 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDGCN: An Edge-End Lightweight Dual GCN Based on Single-Channel EEG for Driver Drowsiness Monitoring
Jul 08, 2024



Driver drowsiness electroencephalography (EEG) signal monitoring can timely alert drivers of their drowsiness status, thereby reducing the probability of traffic accidents. Graph convolutional networks (GCNs) have shown significant advancements in processing the non-stationary, time-varying, and non-Euclidean nature of EEG signals. However, the existing single-channel EEG adjacency graph construction process lacks interpretability, which hinders the ability of GCNs to effectively extract adjacency graph features, thus affecting the performance of drowsiness monitoring. To address this issue, we propose an edge-end lightweight dual graph convolutional network (LDGCN). Specifically, we are the first to incorporate neurophysiological knowledge to design a Baseline Drowsiness Status Adjacency Graph (BDSAG), which characterizes driver drowsiness status. Additionally, to express more features within limited EEG data, we introduce the Augmented Graph-level Module (AGM). This module captures global and local information at the graph level, ensuring that BDSAG features remain intact while enhancing effective feature expression capability. Furthermore, to deploy our method on the fourth-generation Raspberry Pi, we utilize Adaptive Pruning Optimization (APO) on both channels and neurons, reducing inference latency by almost half. Experiments on benchmark datasets demonstrate that LDGCN offers the best trade-off between monitoring performance and hardware resource utilization compared to existing state-of-the-art algorithms. All our source code can be found at https://github.com/BryantDom/Driver-Drowsiness-Monitoring.
SIAVC: Semi-Supervised Framework for Industrial Accident Video Classification
May 23, 2024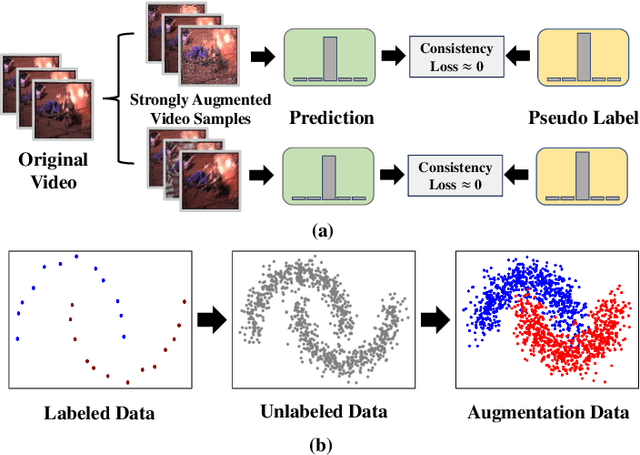
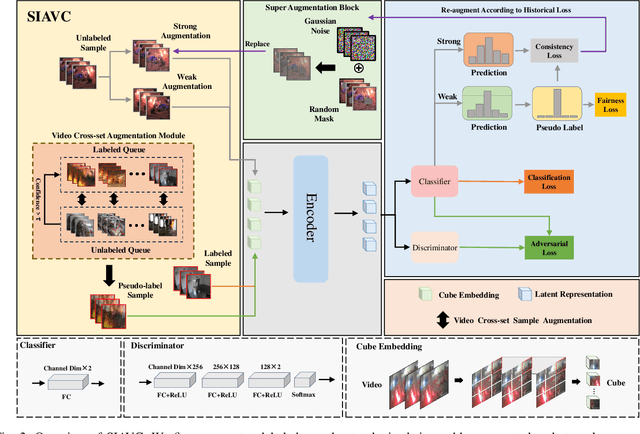
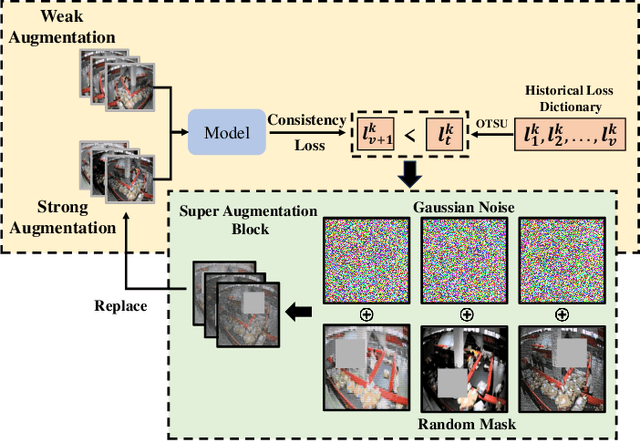
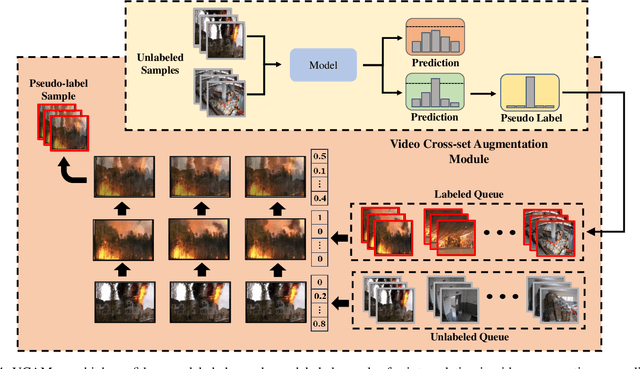
