 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoReAct: Egocentric Video-Driven 3D Human Reaction Generation
Dec 28, 2025Humans exhibit adaptive, context-sensitive responses to egocentric visual input. However, faithfully modeling such reactions from egocentric video remains challenging due to the dual requirements of strictly causal generation and precise 3D spatial alignment. To tackle this problem, we first construct the Human Reaction Dataset (HRD) to address data scarcity and misalignment by building a spatially aligned egocentric video-reaction dataset, as existing datasets (e.g., ViMo) suffer from significant spatial inconsistency between the egocentric video and reaction motion, e.g., dynamically moving motions are always paired with fixed-camera videos. Leveraging HRD, we present EgoReAct, the first autoregressive framework that generates 3D-aligned human reaction motions from egocentric video streams in real-time. We first compress the reaction motion into a compact yet expressive latent space via a Vector Quantised-Variational AutoEncoder and then train a Generative Pre-trained Transformer for reaction generation from the visual input. EgoReAct incorporates 3D dynamic features, i.e., metric depth, and head dynamics during the generation, which effectively enhance spatial grounding. Extensive experiments demonstrate that EgoReAct achieves remarkably higher realism, spatial consistency, and generation efficiency compared with prior methods, while maintaining strict causality during generation. We will release code, models, and data upon acceptance.
Pressure2Motion: Hierarchical Motion Synthesis from Ground Pressure with Text Guidance
Nov 07, 2025We present Pressure2Motion, a novel motion capture algorithm that synthesizes human motion from a ground pressure sequence and text prompt. It eliminates the need for specialized lighting setups, cameras, or wearable devices, making it suitable for privacy-preserving, low-light, and low-cost motion capture scenarios. Such a task is severely ill-posed due to the indeterminate nature of the pressure signals to full-body motion. To address this issue, we introduce Pressure2Motion, a generative model that leverages pressure features as input and utilizes a text prompt as a high-level guiding constraint. Specifically, our model utilizes a dual-level feature extractor that accurately interprets pressure data, followed by a hierarchical diffusion model that discerns broad-scale movement trajectories and subtle posture adjustments. Both the physical cues gained from the pressure sequence and the semantic guidance derived from descriptive texts are leveraged to guide the motion generation with precision. To the best of our knowledge, Pressure2Motion is a pioneering work in leveraging both pressure data and linguistic priors for motion generation, and the established MPL benchmark is the first benchmark for this task. Experiments show our method generates high-fidelity, physically plausible motions, establishing a new state-of-the-art for this task. The codes and benchmarks will be publicly released upon publication.
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.
OccTENS: 3D Occupancy World Model via Temporal Next-Scale Prediction
Sep 04, 2025In this paper, we propose OccTENS, a generative occupancy world model that enables controllable, high-fidelity long-term occupancy generation while maintaining computational efficiency. Different from visual generation, the occupancy world model must capture the fine-grained 3D geometry and dynamic evolution of the 3D scenes, posing great challenges for the generative models. Recent approaches based on autoregression (AR) have demonstrated the potential to predict vehicle movement and future occupancy scenes simultaneously from historical observations, but they typically suffer from \textbf{inefficiency}, \textbf{temporal degradation} in long-term generation and \textbf{lack of controllability}. To holistically address these issues, we reformulate the occupancy world model as a temporal next-scale prediction (TENS) task, which decomposes the temporal sequence modeling problem into the modeling of spatial scale-by-scale generation and temporal scene-by-scene prediction. With a \textbf{TensFormer}, OccTENS can effectively manage the temporal causality and spatial relationships of occupancy sequences in a flexible and scalable way. To enhance the pose controllability, we further propose a holistic pose aggregation strategy, which features a unified sequence modeling for occupancy and ego-motion. Experiments show that OccTENS outperforms the state-of-the-art method with both higher occupancy quality and faster inference time.
