 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAVs Meet LLMs: Overviews and Perspectives Toward Agentic Low-Altitude Mobility
Jan 04, 2025Low-altitude mobility, exemplified by unmanned aerial vehicles (UAVs), has introduced transformative advancements across various domains, like transportation, logistics, and agriculture. Leveraging flexible perspectives and rapid maneuverability, UAVs extend traditional systems' perception and action capabilities, garnering widespread attention from academia and industry. However, current UAV operations primarily depend on human control, with only limited autonomy in simple scenarios, and lack the intelligence and adaptability needed for more complex environments and tasks. The emergence of large language models (LLMs) demonstrates remarkable problem-solving and generalization capabilities, offering a promising pathway for advancing UAV intelligence. This paper explores the integration of LLMs and UAVs, beginning with an overview of UAV systems' fundamental components and functionalities, followed by an overview of the state-of-the-art in LLM technology. Subsequently, it systematically highlights the multimodal data resources available for UAVs, which provide critical support for training and evaluation. Furthermore, it categorizes and analyzes key tasks and application scenarios where UAVs and LLMs converge. Finally, a reference roadmap towards agentic UAVs is proposed, aiming to enable UAVs to achieve agentic intelligence through autonomous perception, memory, reasoning, and tool utilization. Related resources are available at https://github.com/Hub-Tian/UAVs_Meet_LLMs.
Integer Scale: A Free Lunch for Faster Fine-grained Quantization of LLMs
May 23, 2024We introduce Integer Scale, a novel post-training quantization scheme for large language models that effectively resolves the inference bottleneck in current fine-grained quantization approaches while maintaining similar accuracies. Integer Scale is a free lunch as it requires no extra calibration or fine-tuning which will otherwise incur additional costs. It can be used plug-and-play for most fine-grained quantization methods. Its integration results in at most 1.85x end-to-end speed boost over the original counterpart with comparable accuracy. Additionally, due to the orchestration of the proposed Integer Scale and fine-grained quantization, we resolved the quantization difficulty for Mixtral-8x7B and LLaMA-3 models with negligible performance degradation, and it comes with an end-to-end speed boost of 2.13x, and 2.31x compared with their FP16 versions respectively.
Enhancing Multivariate Time Series Forecasting with Mutual Information-driven Cross-Variable and Temporal Modeling
Mar 01, 2024



Recent advancements have underscored the impact of deep learning techniques on multivariate time series forecasting (MTSF). Generally, these techniques are bifurcated into two categories: Channel-independence and Channel-mixing approaches. Although Channel-independence methods typically yield better results, Channel-mixing could theoretically offer improvements by leveraging inter-variable correlations. Nonetheless, we argue that the integration of uncorrelated information in channel-mixing methods could curtail the potential enhancement in MTSF model performance. To substantiate this claim, we introduce the Cross-variable Decorrelation Aware feature Modeling (CDAM) for Channel-mixing approaches, aiming to refine Channel-mixing by minimizing redundant information between channels while enhancing relevant mutual information. Furthermore, we introduce the Temporal correlation Aware Modeling (TAM) to exploit temporal correlations, a step beyond conventional single-step forecasting methods. This strategy maximizes the mutual information between adjacent sub-sequences of both the forecasted and target series. Combining CDAM and TAM, our novel framework significantly surpasses existing models, including those previously considered state-of-the-art, in comprehensive tests.
PDETime: Rethinking Long-Term Multivariate Time Series Forecasting from the perspective of partial differential equations
Feb 25, 2024


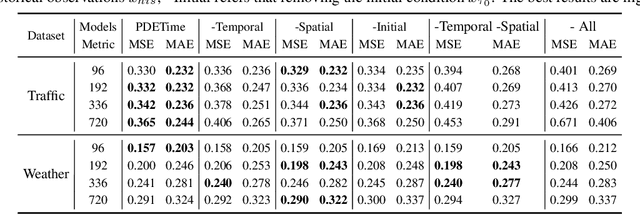
Recent advancements in deep learning have led to the development of various models for long-term multivariate time-series forecasting (LMTF), many of which have shown promising results. Generally, the focus has been on historical-value-based models, which rely on past observations to predict future series. Notably, a new trend has emerged with time-index-based models, offering a more nuanced understanding of the continuous dynamics underlying time series. Unlike these two types of models that aggregate the information of spatial domains or temporal domains, in this paper, we consider multivariate time series as spatiotemporal data regularly sampled from a continuous dynamical system, which can be represented by partial differential equations (PDEs), with the spatial domain being fixed. Building on this perspective, we present PDETime, a novel LMTF model inspired by the principles of Neural PDE solvers, following the encoding-integration-decoding operations. Our extensive experimentation across seven diverse real-world LMTF datasets reveals that PDETime not only adapts effectively to the intrinsic spatiotemporal nature of the data but also sets new benchmarks, achieving state-of-the-art results
A Speed Odyssey for Deployable Quantization of LLMs
Nov 16, 2023



