 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Dive into Scaling RL for Code Generation with Synthetic Data and Curricula
Mar 25, 2026Reinforcement learning (RL) has emerged as a powerful paradigm for improving large language models beyond supervised fine-tuning, yet sustaining performance gains at scale remains an open challenge, as data diversity and structure, rather than volume alone, become the limiting factor. We address this by introducing a scalable multi-turn synthetic data generation pipeline in which a teacher model iteratively refines problems based on in-context student performance summaries, producing structured difficulty progressions without any teacher fine-tuning. Compared to single-turn generation, this multi-turn approach substantially improves the yield of valid synthetic problems and naturally produces stepping stones, i.e. easier and harder variants of the same core task, that support curriculum-based training. We systematically study how task difficulty, curriculum scheduling, and environment diversity interact during RL training across the Llama3.1-8B Instruct and Qwen3-8B Base model families, with additional scaling experiments on Qwen2.5-32B. Our results show that synthetic augmentation consistently improves in-domain code and in most cases out-of-domain math performance, and we provide empirical insights into how curriculum design and data diversity jointly shape RL training dynamics.
Prompt Tuning for CLIP on the Pretrained Manifold
Feb 22, 2026Prompt tuning introduces learnable prompt vectors that adapt pretrained vision-language models to downstream tasks in a parameter-efficient manner. However, under limited supervision, prompt tuning alters pretrained representations and drives downstream features away from the pretrained manifold toward directions that are unfavorable for transfer. This drift degrades generalization. To address this limitation, we propose ManiPT, a framework that performs prompt tuning on the pretrained manifold. ManiPT introduces cosine consistency constraints in both the text and image modalities to confine the learned representations within the pretrained geometric neighborhood. Furthermore, we introduce a structural bias that enforces incremental corrections, guiding the adaptation along transferable directions to mitigate reliance on shortcut learning. From a theoretical perspective, ManiPT alleviates overfitting tendencies under limited data. Our experiments cover four downstream settings: unseen-class generalization, few-shot classification, cross-dataset transfer, and domain generalization. Across these settings, ManiPT achieves higher average performance than baseline methods. Notably, ManiPT provides an explicit perspective on how prompt tuning overfits under limited supervision.
Dynamic Prior Thompson Sampling for Cold-Start Exploration in Recommender Systems
Feb 01, 2026Cold-start exploration is a core challenge in large-scale recommender systems: new or data-sparse items must receive traffic to estimate value, but over-exploration harms users and wastes impressions. In practice, Thompson Sampling (TS) is often initialized with a uniform Beta(1,1) prior, implicitly assuming a 50% success rate for unseen items. When true base rates are far lower, this optimistic prior systematically over-allocates to weak items. The impact is amplified by batched policy updates and pipeline latency: for hours, newly launched items can remain effectively "no data," so the prior dominates allocation before feedback is incorporated. We propose Dynamic Prior Thompson Sampling, a prior design that directly controls the probability that a new arm outcompetes the incumbent winner. Our key contribution is a closed-form quadratic solution for the prior mean that enforces P(X_j > Y_k) = epsilon at introduction time, making exploration intensity predictable and tunable while preserving TS Bayesian updates. Across Monte Carlo validation, offline batched simulations, and a large-scale online experiment on a thumbnail personalization system serving millions of users, dynamic priors deliver precise exploration control and improved efficiency versus a uniform-prior baseline.
