 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Fusion of Large Atomic and Language Models to Accelerate Materials Discovery
Apr 26, 2026The discovery of novel materials is critical for global energy and quantum technology transitions. While deep learning has fundamentally reshaped this landscape, existing predictive or generative models typically operate in isolation, lacking the autonomous orchestration required to execute the full discovery process. Here we present ElementsClaw, an agentic framework for materials discovery that synergizes Large Atomic Models (LAMs) with Large Language Models (LLMs). In response to varied human requirements, ElementsClaw dynamically orchestrates a suite of LAM tools finetuned from our proposed model Elements for atomic-scale numerical computation, while leveraging LLMs for high-level semantic reasoning. This shift moves AI-driven materials science from isolated processes toward integrated and human interactive discovery. In the demanding domain of superconductors, our agentic system guides the experimental synthesis of four new superconductors, including Zr3ScRe8 with a transition temperature of 6.8 K and HfZrRe4 at 6.7 K. At scale, ElementsClaw screens more than 2.4 million stable crystals within only 28 GPU hours, identifying 68,000 high-confidence superconducting candidates and vastly expanding the known superconducting space. These results demonstrate how our agent accelerates materials discovery with high physical fidelity.
TopoMesh: High-Fidelity Mesh Autoencoding via Topological Unification
Mar 25, 2026The dominant paradigm for high-fidelity 3D generation relies on a VAE-Diffusion pipeline, where the VAE's reconstruction capability sets a firm upper bound on generation quality. A fundamental challenge limiting existing VAEs is the representation mismatch between ground-truth meshes and network predictions: GT meshes have arbitrary, variable topology, while VAEs typically predict fixed-structure implicit fields (\eg, SDF on regular grids). This inherent misalignment prevents establishing explicit mesh-level correspondences, forcing prior work to rely on indirect supervision signals such as SDF or rendering losses. Consequently, fine geometric details, particularly sharp features, are poorly preserved during reconstruction. To address this, we introduce TopoMesh, a sparse voxel-based VAE that unifies both GT and predicted meshes under a shared Dual Marching Cubes (DMC) topological framework. Specifically, we convert arbitrary input meshes into DMC-compliant representations via a remeshing algorithm that preserves sharp edges using an L$\infty$ distance metric. Our decoder outputs meshes in the same DMC format, ensuring that both predicted and target meshes share identical topological structures. This establishes explicit correspondences at the vertex and face level, allowing us to derive explicit mesh-level supervision signals for topology, vertex positions, and face orientations with clear gradients. Our sparse VAE architecture employs this unified framework and is trained with Teacher Forcing and progressive resolution training for stable and efficient convergence. Extensive experiments demonstrate that TopoMesh significantly outperforms existing VAEs in reconstruction fidelity, achieving superior preservation of sharp features and geometric details.
Cognitive Chunking for Soft Prompts: Accelerating Compressor Learning via Block-wise Causal Masking
Feb 15, 2026Providing extensive context via prompting is vital for leveraging the capabilities of Large Language Models (LLMs). However, lengthy contexts significantly increase inference latency, as the computational cost of self-attention grows quadratically with sequence length. To mitigate this issue, context compression-particularly soft prompt compressio-has emerged as a widely studied solution, which converts long contexts into shorter memory embeddings via a trained compressor. Existing methods typically compress the entire context indiscriminately into a set of memory tokens, requiring the compressor to capture global dependencies and necessitating extensive pre-training data to learn effective patterns. Inspired by the chunking mechanism in human working memory and empirical observations of the spatial specialization of memory embeddings relative to original tokens, we propose Parallelized Iterative Compression (PIC). By simply modifying the Transformer's attention mask, PIC explicitly restricts the receptive field of memory tokens to sequential local chunks, thereby lowering the difficulty of compressor training. Experiments across multiple downstream tasks demonstrate that PIC consistently outperforms competitive baselines, with superiority being particularly pronounced in high compression scenarios (e.g., achieving relative improvements of 29.8\% in F1 score and 40.7\% in EM score on QA tasks at the $64\times$ compression ratio). Furthermore, PIC significantly expedites the training process. Specifically, when training the 16$\times$ compressor, it surpasses the peak performance of the competitive baseline while effectively reducing the training time by approximately 40\%.