The large language model era urges faster and less costly inference. Prior model compression works on LLMs tend to undertake a software-centric approach primarily focused on the simulated quantization performance. By neglecting the feasibility of deployment, these approaches are typically disabled in real practice. They used to drastically push down the quantization bit range for a reduced computation which might not be supported by the mainstream hardware, or involve sophisticated algorithms that introduce extra computation or memory access overhead. We argue that pursuing a hardware-centric approach in the construction of quantization algorithms is crucial. In this regard, we are driven to build our compression method on top of hardware awareness, eliminating impractical algorithm choices while maximizing the benefit of hardware acceleration. Our method, OdysseyLLM, comes with a novel W4A8 kernel implementation called FastGEMM and a combined recipe of quantization strategies. Extensive experiments manifest the superiority of our W4A8 method which brings the actual speed boosting up to \textbf{4$\times$} compared to Hugging Face FP16 inference and \textbf{2.23$\times$} vs. the state-of-the-art inference engine TensorRT-LLM in FP16, and \textbf{1.45$\times$} vs. TensorRT-LLM in INT8, yet without substantially harming the performance.
Revisiting Long-term Time Series Forecasting: An Investigation on Linear Mapping
May 18, 2023



Long-term time series forecasting has gained significant attention in recent years. While there are various specialized designs for capturing temporal dependency, previous studies have demonstrated that a single linear layer can achieve competitive forecasting performance compared to other complex architectures. In this paper, we thoroughly investigate the intrinsic effectiveness of recent approaches and make three key observations: 1) linear mapping is critical to prior long-term time series forecasting efforts; 2) RevIN (reversible normalization) and CI (Channel Independent) play a vital role in improving overall forecasting performance; and 3) linear mapping can effectively capture periodic features in time series and has robustness for different periods across channels when increasing the input horizon. We provide theoretical and experimental explanations to support our findings and also discuss the limitations and future works. Our framework's code is available at \url{https://github.com/plumprc/RTSF}.
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
Sep 07, 2022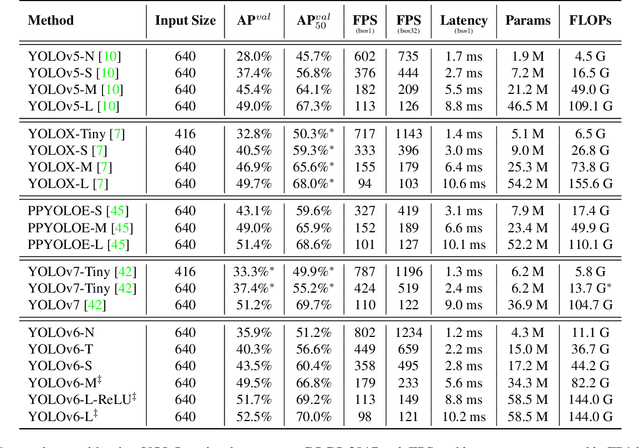
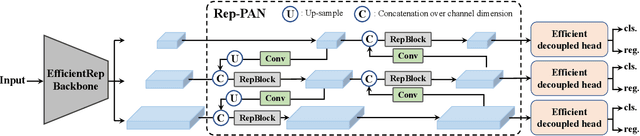
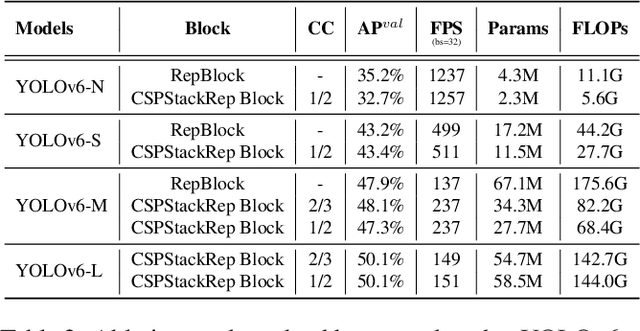
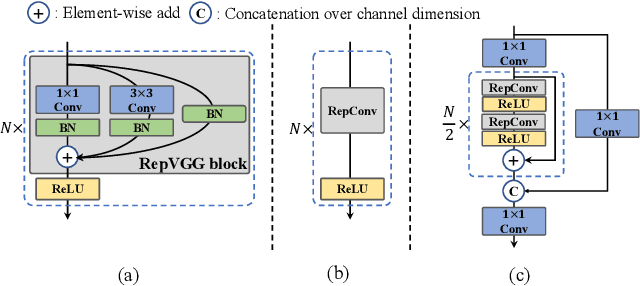
For years, the YOLO series has been the de facto industry-level standard for efficient object detection. The YOLO community has prospered overwhelmingly to enrich its use in a multitude of hardware platforms and abundant scenarios. In this technical report, we strive to push its limits to the next level, stepping forward with an unwavering mindset for industry application. Considering the diverse requirements for speed and accuracy in the real environment, we extensively examine the up-to-date object detection advancements either from industry or academia. Specifically, we heavily assimilate ideas from recent network design, training strategies, testing techniques, quantization, and optimization methods. On top of this, we integrate our thoughts and practice to build a suite of deployment-ready networks at various scales to accommodate diversified use cases. With the generous permission of YOLO authors, we name it YOLOv6. We also express our warm welcome to users and contributors for further enhancement. For a glimpse of performance, our YOLOv6-N hits 35.9% AP on the COCO dataset at a throughput of 1234 FPS on an NVIDIA Tesla T4 GPU. YOLOv6-S strikes 43.5% AP at 495 FPS, outperforming other mainstream detectors at the same scale~(YOLOv5-S, YOLOX-S, and PPYOLOE-S). Our quantized version of YOLOv6-S even brings a new state-of-the-art 43.3% AP at 869 FPS. Furthermore, YOLOv6-M/L also achieves better accuracy performance (i.e., 49.5%/52.3%) than other detectors with a similar inference speed. We carefully conducted experiments to validate the effectiveness of each component. Our code is made available at https://github.com/meituan/YOLOv6.