 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Tiny-Mamba Transformer for Reliability-Aware Early Fault Warning
Jan 29, 2026Reliability-centered prognostics for rotating machinery requires early warning signals that remain accurate under nonstationary operating conditions, domain shifts across speed/load/sensors, and severe class imbalance, while keeping the false-alarm rate small and predictable. We propose the Physics-Guided Tiny-Mamba Transformer (PG-TMT), a compact tri-branch encoder tailored for online condition monitoring. A depthwise-separable convolutional stem captures micro-transients, a Tiny-Mamba state-space branch models near-linear long-range dynamics, and a lightweight local Transformer encodes cross-channel resonances. We derive an analytic temporal-to-spectral mapping that ties the model's attention spectrum to classical bearing fault-order bands, yielding a band-alignment score that quantifies physical plausibility and provides physics-grounded explanations. To ensure decision reliability, healthy-score exceedances are modeled with extreme-value theory (EVT), which yields an on-threshold achieving a target false-alarm intensity (events/hour); a dual-threshold hysteresis with a minimum hold time further suppresses chatter. Under a leakage-free streaming protocol with right-censoring of missed detections on CWRU, Paderborn, XJTU-SY, and an industrial pilot, PG-TMT attains higher precision-recall AUC (primary under imbalance), competitive or better ROC AUC, and shorter mean time-to-detect at matched false-alarm intensity, together with strong cross-domain transfer. By coupling physics-aligned representations with EVT-calibrated decision rules, PG-TMT delivers calibrated, interpretable, and deployment-ready early warnings for reliability-centric prognostics and health management.
Geometric Prior-Guided Federated Prompt Calibration
Dec 08, 2025Federated Prompt Learning (FPL) offers a parameter-efficient solution for collaboratively training large models, but its performance is severely hindered by data heterogeneity, which causes locally trained prompts to become biased. Existing methods, focusing on aggregation or regularization, fail to address this root cause of local training bias. To this end, we propose Geometry-Guided Text Prompt Calibration (GGTPC), a novel framework that directly corrects this bias by providing clients with a global geometric prior. This prior, representing the shape of the global data distribution derived from the covariance matrix, is reconstructed on the server in a privacy-preserving manner. Clients then use a novel Geometry-Prior Calibration Layer (GPCL) to align their local feature distributions with this global prior during training. Extensive experiments show GGTPC's effectiveness. On the label-skewed CIFAR-100 dataset ($β$=0.1), it outperforms the state-of-the-art by 2.15\%. Under extreme skew ($β$=0.01), it improves upon the baseline by 9.17\%. Furthermore, as a plug-and-play module on the domain-skewed Office-Home dataset, it boosts FedAvg's performance by 4.60\%. These results demonstrate that GGTPC effectively mitigates data heterogeneity by correcting the fundamental local training bias, serving as a versatile module to enhance various FL algorithms.
CardiacMamba: A Multimodal RGB-RF Fusion Framework with State Space Models for Remote Physiological Measurement
Feb 19, 2025



Heart rate (HR) estimation via remote photoplethysmography (rPPG) offers a non-invasive solution for health monitoring. However, traditional single-modality approaches (RGB or Radio Frequency (RF)) face challenges in balancing robustness and accuracy due to lighting variations, motion artifacts, and skin tone bias. In this paper, we propose CardiacMamba, a multimodal RGB-RF fusion framework that leverages the complementary strengths of both modalities. It introduces the Temporal Difference Mamba Module (TDMM) to capture dynamic changes in RF signals using timing differences between frames, enhancing the extraction of local and global features. Additionally, CardiacMamba employs a Bidirectional SSM for cross-modal alignment and a Channel-wise Fast Fourier Transform (CFFT) to effectively capture and refine the frequency domain characteristics of RGB and RF signals, ultimately improving heart rate estimation accuracy and periodicity detection. Extensive experiments on the EquiPleth dataset demonstrate state-of-the-art performance, achieving marked improvements in accuracy and robustness. CardiacMamba significantly mitigates skin tone bias, reducing performance disparities across demographic groups, and maintains resilience under missing-modality scenarios. By addressing critical challenges in fairness, adaptability, and precision, the framework advances rPPG technology toward reliable real-world deployment in healthcare. The codes are available at: https://github.com/WuZheng42/CardiacMamba.
