 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Zero-Shot Time Series Classification: From Task-specific Classifiers to In-Context Inference
Jan 31, 2026The zero-shot evaluation of time series foundation models (TSFMs) for classification typically uses a frozen encoder followed by a task-specific classifier. However, this practice violates the training-free premise of zero-shot deployment and introduces evaluation bias due to classifier-dependent training choices. To address this issue, we propose TIC-FM, an in-context learning framework that treats the labeled training set as context and predicts labels for all test instances in a single forward pass, without parameter updates. TIC-FM pairs a time series encoder and a lightweight projection adapter with a split-masked latent memory Transformer. We further provide theoretical justification that in-context inference can subsume trained classifiers and can emulate gradient-based classifier training within a single forward pass. Experiments on 128 UCR datasets show strong accuracy, with consistent gains in the extreme low-label situation, highlighting training-free transfer
CC-Time: Cross-Model and Cross-Modality Time Series Forecasting
Aug 17, 2025
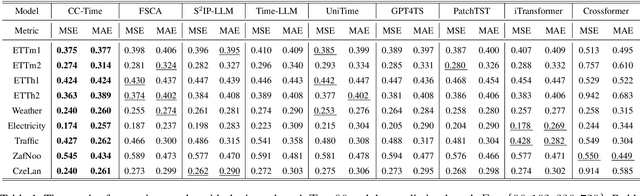

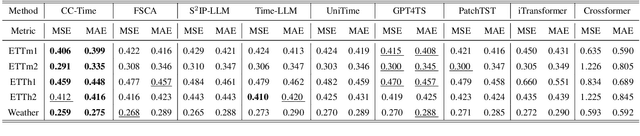
With the success of pre-trained language models (PLMs) in various application fields beyond natural language processing, language models have raised emerging attention in the field of time series forecasting (TSF) and have shown great prospects. However, current PLM-based TSF methods still fail to achieve satisfactory prediction accuracy matching the strong sequential modeling power of language models. To address this issue, we propose Cross-Model and Cross-Modality Learning with PLMs for time series forecasting (CC-Time). We explore the potential of PLMs for time series forecasting from two aspects: 1) what time series features could be modeled by PLMs, and 2) whether relying solely on PLMs is sufficient for building time series models. In the first aspect, CC-Time incorporates cross-modality learning to model temporal dependency and channel correlations in the language model from both time series sequences and their corresponding text descriptions. In the second aspect, CC-Time further proposes the cross-model fusion block to adaptively integrate knowledge from the PLMs and time series model to form a more comprehensive modeling of time series patterns. Extensive experiments on nine real-world datasets demonstrate that CC-Time achieves state-of-the-art prediction accuracy in both full-data training and few-shot learning situations.
LightGTS: A Lightweight General Time Series Forecasting Model
Jun 06, 2025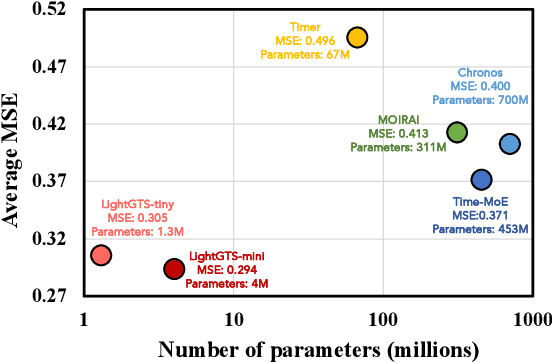
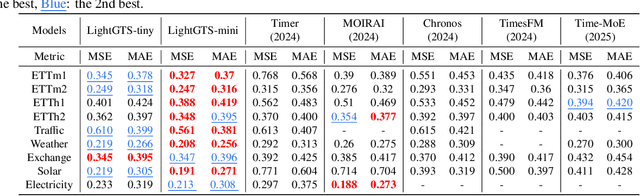
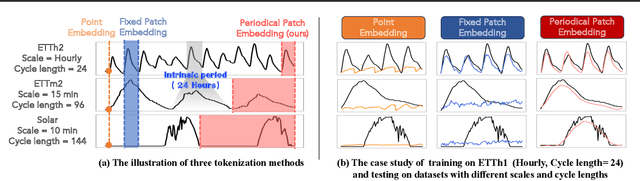
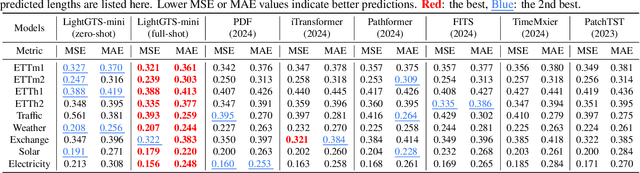
Existing works on general time series forecasting build foundation models with heavy model parameters through large-scale multi-source pre-training. These models achieve superior generalization ability across various datasets at the cost of significant computational burdens and limitations in resource-constrained scenarios. This paper introduces LightGTS, a lightweight general time series forecasting model designed from the perspective of consistent periodical modeling. To handle diverse scales and intrinsic periods in multi-source pre-training, we introduce Periodical Tokenization, which extracts consistent periodic patterns across different datasets with varying scales. To better utilize the periodicity in the decoding process, we further introduce Periodical Parallel Decoding, which leverages historical tokens to improve forecasting. Based on the two techniques above which fully leverage the inductive bias of periods inherent in time series, LightGTS uses a lightweight model to achieve outstanding performance on general time series forecasting. It achieves state-of-the-art forecasting performance on 9 real-world benchmarks in both zero-shot and full-shot settings with much better efficiency compared with existing time series foundation models.