Semi-supervised learning suffers from the imbalance of labeled and unlabeled training data in the video surveillance scenario. In this paper, we propose a new semi-supervised learning method called SIAVC for industrial accident video classification. Specifically, we design a video augmentation module called the Super Augmentation Block (SAB). SAB adds Gaussian noise and randomly masks video frames according to historical loss on the unlabeled data for model optimization. Then, we propose a Video Cross-set Augmentation Module (VCAM) to generate diverse pseudo-label samples from the high-confidence unlabeled samples, which alleviates the mismatch of sampling experience and provides high-quality training data. Additionally, we construct a new industrial accident surveillance video dataset with frame-level annotation, namely ECA9, to evaluate our proposed method. Compared with the state-of-the-art semi-supervised learning based methods, SIAVC demonstrates outstanding video classification performance, achieving 88.76\% and 89.13\% accuracy on ECA9 and Fire Detection datasets, respectively. The source code and the constructed dataset ECA9 will be released in \url{https://github.com/AlchemyEmperor/SIAVC}.
FireMatch: A Semi-Supervised Video Fire Detection Network Based on Consistency and Distribution Alignment
Nov 09, 2023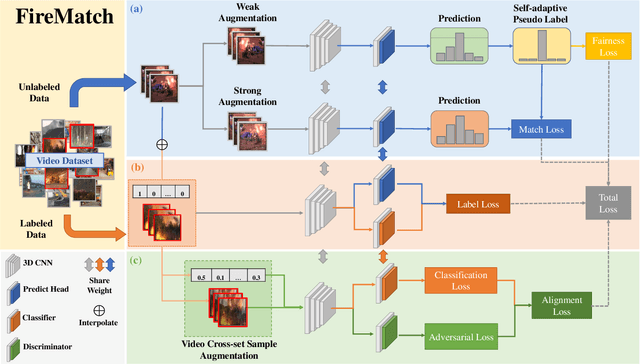
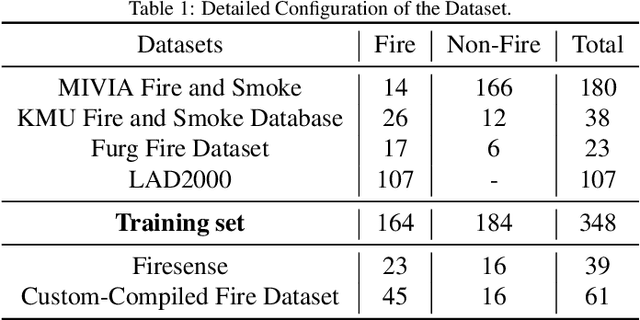
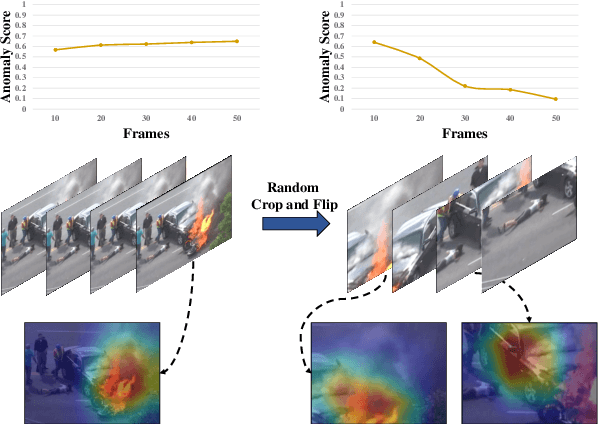
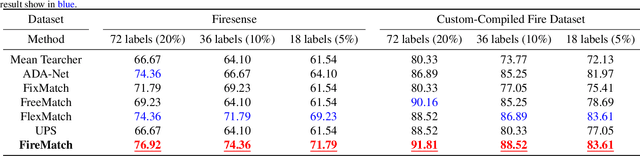
Deep learning techniques have greatly enhanced the performance of fire detection in videos. However, video-based fire detection models heavily rely on labeled data, and the process of data labeling is particularly costly and time-consuming, especially when dealing with videos. Considering the limited quantity of labeled video data, we propose a semi-supervised fire detection model called FireMatch, which is based on consistency regularization and adversarial distribution alignment. Specifically, we first combine consistency regularization with pseudo-label. For unlabeled data, we design video data augmentation to obtain corresponding weakly augmented and strongly augmented samples. The proposed model predicts weakly augmented samples and retains pseudo-label above a threshold, while training on strongly augmented samples to predict these pseudo-labels for learning more robust feature representations. Secondly, we generate video cross-set augmented samples by adversarial distribution alignment to expand the training data and alleviate the decline in classification performance caused by