DLCA-Recon: Dynamic Loose Clothing Avatar Reconstruction from Monocular Videos
Dec 20, 2023



Reconstructing a dynamic human with loose clothing is an important but difficult task. To address this challenge, we propose a method named DLCA-Recon to create human avatars from monocular videos. The distance from loose clothing to the underlying body rapidly changes in every frame when the human freely moves and acts. Previous methods lack effective geometric initialization and constraints for guiding the optimization of deformation to explain this dramatic change, resulting in the discontinuous and incomplete reconstruction surface. To model the deformation more accurately, we propose to initialize an estimated 3D clothed human in the canonical space, as it is easier for deformation fields to learn from the clothed human than from SMPL. With both representations of explicit mesh and implicit SDF, we utilize the physical connection information between consecutive frames and propose a dynamic deformation field (DDF) to optimize deformation fields. DDF accounts for contributive forces on loose clothing to enhance the interpretability of deformations and effectively capture the free movement of loose clothing. Moreover, we propagate SMPL skinning weights to each individual and refine pose and skinning weights during the optimization to improve skinning transformation. Based on more reasonable initialization and DDF, we can simulate real-world physics more accurately. Extensive experiments on public and our own datasets validate that our method can produce superior results for humans with loose clothing compared to the SOTA methods.
NeTO:Neural Reconstruction of Transparent Objects with Self-Occlusion Aware Refraction-Tracing
Mar 20, 2023
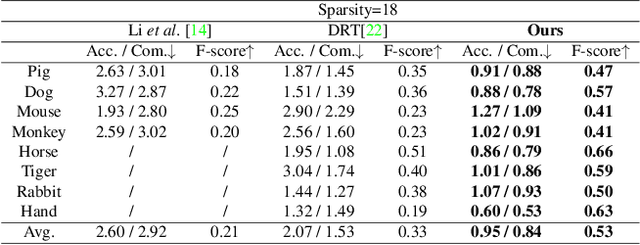
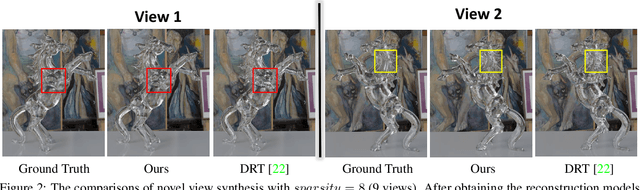
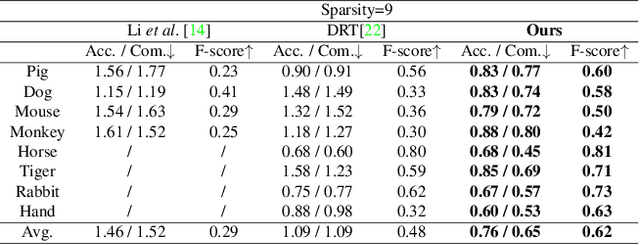
We present a novel method, called NeTO, for capturing 3D geometry of solid transparent objects from 2D images via volume rendering. Reconstructing transparent objects is a very challenging task, which is ill-suited for general-purpose reconstruction techniques due to the specular light transport phenomena. Although existing refraction-tracing based methods, designed specially for this task, achieve impressive results, they still suffer