ChronoSteer: Bridging Large Language Model and Time Series Foundation Model via Synthetic Data
May 15, 2025



Conventional forecasting methods rely on unimodal time series data, limiting their ability to exploit rich textual information. Recently, large language models (LLMs) and time series foundation models (TSFMs) have demonstrated powerful capability in textual reasoning and temporal modeling, respectively. Integrating the strengths of both to construct a multimodal model that concurrently leverages both temporal and textual information for future inference has emerged as a critical research challenge. To address the scarcity of event-series paired data, we propose a decoupled framework: an LLM is employed to transform textual events into revision instructions, which are then used to steer the output of TSFM. To implement this framework, we introduce ChronoSteer, a multimodal TSFM that can be steered through textual revision instructions, effectively bridging LLM and TSFM. Moreover, to mitigate the shortage of cross-modal instruction-series paired data, we devise a two-stage training strategy based on synthetic data. In addition, we also construct a high-quality multimodal time series forecasting benchmark to address the information leakage concerns during evaluation. After integrating with an LLM, ChronoSteer, which is trained exclusively on synthetic data, achieves a 25.7% improvement in prediction accuracy compared to the unimodal backbone and a 22.5% gain over the previous state-of-the-art multimodal method.
AimTS: Augmented Series and Image Contrastive Learning for Time Series Classification
Apr 14, 2025Time series classification (TSC) is an important task in time series analysis. Existing TSC methods mainly train on each single domain separately, suffering from a degradation in accuracy when the samples for training are insufficient in certain domains. The pre-training and fine-tuning paradigm provides a promising direction for solving this problem. However, time series from different domains are substantially divergent, which challenges the effective pre-training on multi-source data and the generalization ability of pre-trained models. To handle this issue, we introduce Augmented Series and Image Contrastive Learning for Time Series Classification (AimTS), a pre-training framework that learns generalizable representations from multi-source time series data. We propose a two-level prototype-based contrastive learning method to effectively utilize various augmentations in multi-source pre-training, which learns representations for TSC that can be generalized to different domains. In addition, considering augmentations within the single time series modality are insufficient to fully address classification problems with distribution shift, we introduce the image modality to supplement structural information and establish a series-image contrastive learning to improve the generalization of the learned representations for TSC tasks. Extensive experiments show that after multi-source pre-training, AimTS achieves good generalization performance, enabling efficient learning and even few-shot learning on various downstream TSC datasets.
Mantis: Lightweight Calibrated Foundation Model for User-Friendly Time Series Classification
Feb 21, 2025In recent years, there has been increasing interest in developing foundation models for time series data that can generalize across diverse downstream tasks. While numerous forecasting-oriented foundation models have been introduced, there is a notable scarcity of models tailored for time series classification. To address this gap, we present Mantis, a new open-source foundation model for time series classification based on the Vision Transformer (ViT) architecture that has been pre-trained using a contrastive learning approach. Our experimental results show that Mantis outperforms existing foundation models both when the backbone is frozen and when fine-tuned, while achieving the lowest calibration error. In addition, we propose several adapters to handle the multivariate setting, reducing memory requirements and modeling channel interdependence.