insufficient labeled data. Finally, we introduce a fairness loss to help the model produce diverse predictions for input samples, thereby addressing the issue of high confidence with the non-fire class in fire classification scenarios. The FireMatch achieved an accuracy of 76.92% and 91.81% on two real-world fire datasets, respectively. The experimental results demonstrate that the proposed method outperforms the current state-of-the-art semi-supervised classification methods.
Contrastive Proposal Extension with LSTM Network for Weakly Supervised Object Detection
Oct 16, 2021


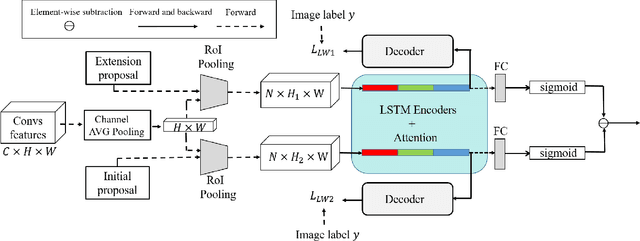
Weakly supervised object detection (WSOD) has attracted more and more attention since it only uses image-level labels and can save huge annotation costs. Most of the WSOD methods use Multiple Instance Learning (MIL) as their basic framework, which regard it as an instance classification problem. However, these methods based on MIL tends to converge only on the most discriminate regions of different instances, rather than their corresponding complete regions, that is, insufficient integrity. Inspired by the habit of observing things by the human, we propose a new method by comparing the initial proposals and the extension ones to optimize those initial proposals. Specifically, we propose one new strategy for WSOD by involving contrastive proposal extension (CPE), which consists of multiple directional contrastive proposal extensions (D-CPE), and each D-CPE contains encoders based on LSTM network and corresponding decoders. Firstly, the boundary of initial proposals in MIL is extended to different positions according to well-designed sequential order. Then, CPE compares the extended proposal and the initial proposal by extracting the feature semantics of them using the encoders, and calculates the integrity of the initial proposal to optimize the score of the initial proposal. These contrastive contextual semantics will guide the basic WSOD to suppress bad proposals and improve the scores of good ones. In addition, a simple two-stream network is designed as the decoder to constrain the temporal coding of LSTM and improve the performance of WSOD further. Experiments on PASCAL VOC 2007, VOC 2012 and MS-COCO datasets show that our method has achieved the state-of-the-art results.
