 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape of Thought: Progressive Object Assembly via Visual Chain-of-Thought
Jan 28, 2026Multimodal models for text-to-image generation have achieved strong visual fidelity, yet they remain brittle under compositional structural constraints-notably generative numeracy, attribute binding, and part-level relations. To address these challenges, we propose Shape-of-Thought (SoT), a visual CoT framework that enables progressive shape assembly via coherent 2D projections without external engines at inference time. SoT trains a unified multimodal autoregressive model to generate interleaved textual plans and rendered intermediate states, helping the model capture shape-assembly logic without producing explicit geometric representations. To support this paradigm, we introduce SoT-26K, a large-scale dataset of grounded assembly traces derived from part-based CAD hierarchies, and T2S-CompBench, a benchmark for evaluating structural integrity and trace faithfulness. Fine-tuning on SoT-26K achieves 88.4% on component numeracy and 84.8% on structural topology, outperforming text-only baselines by around 20%. SoT establishes a new paradigm for transparent, process-supervised compositional generation. The code is available at https://anonymous.4open.science/r/16FE/. The SoT-26K dataset will be released upon acceptance.
FireMatch: A Semi-Supervised Video Fire Detection Network Based on Consistency and Distribution Alignment
Nov 09, 2023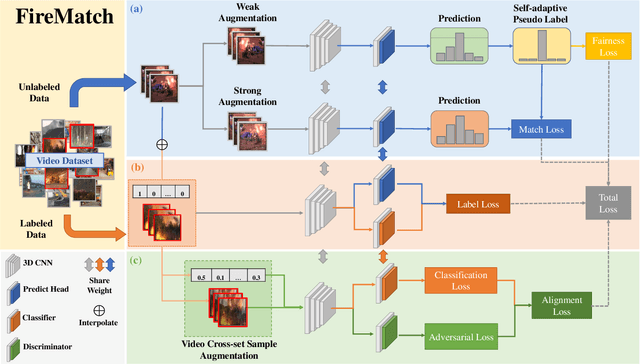
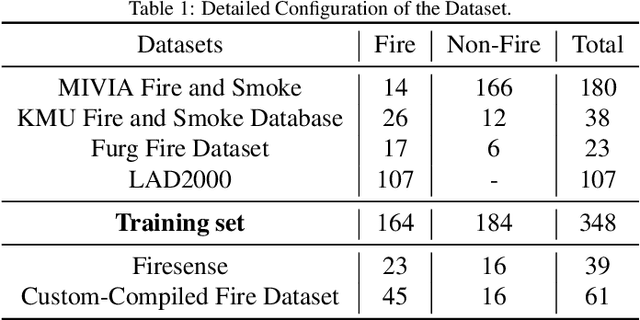
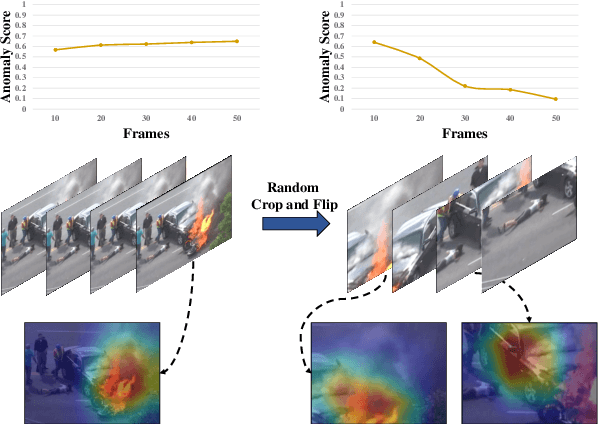
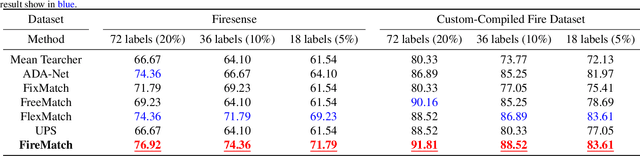
