 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cosine Network for Image Super-Resolution
Jan 23, 2026Deep convolutional neural networks can use hierarchical information to progressively extract structural information to recover high-quality images. However, preserving the effectiveness of the obtained structural information is important in image super-resolution. In this paper, we propose a cosine network for image super-resolution (CSRNet) by improving a network architecture and optimizing the training strategy. To extract complementary homologous structural information, odd and even heterogeneous blocks are designed to enlarge the architectural differences and improve the performance of image super-resolution. Combining linear and non-linear structural information can overcome the drawback of homologous information and enhance the robustness of the obtained structural information in image super-resolution. Taking into account the local minimum of gradient descent, a cosine annealing mechanism is used to optimize the training procedure by performing warm restarts and adjusting the learning rate. Experimental results illustrate that the proposed CSRNet is competitive with state-of-the-art methods in image super-resolution.
CoopDiff: Anticipating 3D Human-object Interactions via Contact-consistent Decoupled Diffusion
Aug 10, 20253D human-object interaction (HOI) anticipation aims to predict the future motion of humans and their manipulated objects, conditioned on the historical context. Generally, the articulated humans and rigid objects exhibit different motion patterns, due to their distinct intrinsic physical properties. However, this distinction is ignored by most of the existing works, which intend to capture the dynamics of both humans and objects within a single prediction model. In this work, we propose a novel contact-consistent decoupled diffusion framework CoopDiff, which employs two distinct branches to decouple human and object motion modeling, with the human-object contact points as shared anchors to bridge the motion generation across branches. The human dynamics branch is aimed to predict highly structured human motion, while the object dynamics branch focuses on the object motion with rigid translations and rotations. These two branches are bridged by a series of shared contact points with consistency constraint for coherent human-object motion prediction. To further enhance human-object consistency and prediction reliability, we propose a human-driven interaction module to guide object motion modeling. Extensive experiments on the BEHAVE and Human-object Interaction datasets demonstrate that our CoopDiff outperforms state-of-the-art methods.
HeLo: Heterogeneous Multi-Modal Fusion with Label Correlation for Emotion Distribution Learning
Jul 09, 2025Multi-modal emotion recognition has garnered increasing attention as it plays a significant role in human-computer interaction (HCI) in recent years. Since different discrete emotions may exist at the same time, compared with single-class emotion recognition, emotion distribution learning (EDL) that identifies a mixture of basic emotions has gradually emerged as a trend. However, existing EDL methods face challenges in mining the heterogeneity among multiple modalities. Besides, rich semantic correlations across arbitrary basic emotions are not fully exploited. In this paper, we propose a multi-modal emotion distribution learning framework, named HeLo, aimed at fully exploring the heterogeneity and complementary information in multi-modal emotional data and label correlation within mixed basic emotions. Specifically, we first adopt cross-attention to effectively fuse the physiological data. Then, an optimal transport (OT)-based heterogeneity mining module is devised to mine the interaction and heterogeneity between the physiological and behavioral representations. To facilitate label correlation learning, we introduce a learnable label embedding optimized by correlation matrix alignment. Finally, the learnable label embeddings and label correlation matrices are integrated with the multi-modal representations through a novel label correlation-driven cross-attention mechanism for accurate emotion distribution learning. Experimental results on two publicly available datasets demonstrate the superiority of our proposed method in emotion distribution learning.