Deep Dual Support Vector Data Description for Anomaly Detection on Attributed Networks
Sep 01, 2021
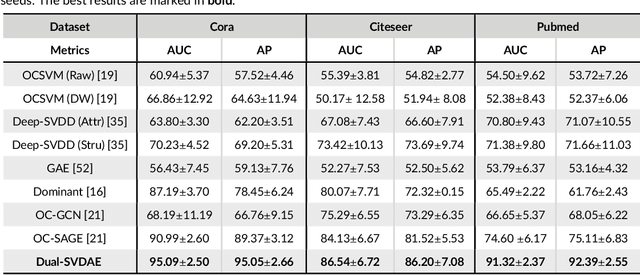
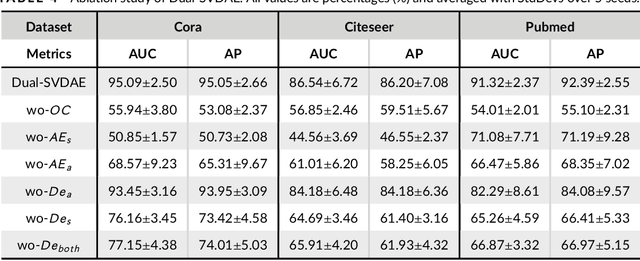
Networks are ubiquitous in the real world such as social networks and communication networks, and anomaly detection on networks aims at finding nodes whose structural or attributed patterns deviate significantly from the majority of reference nodes. However, most of the traditional anomaly detection methods neglect the relation structure information among data points and therefore cannot effectively generalize to the graph structure data. In this paper, we propose an end-to-end model of Deep Dual Support Vector Data description based Autoencoder (Dual-SVDAE) for anomaly detection on attributed networks, which considers both the structure and attribute for attributed networks. Specifically, Dual-SVDAE consists of a structure autoencoder and an attribute autoencoder to learn the latent representation of the node in the structure space and attribute space respectively. Then, a dual-hypersphere learning mechanism is imposed on them to learn two hyperspheres of normal nodes from the structure and attribute perspectives respectively. Moreover, to achieve joint learning between the structure and attribute of the network, we fuse the structure embedding and attribute embedding as the final input of the feature decoder to generate the node attribute. Finally, abnormal nodes can be detected by measuring the distance of nodes to the learned center of each hypersphere in the latent structure space and attribute space respectively. Extensive experiments on the real-world attributed networks show that Dual-SVDAE consistently outperforms the state-of-the-arts, which demonstrates the effectiveness of the proposed method.