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025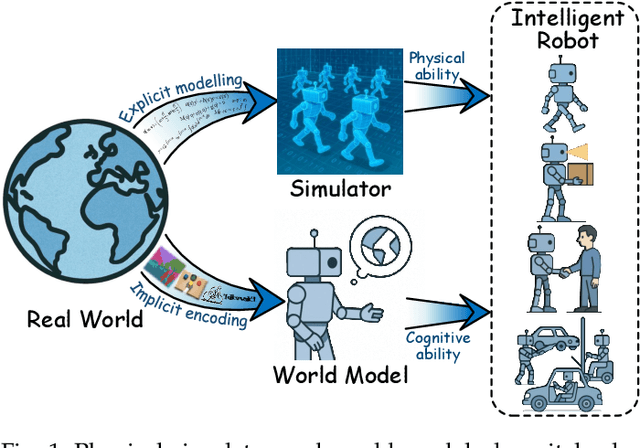
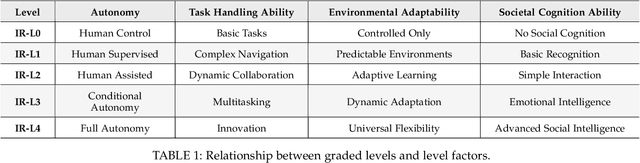
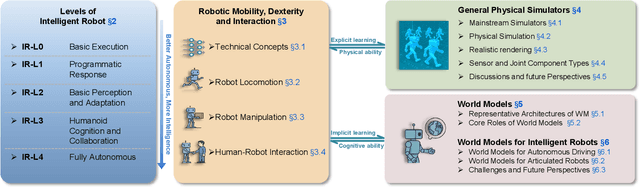

The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.
Multimodal LLMs for Visualization Reconstruction and Understanding
Jun 26, 2025Visualizations are crucial for data communication, yet understanding them requires comprehension of both visual elements and their underlying data relationships. Current multimodal large models, while effective in natural image understanding, struggle with visualization due to their inability to decode the data-to-visual mapping rules and extract structured information. To address these challenges, we present a novel dataset and train multimodal visualization LLMs specifically designed for understanding. Our approach combines chart images with their corresponding vectorized representations, encoding schemes, and data features. The proposed vector format enables compact and accurate reconstruction of visualization content. Experimental results demonstrate significant improvements in both data extraction accuracy and chart reconstruction quality.
DanceTogether! Identity-Preserving Multi-Person Interactive Video Generation
May 23, 2025Controllable video generation (CVG) has advanced rapidly, yet current systems falter when more than one actor must move, interact, and exchange positions under noisy control signals. We address this gap with DanceTogether, the first end-to-end diffusion framework that turns a single reference image plus independent pose-mask streams into long, photorealistic videos while strictly preserving every identity. A novel MaskPoseAdapter binds "who" and "how" at every denoising step by fusing robust tracking masks with semantically rich-but noisy-pose heat-maps, eliminating the identity drift and appearance bleeding that plague frame-wise pipelines. To train and evaluate at scale, we introduce (i) PairFS-4K, 26 hours of dual-skater footage with 7,000+ distinct IDs, (ii) HumanRob-300, a one-hour humanoid-robot interaction set for rapid cross-domain transfer, and (iii) TogetherVideoBench, a three-track benchmark centered on the DanceTogEval-100 test suite covering dance, boxing, wrestling, yoga, and figure skating. On TogetherVideoBench, DanceTogether outperforms the prior arts by a significant margin. Moreover, we show that a one-hour fine-tune yields convincing human-robot videos, underscoring broad generalization to embodied-AI and HRI tasks. Extensive ablations confirm that persistent identity-action binding is critical to these gains. Together, our model, datasets, and benchmark lift CVG from single-subject choreography to compositionally controllable, multi-actor interaction, opening new avenues for digital production, simulation, and embodied intelligence. Our video demos and code are available at https://DanceTog.github.io/.