Air Quality Prediction with Physics-Informed Dual Neural ODEs in Open Systems
Oct 25, 2024
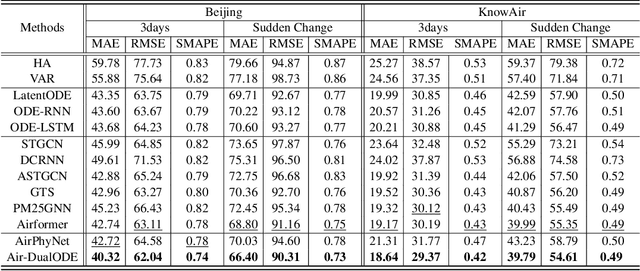
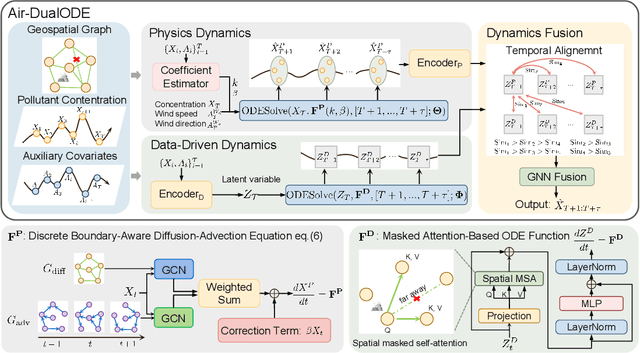
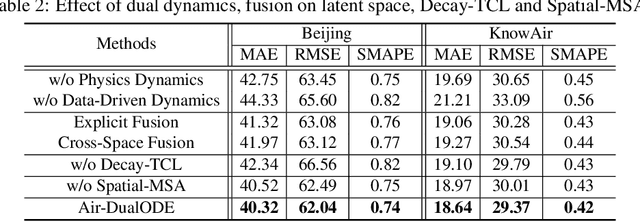
Air pollution significantly threatens human health and ecosystems, necessitating effective air quality prediction to inform public policy. Traditional approaches are generally categorized into physics-based and data-driven models. Physics-based models usually struggle with high computational demands and closed-system assumptions, while data-driven models may overlook essential physical dynamics, confusing the capturing of spatiotemporal correlations. Although some physics-informed approaches combine the strengths of both models, they often face a mismatch between explicit physical equations and implicit learned representations. To address these challenges, we propose Air-DualODE, a novel physics-informed approach that integrates dual branches of Neural ODEs for air quality prediction. The first branch applies open-system physical equations to capture spatiotemporal dependencies for learning physics dynamics, while the second branch identifies the dependencies not addressed by the first in a fully data-driven way. These dual representations are temporally aligned and fused to enhance prediction accuracy. Our experimental results demonstrate that Air-DualODE achieves state-of-the-art performance in predicting pollutant concentrations across various spatial scales, thereby offering a promising solution for real-world air quality challenges.
SEFraud: Graph-based Self-Explainable Fraud Detection via Interpretative Mask Learning
Jun 17, 2024



Graph-based fraud detection has widespread application in modern industry scenarios, such as spam review and malicious account detection. While considerable efforts have been devoted to designing adequate fraud detectors, the interpretability of their results has often been overlooked. Previous works have attempted to generate explanations for specific instances using post-hoc explaining methods such as a GNNExplainer. However, post-hoc explanations can not facilitate the model predictions and the computational cost of these methods cannot meet practical requirements, thus limiting their application in real-world scenarios. To address these issues, we propose SEFraud, a novel graph-based self-explainable fraud detection framework that simultaneously tackles fraud detection and result in interpretability. Concretely, SEFraud first leverages customized heterogeneous graph transformer networks with learnable feature masks and edge masks to learn expressive representations from the informative heterogeneously typed transactions. A new triplet loss is further designed to enhance the performance of mask learning. Empirical results on various datasets demonstrate the effectiveness of SEFraud as it shows considerable advantages in both the fraud detection performance and interpretability of prediction results. Moreover, SEFraud has been deployed and offers explainable fraud detection service for the largest bank in China, Industrial and Commercial Bank of China Limited (ICBC). Results collected from the production environment of ICBC show that SEFraud can provide accurate detection results and comprehensive explanations that align with the expert business understanding, confirming its efficiency and applicability in large-scale online services.
