 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Realistic Low-Light Image Enhancement via ISP Driven Data Modeling
Apr 16, 2025
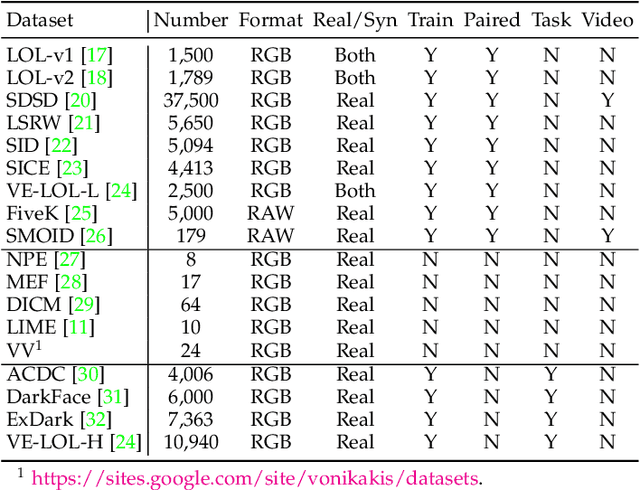
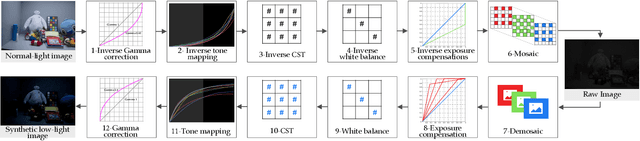
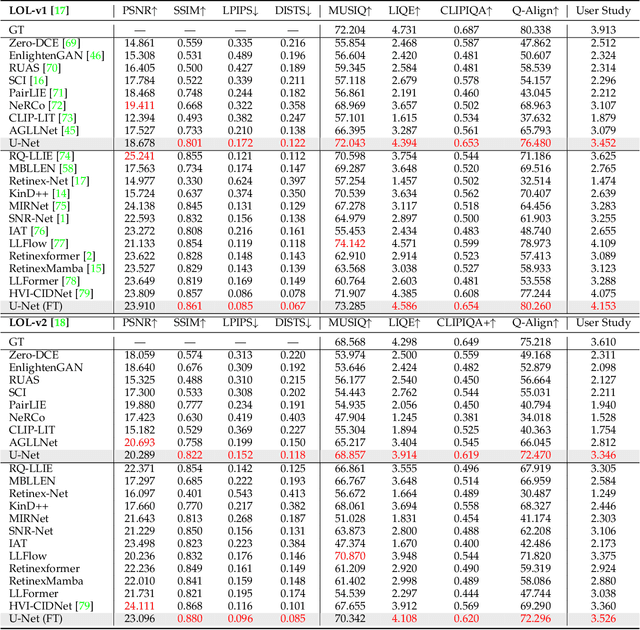
Deep neural networks (DNNs) have recently become the leading method for low-light image enhancement (LLIE). However, despite significant progress, their outputs may still exhibit issues such as amplified noise, incorrect white balance, or unnatural enhancements when deployed in real world applications. A key challenge is the lack of diverse, large scale training data that captures the complexities of low-light conditions and imaging pipelines. In this paper, we propose a novel image signal processing (ISP) driven data synthesis pipeline that addresses these challenges by generating unlimited paired training data. Specifically, our pipeline begins with easily collected high-quality normal-light images, which are first unprocessed into the RAW format using a reverse ISP. We then synthesize low-light degradations directly in the RAW domain. The resulting data is subsequently processed through a series of ISP stages, including white balance adjustment, color space conversion, tone mapping, and gamma correction, with controlled variations introduced at each stage. This broadens the degradation space and enhances the diversity of the training data, enabling the generated data to capture a wide range of degradations and the complexities inherent in the ISP pipeline. To demonstrate the effectiveness of our synthetic pipeline, we conduct extensive experiments using a vanilla UNet model consisting solely of convolutional layers, group normalization, GeLU activation, and convolutional block attention modules (CBAMs). Extensive testing across multiple datasets reveals that the vanilla UNet model trained with our data synthesis pipeline delivers high fidelity, visually appealing enhancement results, surpassing state-of-the-art (SOTA) methods both quantitatively and qualitatively.