ViEEG: Hierarchical Neural Coding with Cross-Modal Progressive Enhancement for EEG-Based Visual Decoding
May 18, 2025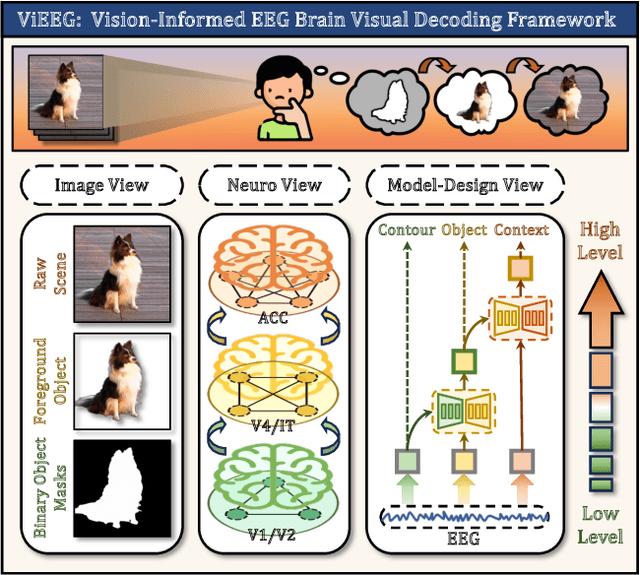


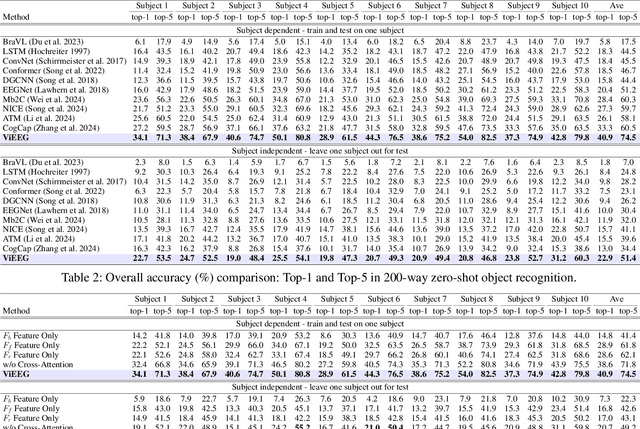
Understanding and decoding brain activity into visual representations is a fundamental challenge at the intersection of neuroscience and artificial intelligence. While EEG-based visual decoding has shown promise due to its non-invasive, low-cost nature and millisecond-level temporal resolution, existing methods are limited by their reliance on flat neural representations that overlook the brain's inherent visual hierarchy. In this paper, we introduce ViEEG, a biologically inspired hierarchical EEG decoding framework that aligns with the Hubel-Wiesel theory of visual processing. ViEEG decomposes each visual stimulus into three biologically aligned components-contour, foreground object, and contextual scene-serving as anchors for a three-stream EEG encoder. These EEG features are progressively integrated via cross-attention routing, simulating cortical information flow from V1 to IT to the association cortex. We further adopt hierarchical contrastive learning to align EEG representations with CLIP embeddings, enabling zero-shot object recognition. Extensive experiments on the THINGS-EEG dataset demonstrate that ViEEG achieves state-of-the-art performance, with 40.9% Top-1 accuracy in subject-dependent and 22.9% Top-1 accuracy in cross-subject settings, surpassing existing methods by over 45%. Our framework not only advances the performance frontier but also sets a new paradigm for biologically grounded brain decoding in AI.
UAVs Meet LLMs: Overviews and Perspectives Toward Agentic Low-Altitude Mobility
Jan 04, 2025Low-altitude mobility, exemplified by unmanned aerial vehicles (UAVs), has introduced transformative advancements across various domains, like transportation, logistics, and agriculture. Leveraging flexible perspectives and rapid maneuverability, UAVs extend traditional systems' perception and action capabilities, garnering widespread attention from academia and industry. However, current UAV operations primarily depend on human control, with only limited autonomy in simple scenarios, and lack the intelligence and adaptability needed for more complex environments and tasks. The emergence of large language models (LLMs) demonstrates remarkable problem-solving and generalization capabilities, offering a promising pathway for advancing UAV intelligence. This paper explores the integration of LLMs and UAVs, beginning with an overview of UAV systems' fundamental components and functionalities, followed by an overview of the state-of-the-art in LLM technology. Subsequently, it systematically highlights the multimodal data resources available for UAVs, which provide critical support for training and evaluation. Furthermore, it categorizes and analyzes key tasks and application scenarios where UAVs and LLMs converge. Finally, a reference roadmap towards agentic UAVs is proposed, aiming to enable UAVs to achieve agentic intelligence through autonomous perception, memory, reasoning, and tool utilization. Related resources are available at https://github.com/Hub-Tian/UAVs_Meet_LLMs.