Self-Supervised Time Series Representation Learning by Inter-Intra Relational Reasoning
Nov 27, 2020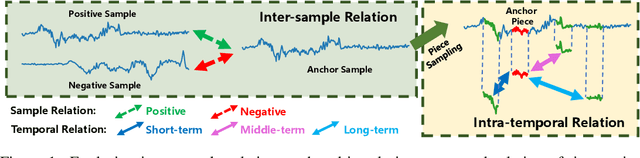
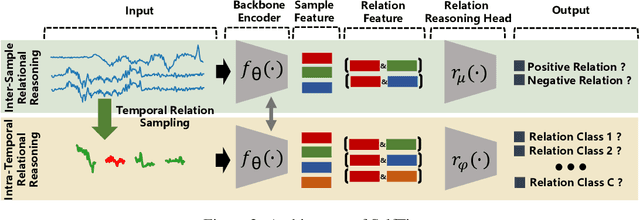
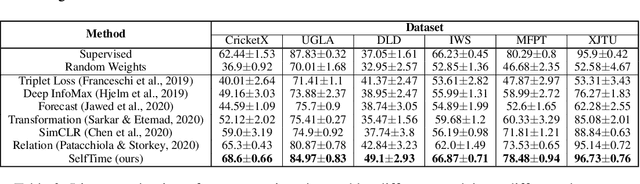
Self-supervised learning achieves superior performance in many domains by extracting useful representations from the unlabeled data. However, most of traditional self-supervised methods mainly focus on exploring the inter-sample structure while less efforts have been concentrated on the underlying intra-temporal structure, which is important for time series data. In this paper, we present SelfTime: a general self-supervised time series representation learning framework, by exploring the inter-sample relation and intra-temporal relation of time series to learn the underlying structure feature on the unlabeled time series. Specifically, we first generate the inter-sample relation by sampling positive and negative samples of a given anchor sample, and intra-temporal relation by sampling time pieces from this anchor. Then, based on the sampled relation, a shared feature extraction backbone combined with two separate relation reasoning heads are employed to quantify the relationships of the sample pairs for inter-sample relation reasoning, and the relationships of the time piece pairs for intra-temporal relation reasoning, respectively. Finally, the useful representations of time series are extracted from the backbone under the supervision of relation reasoning heads. Experimental results on multiple real-world time series datasets for time series classification task demonstrate the effectiveness of the proposed method. Code and data are publicly available at https://haoyfan.github.io/.
Correlation-aware Deep Generative Model for Unsupervised Anomaly Detection
Feb 18, 2020
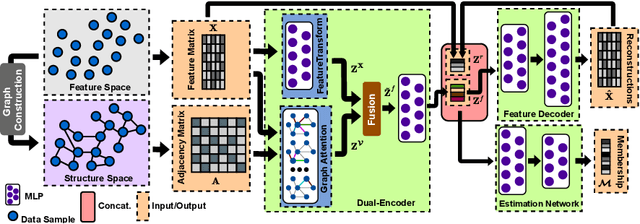
Unsupervised anomaly detection aims to identify anomalous samples from highly complex and unstructured data, which is pervasive in both fundamental research and industrial applications. However, most existing methods neglect the complex correlation among data samples, which is important for capturing normal patterns from which the abnormal ones deviate. In this paper, we propose a method of Correlation aware unsupervised Anomaly detection via Deep Gaussian Mixture Model (CADGMM), which captures the complex correlation among data points for high-quality low-dimensional representation learning. Specifically, the relations among data samples are correlated firstly in forms of a graph structure, in which, the node denotes the sample and the edge denotes the correlation between two samples from the feature space. Then, a dual-encoder that consists of a graph encoder and a feature encoder, is employed to encode both the feature and correlation information of samples into the low-dimensional latent space jointly, followed by a decoder for data reconstruction. Finally, a separate estimation network as a Gaussian Mixture Model is utilized to estimate the density of the learned latent vector, and the anomalies can be detected by measuring the energy of the samples. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed method.