from unstable optimization and loss of fine details, since the explicit surface representation they adopted is difficult to be optimized, and the self-occlusion problem is ignored for refraction-tracing. In this paper, we propose to leverage implicit Signed Distance Function (SDF) as surface representation, and optimize the SDF field via volume rendering with a self-occlusion aware refractive ray tracing. The implicit representation enables our method to be capable of reconstructing high-quality reconstruction even with a limited set of images, and the self-occlusion aware strategy makes it possible for our method to accurately reconstruct the self-occluded regions. Experiments show that our method achieves faithful reconstruction results and outperforms prior works by a large margin. Visit our project page at \url{https://www.xxlong.site/NeTO/}
DGECN: A Depth-Guided Edge Convolutional Network for End-to-End 6D Pose Estimation
Apr 21, 2022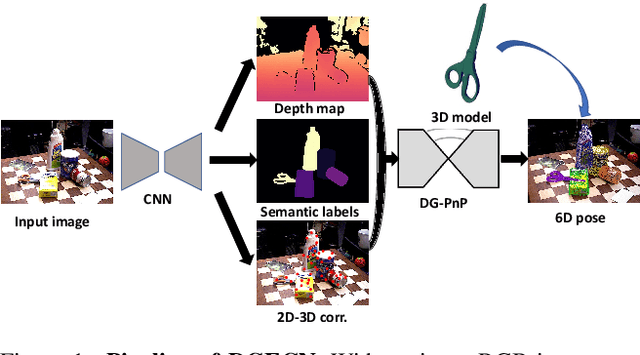
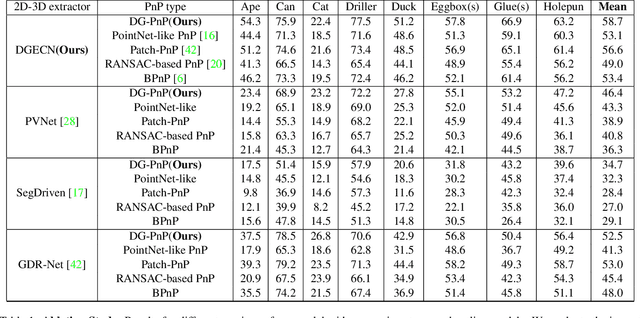
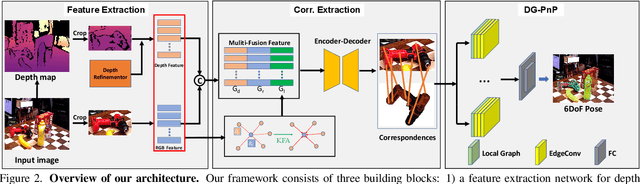
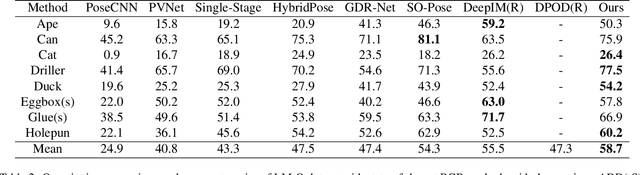
Monocular 6D pose estimation is a fundamental task in computer vision. Existing works often adopt a two-stage pipeline by establishing correspondences and utilizing a RANSAC algorithm to calculate 6 degrees-of-freedom (6DoF) pose. Recent works try to integrate differentiable RANSAC algorithms to achieve an end-to-end 6D pose estimation. However, most of them hardly consider the geometric features in 3D space, and ignore the topology cues when performing differentiable RANSAC algorithms. To this end, we proposed a Depth-Guided Edge Convolutional Network (DGECN) for 6D pose estimation task. We have made efforts from the following three aspects: 1) We take advantages ofestimated depth information to guide both the correspondences-extraction process and the cascaded differentiable RANSAC algorithm with geometric information. 2)We leverage the uncertainty ofthe estimated depth map to improve accuracy and robustness ofthe output 6D pose. 3) We propose a differentiable Perspective-n-Point(PnP) algorithm via edge convolution to explore the topology relations between 2D-3D correspondences. Experiments demonstrate that our proposed network outperforms current works on both effectiveness and efficiency.