A Cosine Network for Image Super-Resolution
Jan 23, 2026Deep convolutional neural networks can use hierarchical information to progressively extract structural information to recover high-quality images. However, preserving the effectiveness of the obtained structural information is important in image super-resolution. In this paper, we propose a cosine network for image super-resolution (CSRNet) by improving a network architecture and optimizing the training strategy. To extract complementary homologous structural information, odd and even heterogeneous blocks are designed to enlarge the architectural differences and improve the performance of image super-resolution. Combining linear and non-linear structural information can overcome the drawback of homologous information and enhance the robustness of the obtained structural information in image super-resolution. Taking into account the local minimum of gradient descent, a cosine annealing mechanism is used to optimize the training procedure by performing warm restarts and adjusting the learning rate. Experimental results illustrate that the proposed CSRNet is competitive with state-of-the-art methods in image super-resolution.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Toward Training Superintelligent Software Agents through Self-Play SWE-RL
Dec 21, 2025While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer productivity, their training data (e.g., GitHub issues and pull requests) and environments (e.g., pass-to-pass and fail-to-pass tests) heavily depend on human knowledge or curation, posing a fundamental barrier to superintelligence. In this paper, we present Self-play SWE-RL (SSR), a first step toward training paradigms for superintelligent software agents. Our approach takes minimal data assumptions, only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests. Grounded in these real-world codebases, a single LLM agent is trained via reinforcement learning in a self-play setting to iteratively inject and repair software bugs of increasing complexity, with each bug formally specified by a test patch rather than a natural language issue description. On the SWE-bench Verified and SWE-Bench Pro benchmarks, SSR achieves notable self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms the human-data baseline over the entire training trajectory, despite being evaluated on natural language issues absent from self-play. Our results, albeit early, suggest a path where agents autonomously gather extensive learning experiences from real-world software repositories, ultimately enabling superintelligent systems that exceed human capabilities in understanding how systems are constructed, solving novel challenges, and autonomously creating new software from scratch.
Unsupervised Robust Domain Adaptation: Paradigm, Theory and Algorithm
Nov 14, 2025Unsupervised domain adaptation (UDA) aims to transfer knowledge from a label-rich source domain to an unlabeled target domain by addressing domain shifts. Most UDA approaches emphasize transfer ability, but often overlook robustness against adversarial attacks. Although vanilla adversarial training (VAT) improves the robustness of deep neural networks, it has little effect on UDA. This paper focuses on answering three key questions: 1) Why does VAT, known for its defensive effectiveness, fail in the UDA paradigm? 2) What is the generalization bound theory under attacks and how does it evolve from classical UDA theory? 3) How can we implement a robustification training procedure without complex modifications? Specifically, we explore and reveal the inherent entanglement challenge in general UDA+VAT paradigm, and propose an unsupervised robust domain adaptation (URDA) paradigm. We further derive the generalization bound theory of the URDA paradigm so that it can resist adversarial noise and domain shift. To the best of our knowledge, this is the first time to establish the URDA paradigm and theory. We further introduce a simple, novel yet effective URDA algorithm called Disentangled Adversarial Robustness Training (DART), a two-step training procedure that ensures both transferability and robustness. DART first pre-trains an arbitrary UDA model, and then applies an instantaneous robustification post-training step via disentangled distillation.Experiments on four benchmark datasets with/without attacks show that DART effectively enhances robustness while maintaining domain adaptability, and validate the URDA paradigm and theory.
Domain Gating Ensemble Networks for AI-Generated Text Detection
May 20, 2025As state-of-the-art language models continue to improve, the need for robust detection of machine-generated text becomes increasingly critical. However, current state-of-the-art machine text detectors struggle to adapt to new unseen domains and generative models. In this paper we present DoGEN (Domain Gating Ensemble Networks), a technique that allows detectors to adapt to unseen domains by ensembling a set of domain expert detector models using weights from a domain classifier. We test DoGEN on a wide variety of domains from leading benchmarks and find that it achieves state-of-the-art performance on in-domain detection while outperforming models twice its size on out-of-domain detection. We release our code and trained models to assist in future research in domain-adaptive AI detection.