Puppeteer: Rig and Animate Your 3D Models
Aug 14, 2025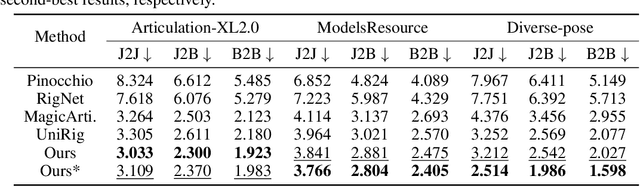

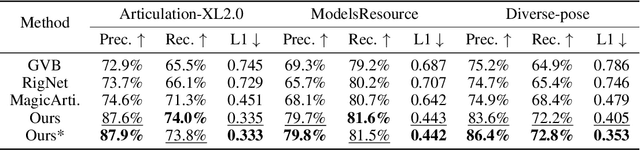

Modern interactive applications increasingly demand dynamic 3D content, yet the transformation of static 3D models into animated assets constitutes a significant bottleneck in content creation pipelines. While recent advances in generative AI have revolutionized static 3D model creation, rigging and animation continue to depend heavily on expert intervention. We present Puppeteer, a comprehensive framework that addresses both automatic rigging and animation for diverse 3D objects. Our system first predicts plausible skeletal structures via an auto-regressive transformer that introduces a joint-based tokenization strategy for compact representation and a hierarchical ordering methodology with stochastic perturbation that enhances bidirectional learning capabilities. It then infers skinning weights via an attention-based architecture incorporating topology-aware joint attention that explicitly encodes inter-joint relationships based on skeletal graph distances. Finally, we complement these rigging advances with a differentiable optimization-based animation pipeline that generates stable, high-fidelity animations while being computationally more efficient than existing approaches. Extensive evaluations across multiple benchmarks demonstrate that our method significantly outperforms state-of-the-art techniques in both skeletal prediction accuracy and skinning quality. The system robustly processes diverse 3D content, ranging from professionally designed game assets to AI-generated shapes, producing temporally coherent animations that eliminate the jittering issues common in existing methods.
SMPL Normal Map Is All You Need for Single-view Textured Human Reconstruction
Jun 15, 2025Single-view textured human reconstruction aims to reconstruct a clothed 3D digital human by inputting a monocular 2D image. Existing approaches include feed-forward methods, limited by scarce 3D human data, and diffusion-based methods, prone to erroneous 2D hallucinations. To address these issues, we propose a novel SMPL normal map Equipped 3D Human Reconstruction (SEHR) framework, integrating a pretrained large 3D reconstruction model with human geometry prior. SEHR performs single-view human reconstruction without using a preset diffusion model in one forward propagation. Concretely, SEHR consists of two key components: SMPL Normal Map Guidance (SNMG) and SMPL Normal Map Constraint (SNMC). SNMG incorporates SMPL normal maps into an auxiliary network to provide improved body shape guidance. SNMC enhances invisible body parts by constraining the model to predict an extra SMPL normal Gaussians. Extensive experiments on two benchmark datasets demonstrate that SEHR outperforms existing state-of-the-art methods.
Active Contour Models Driven by Hyperbolic Mean Curvature Flow for Image Segmentation
Jun 07, 2025Parabolic mean curvature flow-driven active contour models (PMCF-ACMs) are widely used in image segmentation, which however depend heavily on the selection of initial curve configurations. In this paper, we firstly propose several hyperbolic mean curvature flow-driven ACMs (HMCF-ACMs), which introduce tunable initial velocity fields, enabling adaptive optimization for diverse segmentation scenarios. We shall prove that HMCF-ACMs are indeed normal flows and establish the numerical equivalence between dissipative HMCF formulations and certain wave equations using the level set method with signed distance function. Building on this framework, we furthermore develop hyperbolic dual-mode regularized flow-driven ACMs (HDRF-ACMs), which utilize smooth Heaviside functions for edge-aware force modulation to suppress over-diffusion near weak boundaries. Then, we optimize a weighted fourth-order Runge-Kutta algorithm with nine-point stencil spatial discretization when solving the above-mentioned wave equations. Experiments show that both HMCF-ACMs and HDRF-ACMs could achieve more precise segmentations with superior noise resistance and numerical stability due to task-adaptive configurations of initial velocities and initial contours.