Heterogeneous window transformer for image denoising
Jul 08, 2024Deep networks can usually depend on extracting more structural information to improve denoising results. However, they may ignore correlation between pixels from an image to pursue better denoising performance. Window transformer can use long- and short-distance modeling to interact pixels to address mentioned problem. To make a tradeoff between distance modeling and denoising time, we propose a heterogeneous window transformer (HWformer) for image denoising. HWformer first designs heterogeneous global windows to capture global context information for improving denoising effects. To build a bridge between long and short-distance modeling, global windows are horizontally and vertically shifted to facilitate diversified information without increasing denoising time. To prevent the information loss phenomenon of independent patches, sparse idea is guided a feed-forward network to extract local information of neighboring patches. The proposed HWformer only takes 30% of popular Restormer in terms of denoising time.
A self-supervised CNN for image watermark removal
Mar 09, 2024



Popular convolutional neural networks mainly use paired images in a supervised way for image watermark removal. However, watermarked images do not have reference images in the real world, which results in poor robustness of image watermark removal techniques. In this paper, we propose a self-supervised convolutional neural network (CNN) in image watermark removal (SWCNN). SWCNN uses a self-supervised way to construct reference watermarked images rather than given paired training samples, according to watermark distribution. A heterogeneous U-Net architecture is used to extract more complementary structural information via simple components for image watermark removal. Taking into account texture information, a mixed loss is exploited to improve visual effects of image watermark removal. Besides, a watermark dataset is conducted. Experimental results show that the proposed SWCNN is superior to popular CNNs in image watermark removal.
Perceptive self-supervised learning network for noisy image watermark removal
Mar 04, 2024Popular methods usually use a degradation model in a supervised way to learn a watermark removal model. However, it is true that reference images are difficult to obtain in the real world, as well as collected images by cameras suffer from noise. To overcome these drawbacks, we propose a perceptive self-supervised learning network for noisy image watermark removal (PSLNet) in this paper. PSLNet depends on a parallel network to remove noise and watermarks. The upper network uses task decomposition ideas to remove noise and watermarks in sequence. The lower network utilizes the degradation model idea to simultaneously remove noise and watermarks. Specifically, mentioned paired watermark images are obtained in a self supervised way, and paired noisy images (i.e., noisy and reference images) are obtained in a supervised way. To enhance the clarity of obtained images, interacting two sub-networks and fusing obtained clean images are used to improve the effects of image watermark removal in terms of structural information and pixel enhancement. Taking into texture information account, a mixed loss uses obtained images and features to achieve a robust model of noisy image watermark removal. Comprehensive experiments show that our proposed method is very effective in comparison with popular convolutional neural networks (CNNs) for noisy image watermark removal. Codes can be obtained at https://github.com/hellloxiaotian/PSLNet.
A Heterogeneous Dynamic Convolutional Neural Network for Image Super-resolution
Feb 24, 2024



Convolutional neural networks can automatically learn features via deep network architectures and given input samples. However, robustness of obtained models may have challenges in varying scenes. Bigger differences of a network architecture are beneficial to extract more complementary structural information to enhance robustness of an obtained super-resolution model. In this paper, we present a heterogeneous dynamic convolutional network in image super-resolution (HDSRNet). To capture more information, HDSRNet is implemented by a heterogeneous parallel network. The upper network can facilitate more contexture information via stacked heterogeneous blocks to improve effects of image super-resolution. Each heterogeneous block is composed of a combination of a dilated, dynamic, common convolutional layers, ReLU and residual learning operation. It can not only adaptively adjust parameters, according to different inputs, but also prevent long-term dependency problem. The lower network utilizes a symmetric architecture to enhance relations of different layers to mine more structural information, which is complementary with a upper network for image super-resolution. The relevant experimental results show that the proposed HDSRNet is effective to deal with image resolving. The code of HDSRNet can be obtained at https://github.com/hellloxiaotian/HDSRNet.