NeuralGS: Bridging Neural Fields and 3D Gaussian Splatting for Compact 3D Representations
Mar 29, 2025



3D Gaussian Splatting (3DGS) demonstrates superior quality and rendering speed, but with millions of 3D Gaussians and significant storage and transmission costs. Recent 3DGS compression methods mainly concentrate on compressing Scaffold-GS, achieving impressive performance but with an additional voxel structure and a complex encoding and quantization strategy. In this paper, we aim to develop a simple yet effective method called NeuralGS that explores in another way to compress the original 3DGS into a compact representation without the voxel structure and complex quantization strategies. Our observation is that neural fields like NeRF can represent complex 3D scenes with Multi-Layer Perceptron (MLP) neural networks using only a few megabytes. Thus, NeuralGS effectively adopts the neural field representation to encode the attributes of 3D Gaussians with MLPs, only requiring a small storage size even for a large-scale scene. To achieve this, we adopt a clustering strategy and fit the Gaussians with different tiny MLPs for each cluster, based on importance scores of Gaussians as fitting weights. We experiment on multiple datasets, achieving a 45-times average model size reduction without harming the visual quality. The compression performance of our method on original 3DGS is comparable to the dedicated Scaffold-GS-based compression methods, which demonstrate the huge potential of directly compressing original 3DGS with neural fields.
GoalFlow: Goal-Driven Flow Matching for Multimodal Trajectories Generation in End-to-End Autonomous Driving
Mar 07, 2025We propose GoalFlow, an end-to-end autonomous driving method for generating high-quality multimodal trajectories. In autonomous driving scenarios, there is rarely a single suitable trajectory. Recent methods have increasingly focused on modeling multimodal trajectory distributions. However, they suffer from trajectory selection complexity and reduced trajectory quality due to high trajectory divergence and inconsistencies between guidance and scene information. To address these issues, we introduce GoalFlow, a novel method that effectively constrains the generative process to produce high-quality, multimodal trajectories. To resolve the trajectory divergence problem inherent in diffusion-based methods, GoalFlow constrains the generated trajectories by introducing a goal point. GoalFlow establishes a novel scoring mechanism that selects the most appropriate goal point from the candidate points based on scene information. Furthermore, GoalFlow employs an efficient generative method, Flow Matching, to generate multimodal trajectories, and incorporates a refined scoring mechanism to select the optimal trajectory from the candidates. Our experimental results, validated on the Navsim\cite{Dauner2024_navsim}, demonstrate that GoalFlow achieves state-of-the-art performance, delivering robust multimodal trajectories for autonomous driving. GoalFlow achieved PDMS of 90.3, significantly surpassing other methods. Compared with other diffusion-policy-based methods, our approach requires only a single denoising step to obtain excellent performance. The code is available at https://github.com/YvanYin/GoalFlow.
CADDreamer: CAD object Generation from Single-view Images
Feb 28, 2025



Diffusion-based 3D generation has made remarkable progress in recent years. However, existing 3D generative models often produce overly dense and unstructured meshes, which stand in stark contrast to the compact, structured, and sharply-edged Computer-Aided Design (CAD) models crafted by human designers. To address this gap, we introduce CADDreamer, a novel approach for generating boundary representations (B-rep) of CAD objects from a single image. CADDreamer employs a primitive-aware multi-view diffusion model that captures both local geometric details and high-level structural semantics during the generation process. By encoding primitive semantics into the color domain, the method leverages the strong priors of pre-trained diffusion models to align with well-defined primitives. This enables the inference of multi-view normal maps and semantic maps from a single image, facilitating the reconstruction of a mesh with primitive labels. Furthermore, we introduce geometric optimization techniques and topology-preserving extraction methods to mitigate noise and distortion in the generated primitives. These enhancements result in a complete and seamless B-rep of the CAD model. Experimental results demonstrate that our method effectively recovers high-quality CAD objects from single-view images. Compared to existing 3D generation techniques, the B-rep models produced by CADDreamer are compact in representation, clear in structure, sharp in edges, and watertight in topology.