SIAVC: Semi-Supervised Framework for Industrial Accident Video Classification
May 23, 2024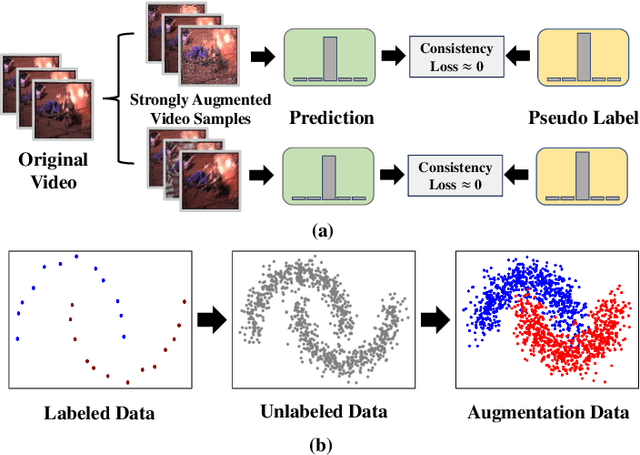
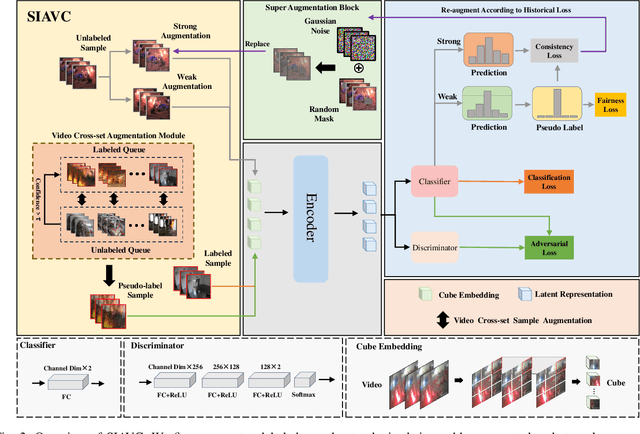
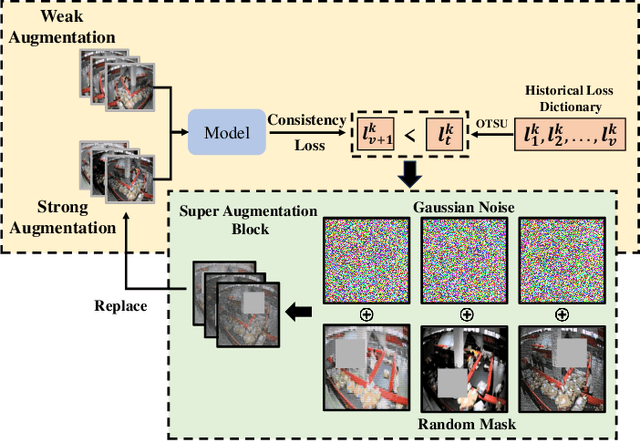
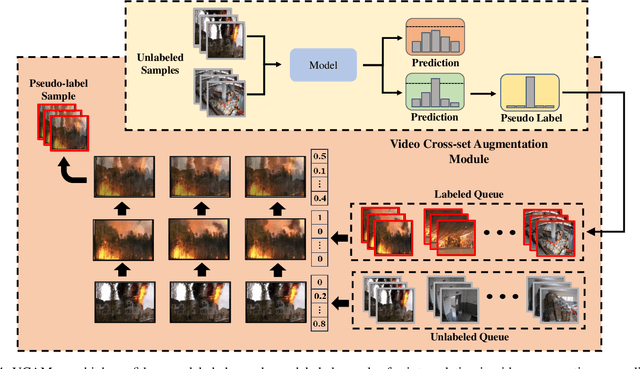
Semi-supervised learning suffers from the imbalance of labeled and unlabeled training data in the video surveillance scenario. In this paper, we propose a new semi-supervised learning method called SIAVC for industrial accident video classification. Specifically, we design a video augmentation module called the Super Augmentation Block (SAB). SAB adds Gaussian noise and randomly masks video frames according to historical loss on the unlabeled data for model optimization. Then, we propose a Video Cross-set Augmentation Module (VCAM) to generate diverse pseudo-label samples from the high-confidence unlabeled samples, which alleviates the mismatch of sampling experience and provides high-quality training data. Additionally, we construct a new industrial accident surveillance video dataset with frame-level annotation, namely ECA9, to evaluate our proposed method. Compared with the state-of-the-art semi-supervised learning based methods, SIAVC demonstrates outstanding video classification performance, achieving 88.76\% and 89.13\% accuracy on ECA9 and Fire Detection datasets, respectively. The source code and the constructed dataset ECA9 will be released in \url{https://github.com/AlchemyEmperor/SIAVC}.