A Continual Learning-driven Model for Accurate and Generalizable Segmentation of Clinically Comprehensive and Fine-grained Whole-body Anatomies in CT
Mar 16, 2025Precision medicine in the quantitative management of chronic diseases and oncology would be greatly improved if the Computed Tomography (CT) scan of any patient could be segmented, parsed and analyzed in a precise and detailed way. However, there is no such fully annotated CT dataset with all anatomies delineated for training because of the exceptionally high manual cost, the need for specialized clinical expertise, and the time required to finish the task. To this end, we proposed a novel continual learning-driven CT model that can segment complete anatomies presented using dozens of previously partially labeled datasets, dynamically expanding its capacity to segment new ones without compromising previously learned organ knowledge. Existing multi-dataset approaches are not able to dynamically segment new anatomies without catastrophic forgetting and would encounter optimization difficulty or infeasibility when segmenting hundreds of anatomies across the whole range of body regions. Our single unified CT segmentation model, CL-Net, can highly accurately segment a clinically comprehensive set of 235 fine-grained whole-body anatomies. Composed of a universal encoder, multiple optimized and pruned decoders, CL-Net is developed using 13,952 CT scans from 20 public and 16 private high-quality partially labeled CT datasets of various vendors, different contrast phases, and pathologies. Extensive evaluation demonstrates that CL-Net consistently outperforms the upper limit of an ensemble of 36 specialist nnUNets trained per dataset with the complexity of 5% model size and significantly surpasses the segmentation accuracy of recent leading Segment Anything-style medical image foundation models by large margins. Our continual learning-driven CL-Net model would lay a solid foundation to facilitate many downstream tasks of oncology and chronic diseases using the most widely adopted CT imaging.
KiteRunner: Language-Driven Cooperative Local-Global Navigation Policy with UAV Mapping in Outdoor Environments
Mar 11, 2025
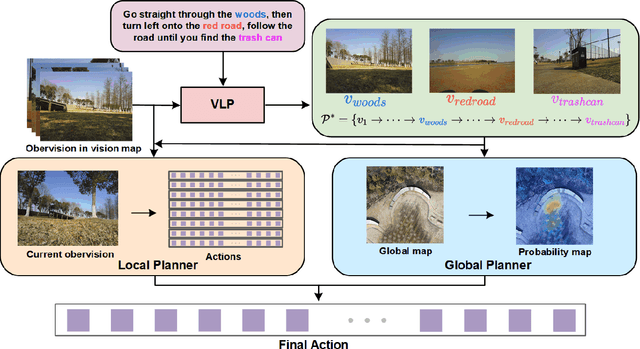
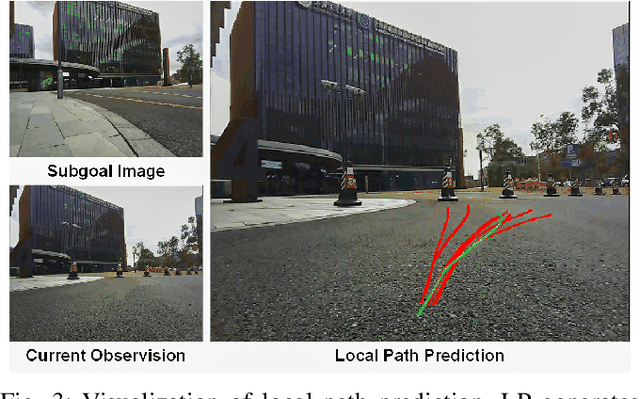

Autonomous navigation in open-world outdoor environments faces challenges in integrating dynamic conditions, long-distance spatial reasoning, and semantic understanding. Traditional methods struggle to balance local planning, global planning, and semantic task execution, while existing large language models (LLMs) enhance semantic comprehension but lack spatial reasoning capabilities. Although diffusion models excel in local optimization, they fall short in large-scale long-distance navigation. To address these gaps, this paper proposes KiteRunner, a language-driven cooperative local-global navigation strategy that combines UAV orthophoto-based global planning with diffusion model-driven local path generation for long-distance navigation in open-world scenarios. Our method innovatively leverages real-time UAV orthophotography to construct a global probability map, providing traversability guidance for the local planner, while integrating large models like CLIP and GPT to interpret natural language instructions. Experiments demonstrate that KiteRunner achieves 5.6% and 12.8% improvements in path efficiency over state-of-the-art methods in structured and unstructured environments, respectively, with significant reductions in human interventions and execution time.
Mantis: Lightweight Calibrated Foundation Model for User-Friendly Time Series Classification
Feb 21, 2025In recent years, there has been increasing interest in developing foundation models for time series data that can generalize across diverse downstream tasks. While numerous forecasting-oriented foundation models have been introduced, there is a notable scarcity of models tailored for time series classification. To address this gap, we present Mantis, a new open-source foundation model for time series classification based on the Vision Transformer (ViT) architecture that has been pre-trained using a contrastive learning approach. Our experimental results show that Mantis outperforms existing foundation models both when the backbone is frozen and when fine-tuned, while achieving the lowest calibration error. In addition, we propose several adapters to handle the multivariate setting, reducing memory requirements and modeling channel interdependence.
