrastive learning to narrow the semantic gap between textual and visual modalities and establish intra-class and inter-class relationships. Additionally, to deal with missing labels, we propose a multimodal category prototype that leverages intra- and inter-category semantic relationships to estimate unknown labels, facilitating pseudo-label generation. Extensive experiments on the MS-COCO, PASCAL VOC, Visual Genome, NUS-WIDE, and CUB-200-211 benchmark datasets demonstrate that our proposed framework outperforms the state-of-the-art methods by a significant margin. Our code is available here\href{https://github.com/yu-gi-oh-leilei/TRM-ML}{\raisebox{-1pt}{\faGithub}}.
TopoLogic: An Interpretable Pipeline for Lane Topology Reasoning on Driving Scenes
May 23, 2024



As an emerging task that integrates perception and reasoning, topology reasoning in autonomous driving scenes has recently garnered widespread attention. However, existing work often emphasizes "perception over reasoning": they typically boost reasoning performance by enhancing the perception of lanes and directly adopt MLP to learn lane topology from lane query. This paradigm overlooks the geometric features intrinsic to the lanes themselves and are prone to being influenced by inherent endpoint shifts in lane detection. To tackle this issue, we propose an interpretable method for lane topology reasoning based on lane geometric distance and lane query similarity, named TopoLogic. This method mitigates the impact of endpoint shifts in geometric space, and introduces explicit similarity calculation in semantic space as a complement. By integrating results from both spaces, our methods provides more comprehensive information for lane topology. Ultimately, our approach significantly outperforms the existing state-of-the-art methods on the mainstream benchmark OpenLane-V2 (23.9 v.s. 10.9 in TOP$_{ll}$ and 44.1 v.s. 39.8 in OLS on subset_A. Additionally, our proposed geometric distance topology reasoning method can be incorporated into well-trained models without re-training, significantly boost the performance of lane topology reasoning. The code is released at https://github.com/Franpin/TopoLogic.
NeuralRoom: Geometry-Constrained Neural Implicit Surfaces for Indoor Scene Reconstruction
Oct 13, 2022


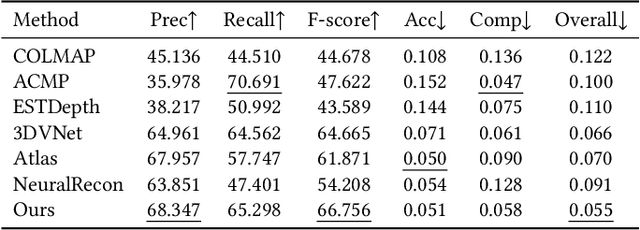
We present a novel neural surface reconstruction method called NeuralRoom for reconstructing room-sized indoor scenes directly from a set of 2D images. Recently, implicit neural representations have become a promising way to reconstruct surfaces from multiview images due to their high-quality results and simplicity. However, implicit neural representations usually cannot reconstruct indoor scenes well because they suffer severe shape-radiance ambiguity. We assume that the indoor scene consists of texture-rich and flat texture-less regions. In texture-rich regions, the multiview stereo can obtain accurate results. In the flat area, normal estimation networks usually obtain a good normal estimation. Based on the above observations, we reduce the possible spatial variation range of implicit neural surfaces by reliable geometric priors to alleviate shape-radiance ambiguity. Specifically, we use multiview stereo results to limit the NeuralRoom optimization space and then use reliable geometric priors to guide NeuralRoom training. Then the NeuralRoom would produce a neural scene representation that can render an image consistent with the input training images. In addition, we propose a smoothing method called perturbation-residual restrictions to improve the accuracy and completeness of the flat region, which assumes that the sampling points in a local surface should have the same normal and similar distance to the observation center. Experiments on the ScanNet dataset show that our method can reconstruct the texture-less area of indoor scenes while maintaining the accuracy of detail. We also apply NeuralRoom to more advanced multiview reconstruction algorithms and significantly improve their reconstruction quality.
DGECN: A Depth-Guided Edge Convolutional Network for End-to-End 6D Pose Estimation
Apr 21, 2022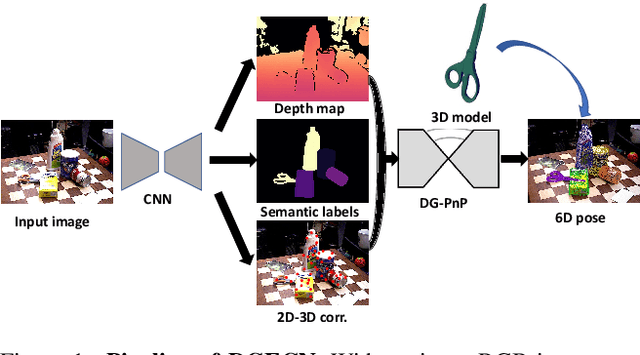
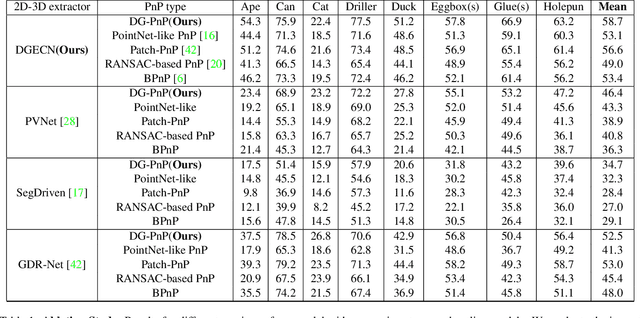
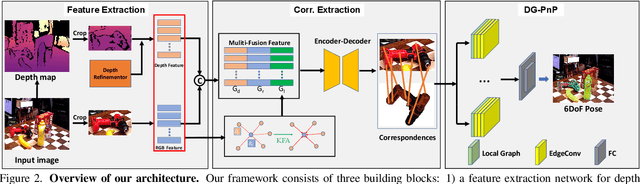
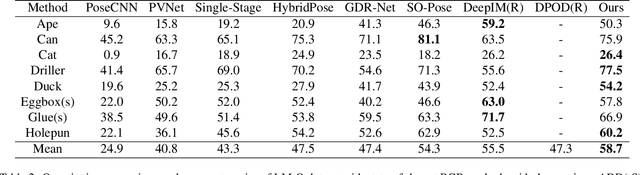
Monocular 6D pose estimation is a fundamental task in computer vision. Existing works often adopt a two-stage pipeline by establishing correspondences and utilizing a RANSAC algorithm to calculate 6 degrees-of-freedom (6DoF) pose. Recent works try to integrate differentiable RANSAC algorithms to achieve an end-to-end 6D pose estimation. However, most of them hardly consider the geometric features in 3D space, and ignore the topology cues when performing differentiable RANSAC algorithms. To this end, we proposed a Depth-Guided Edge Convolutional Network (DGECN) for 6D pose estimation task. We have made efforts from the following three aspects: 1) We take advantages ofestimated depth information to guide both the correspondences-extraction process and the cascaded differentiable RANSAC algorithm with geometric information. 2)We leverage the uncertainty ofthe estimated depth map to improve accuracy and robustness ofthe output 6D pose. 3) We propose a differentiable Perspective-n-Point(PnP) algorithm via edge convolution to explore the topology relations between 2D-3D correspondences. Experiments demonstrate that our proposed network outperforms current works on both effectiveness and efficiency.