FireMatch: A Semi-Supervised Video Fire Detection Network Based on Consistency and Distribution Alignment
Nov 09, 2023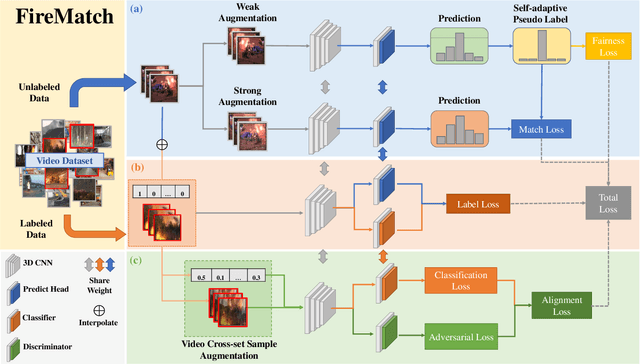
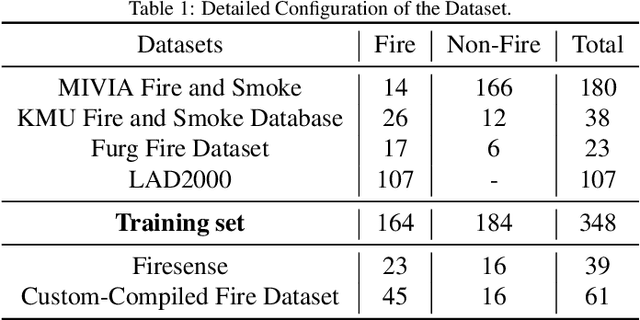
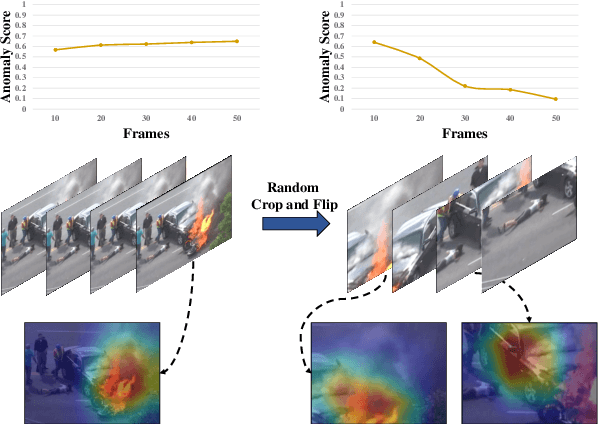
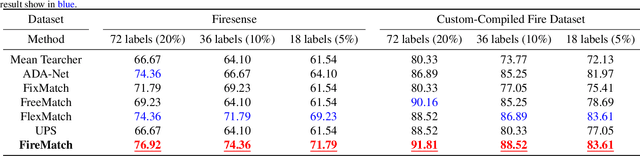
Deep learning techniques have greatly enhanced the performance of fire detection in videos. However, video-based fire detection models heavily rely on labeled data, and the process of data labeling is particularly costly and time-consuming, especially when dealing with videos. Considering the limited quantity of labeled video data, we propose a semi-supervised fire detection model called FireMatch, which is based on consistency regularization and adversarial distribution alignment. Specifically, we first combine consistency regularization with pseudo-label. For unlabeled data, we design video data augmentation to obtain corresponding weakly augmented and strongly augmented samples. The proposed model predicts weakly augmented samples and retains pseudo-label above a threshold, while training on strongly augmented samples to predict these pseudo-labels for learning more robust feature representations. Secondly, we generate video cross-set augmented samples by adversarial distribution alignment to expand the training data and alleviate the decline in classification performance caused by insufficient labeled data. Finally, we introduce a fairness loss to help the model produce diverse predictions for input samples, thereby addressing the issue of high confidence with the non-fire class in fire classification scenarios. The FireMatch achieved an accuracy of 76.92% and 91.81% on two real-world fire datasets, respectively. The experimental results demonstrate that the proposed method outperforms the current state-of-the-art semi-supervised classification methods.