MagicArticulate: Make Your 3D Models Articulation-Ready
Feb 18, 2025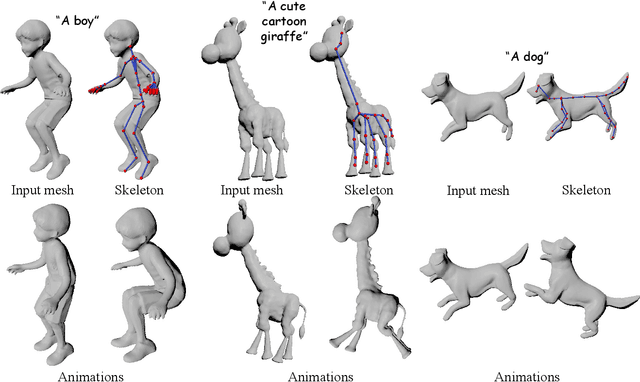
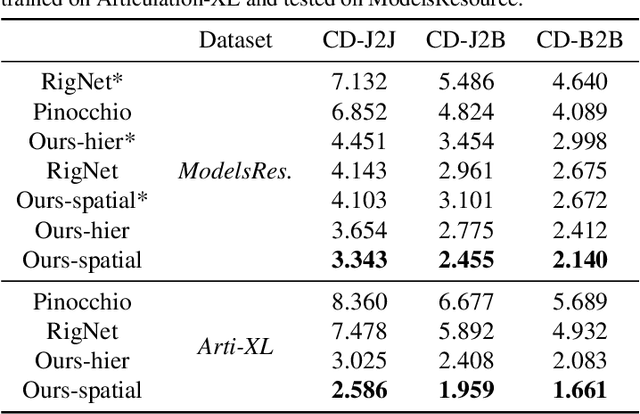
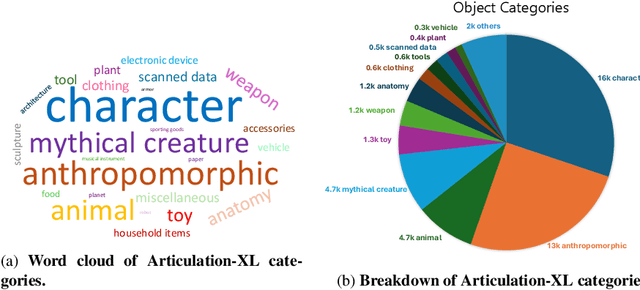
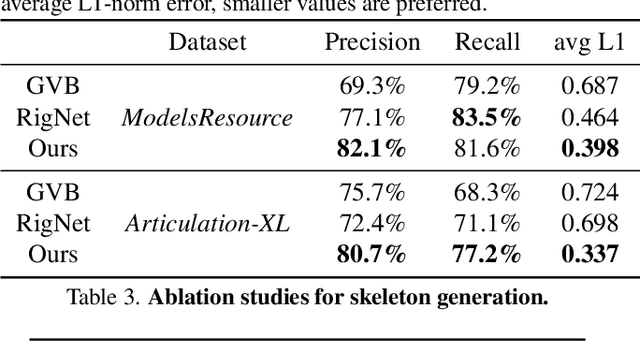
With the explosive growth of 3D content creation, there is an increasing demand for automatically converting static 3D models into articulation-ready versions that support realistic animation. Traditional approaches rely heavily on manual annotation, which is both time-consuming and labor-intensive. Moreover, the lack of large-scale benchmarks has hindered the development of learning-based solutions. In this work, we present MagicArticulate, an effective framework that automatically transforms static 3D models into articulation-ready assets. Our key contributions are threefold. First, we introduce Articulation-XL, a large-scale benchmark containing over 33k 3D models with high-quality articulation annotations, carefully curated from Objaverse-XL. Second, we propose a novel skeleton generation method that formulates the task as a sequence modeling problem, leveraging an auto-regressive transformer to naturally handle varying numbers of bones or joints within skeletons and their inherent dependencies across different 3D models. Third, we predict skinning weights using a functional diffusion process that incorporates volumetric geodesic distance priors between vertices and joints. Extensive experiments demonstrate that MagicArticulate significantly outperforms existing methods across diverse object categories, achieving high-quality articulation that enables realistic animation. Project page: https://chaoyuesong.github.io/MagicArticulate.