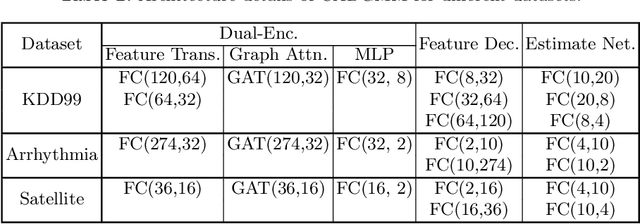
AnomalyDAE: Dual autoencoder for anomaly detection on attributed networks
Feb 12, 2020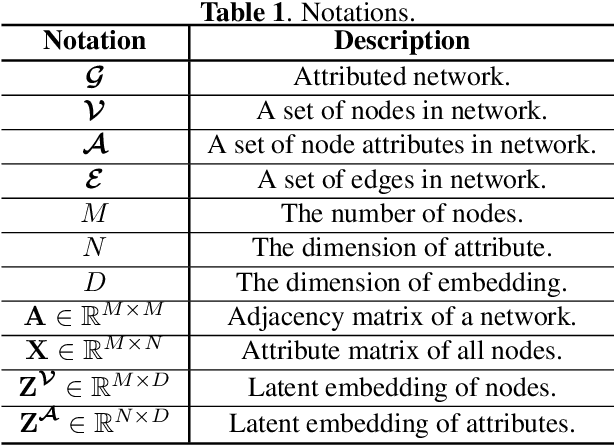
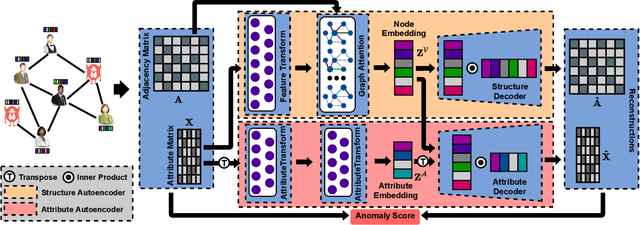
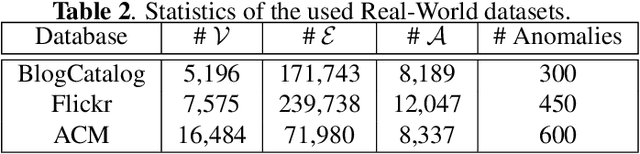
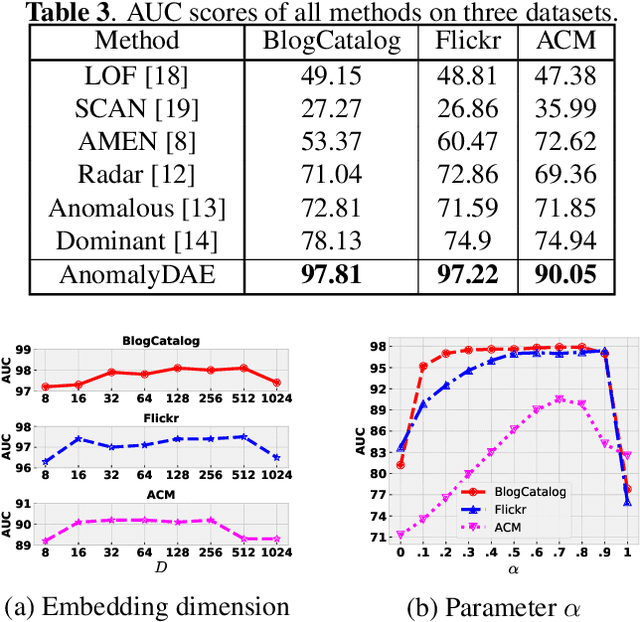
Anomaly detection on attributed networks aims at finding nodes whose patterns deviate significantly from the majority of reference nodes, which is pervasive in many applications such as network intrusion detection and social spammer detection. However, most existing methods neglect the complex cross-modality interactions between network structure and node attribute. In this paper, we propose a deep joint representation learning framework for anomaly detection through a dual autoencoder (AnomalyDAE), which captures the complex interactions between network structure and node attribute for high-quality embeddings. Specifically, AnomalyDAE consists of a structure autoencoder and an attribute autoencoder to learn both node embedding and attribute embedding jointly in latent space. Moreover, attention mechanism is employed in structure encoder to learn the importance between a node and its neighbors for an effective capturing of structure pattern, which is important to anomaly detection. Besides, by taking both the node embedding and attribute embedding as inputs of attribute decoder, the cross-modality interactions between network structure and node attribute are learned during the reconstruction of node attribute. Finally, anomalies can be detected by measuring the reconstruction errors of nodes from both the structure and attribute perspectives. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed method.