ROSE: Register Assisted General Time Series Forecasting with Decomposed Frequency Learning
May 24, 2024With the increasing collection of time series data from various domains, there arises a strong demand for general time series forecasting models pre-trained on a large number of time-series datasets to support a variety of downstream prediction tasks. Enabling general time series forecasting faces two challenges: how to obtain unified representations from multi-domian time series data, and how to capture domain-specific features from time series data across various domains for adaptive transfer in downstream tasks. To address these challenges, we propose a Register Assisted General Time Series Forecasting Model with Decomposed Frequency Learning (ROSE), a novel pre-trained model for time series forecasting. ROSE employs Decomposed Frequency Learning for the pre-training task, which decomposes coupled semantic and periodic information in time series with frequency-based masking and reconstruction to obtain unified representations across domains. We also equip ROSE with a Time Series Register, which learns to generate a register codebook to capture domain-specific representations during pre-training and enhances domain-adaptive transfer by selecting related register tokens on downstream tasks. After pre-training on large-scale time series data, ROSE achieves state-of-the-art forecasting performance on 8 real-world benchmarks. Remarkably, even in few-shot scenarios, it demonstrates competitive or superior performance compared to existing methods trained with full data.
Towards a General Time Series Anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders
May 24, 2024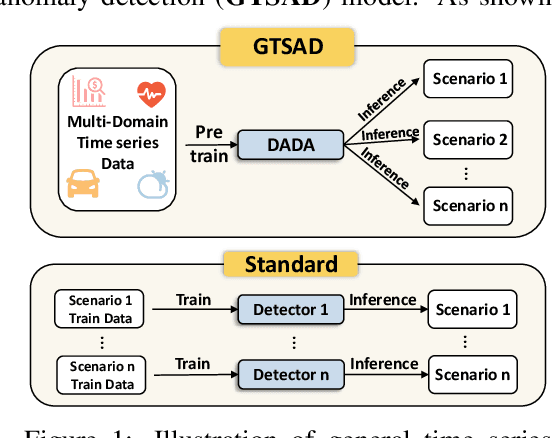
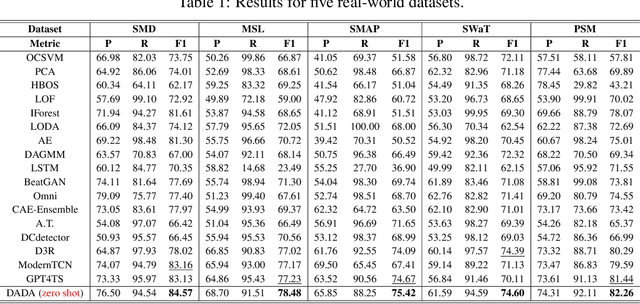


Time series anomaly detection plays a vital role in a wide range of applications. Existing methods require training one specific model for each dataset, which exhibits limited generalization capability across different target datasets, hindering anomaly detection performance in various scenarios with scarce training data. Aiming at this problem, we propose constructing a general time series anomaly detection model, which is pre-trained on extensive multi-domain datasets and can subsequently apply to a multitude of downstream scenarios. The significant divergence of time series data across different domains presents two primary challenges in building such a general model: (1) meeting the diverse requirements of appropriate information bottlenecks tailored to different datasets in one unified model, and (2) enabling distinguishment between multiple normal and abnormal patterns, both are crucial for effective anomaly detection in various target scenarios. To tackle these two challenges, we propose a General time series anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders (DADA), which enables flexible selection of bottlenecks based on different data and explicitly enhances clear differentiation between normal and abnormal series. We conduct extensive experiments on nine target datasets from different domains. After pre-training on multi-domain data, DADA, serving as a zero-shot anomaly detector for these datasets, still achieves competitive or even superior results compared to those models tailored to each specific dataset.