Compact Recurrent Transformer with Persistent Memory
May 02, 2025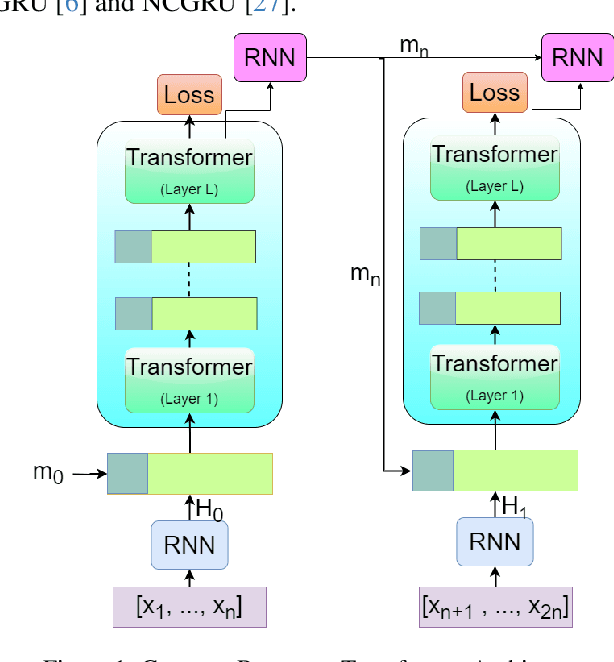
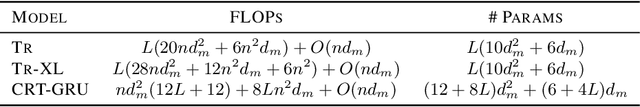
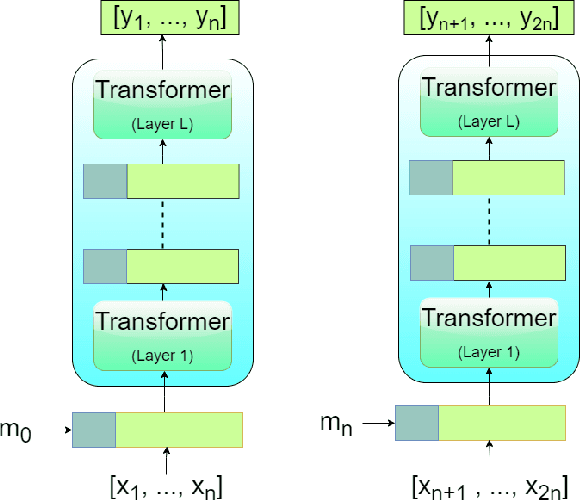
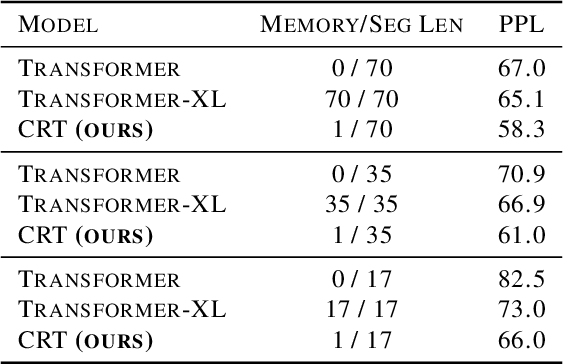
The Transformer architecture has shown significant success in many language processing and visual tasks. However, the method faces challenges in efficiently scaling to long sequences because the self-attention computation is quadratic with respect to the input length. To overcome this limitation, several approaches scale to longer sequences by breaking long sequences into a series of segments, restricting self-attention to local dependencies between tokens within each segment and using a memory mechanism to manage information flow between segments. However, these approached generally introduce additional compute overhead that restricts them from being used for applications where limited compute memory and power are of great concern (such as edge computing). We propose a novel and efficient Compact Recurrent Transformer (CRT), which combines shallow Transformer models that process short local segments with recurrent neural networks to compress and manage a single persistent memory vector that summarizes long-range global information between segments. We evaluate CRT on WordPTB and WikiText-103 for next-token-prediction tasks, as well as on the Toyota Smarthome video dataset for classification. CRT achieves comparable or superior prediction results to full-length Transformers in the language datasets while using significantly shorter segments (half or quarter size) and substantially reduced FLOPs. Our approach also demonstrates state-of-the-art performance on the Toyota Smarthome video dataset.
CaLMFlow: Volterra Flow Matching using Causal Language Models
Oct 03, 2024We introduce CaLMFlow (Causal Language Models for Flow Matching), a novel framework that casts flow matching as a Volterra integral equation (VIE), leveraging the power of large language models (LLMs) for continuous data generation. CaLMFlow enables the direct application of LLMs to learn complex flows by formulating flow matching as a sequence modeling task, bridging discrete language modeling and continuous generative modeling. Our method implements tokenization across space and time, thereby solving a VIE over these domains. This approach enables efficient handling of high-dimensional data and outperforms ODE solver-dependent methods like conditional flow matching (CFM). We demonstrate CaLMFlow's effectiveness on synthetic and real-world data, including single-cell perturbation response prediction, showcasing its ability to incorporate textual context and generalize to unseen conditions. Our results highlight LLM-driven flow matching as a promising paradigm in generative modeling, offering improved scalability, flexibility, and context-awareness.