RedNet: Residual Encoder-Decoder Network for indoor RGB-D Semantic Segmentation
Aug 06, 2018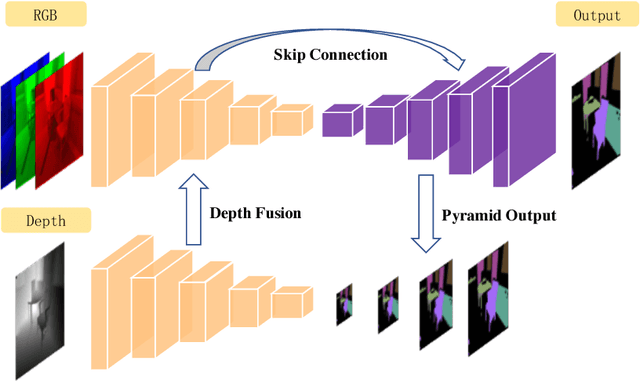
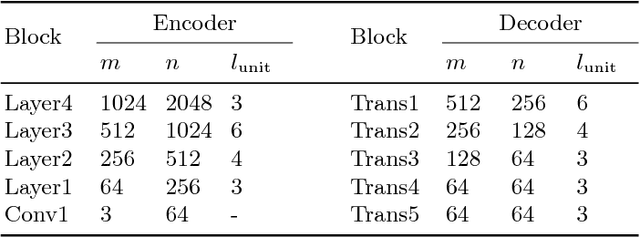
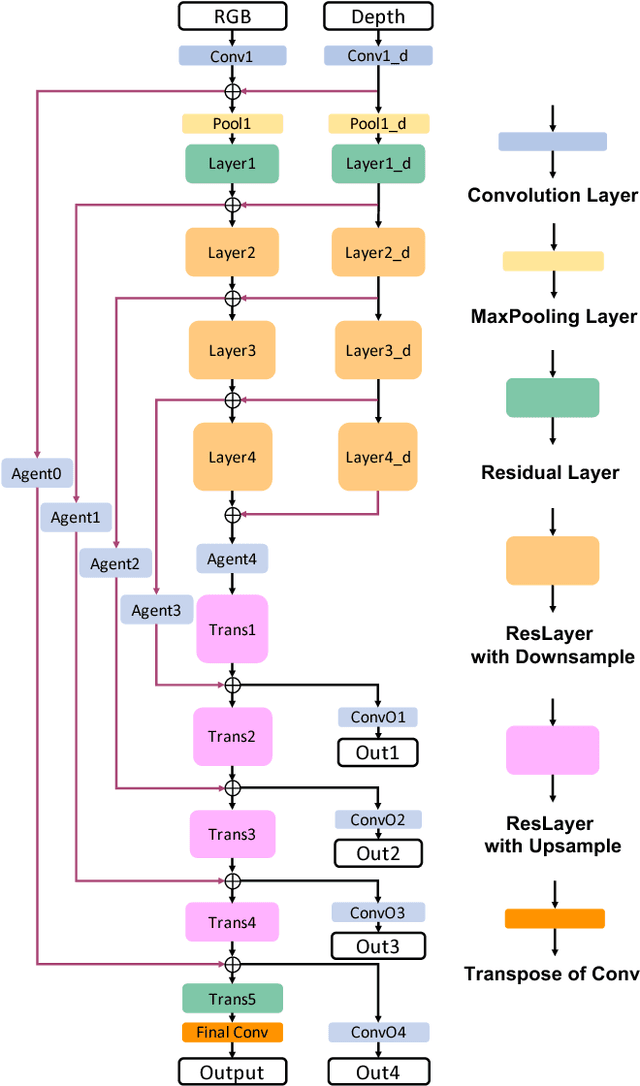
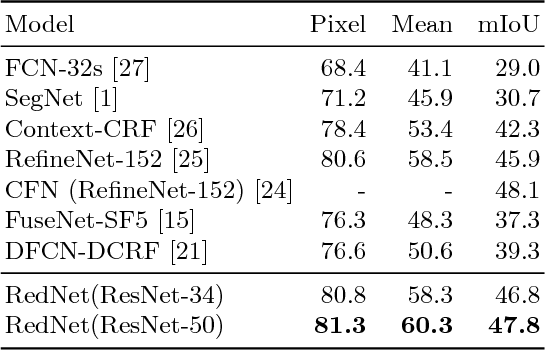
Indoor semantic segmentation has always been a difficult task in computer vision. In this paper, we propose an RGB-D residual encoder-decoder architecture, named RedNet, for indoor RGB-D semantic segmentation. In RedNet, the residual module is applied to both the encoder and decoder as the basic building block, and the skip-connection is used to bypass the spatial feature between the encoder and decoder. In order to incorporate the depth information of the scene, a fusion structure is constructed, which makes inference on RGB image and depth image separately, and fuses their features over several layers. In order to efficiently optimize the network's parameters, we propose a `pyramid supervision' training scheme, which applies supervised learning over different layers in the decoder, to cope with the problem of gradients vanishing. Experiment results show that the proposed RedNet(ResNet-50) achieves a state-of-the-art mIoU accuracy of 47.8% on the SUN RGB-D benchmark dataset.