A cross Transformer for image denoising
Oct 16, 2023
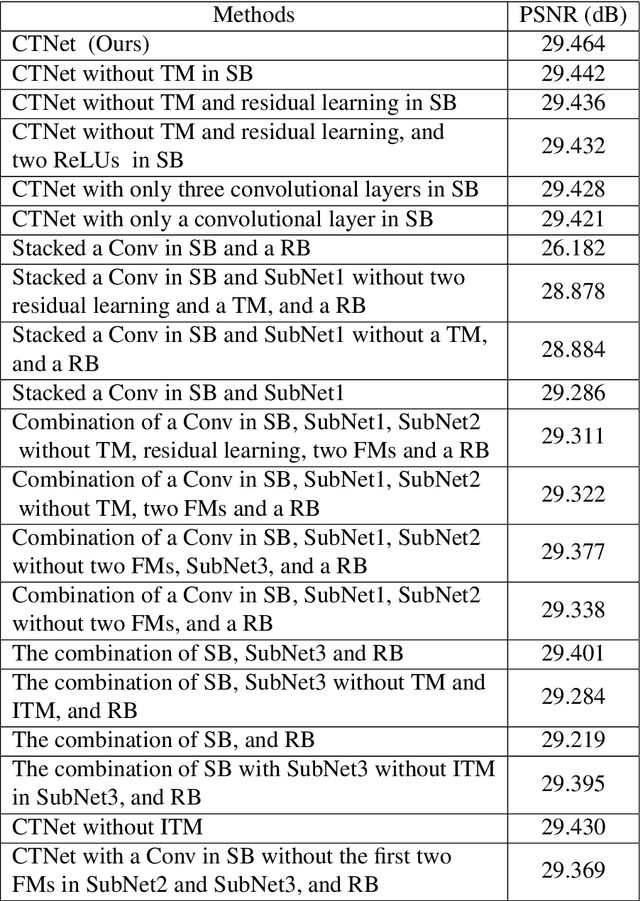
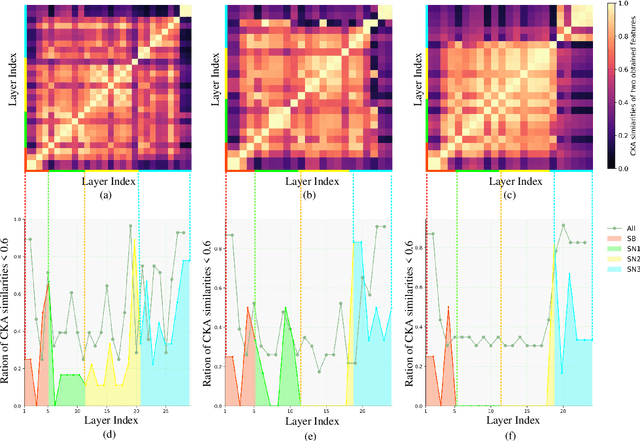

Deep convolutional neural networks (CNNs) depend on feedforward and feedback ways to obtain good performance in image denoising. However, how to obtain effective structural information via CNNs to efficiently represent given noisy images is key for complex scenes. In this paper, we propose a cross Transformer denoising CNN (CTNet) with a serial block (SB), a parallel block (PB), and a residual block (RB) to obtain clean images for complex scenes. A SB uses an enhanced residual architecture to deeply search structural information for image denoising. To avoid loss of key information, PB uses three heterogeneous networks to implement multiple interactions of multi-level features to broadly search for extra information for improving the adaptability of an obtained denoiser for complex scenes. Also, to improve denoising performance, Transformer mechanisms are embedded into the SB and PB to extract complementary salient features for effectively removing noise in terms of pixel relations. Finally, a RB is applied to acquire clean images. Experiments illustrate that our CTNet is superior to some popular denoising methods in terms of real and synthetic image denoising. It is suitable to mobile digital devices, i.e., phones. Codes can be obtained at https://github.com/hellloxiaotian/CTNet.