Deep learning techniques have greatly enhanced the performance of fire detection in videos. However, video-based fire detection models heavily rely on labeled data, and the process of data labeling is particularly costly and time-consuming, especially when dealing with videos. Considering the limited quantity of labeled video data, we propose a semi-supervised fire detection model called FireMatch, which is based on consistency regularization and adversarial distribution alignment. Specifically, we first combine consistency regularization with pseudo-label. For unlabeled data, we design video data augmentation to obtain corresponding weakly augmented and strongly augmented samples. The proposed model predicts weakly augmented samples and retains pseudo-label above a threshold, while training on strongly augmented samples to predict these pseudo-labels for learning more robust feature representations. Secondly, we generate video cross-set augmented samples by adversarial distribution alignment to expand the training data and alleviate the decline in classification performance caused by insufficient labeled data. Finally, we introduce a fairness loss to help the model produce diverse predictions for input samples, thereby addressing the issue of high confidence with the non-fire class in fire classification scenarios. The FireMatch achieved an accuracy of 76.92% and 91.81% on two real-world fire datasets, respectively. The experimental results demonstrate that the proposed method outperforms the current state-of-the-art semi-supervised classification methods.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022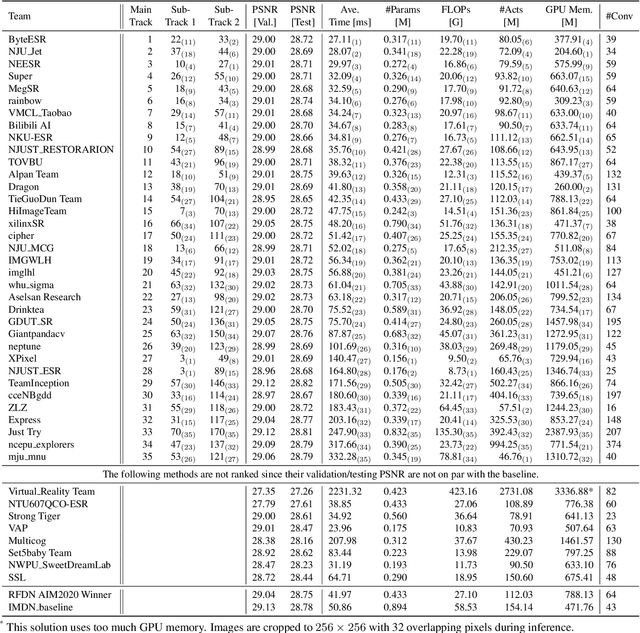
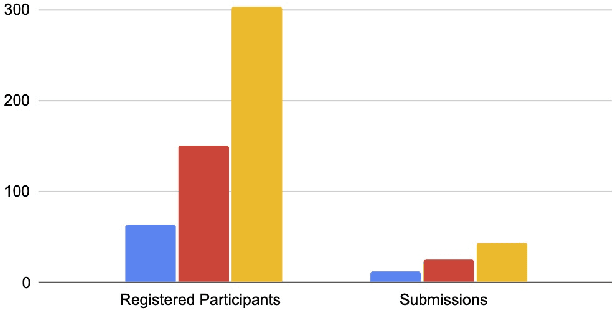
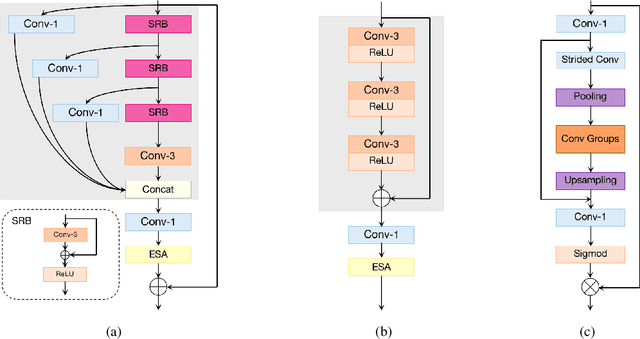
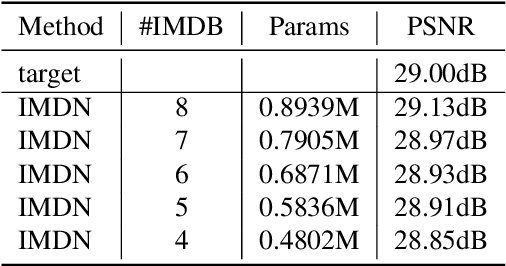
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Unsupervised Domain Adaptive Salient Object Detection Through Uncertainty-Aware Pseudo-Label Learning
Feb 26, 2022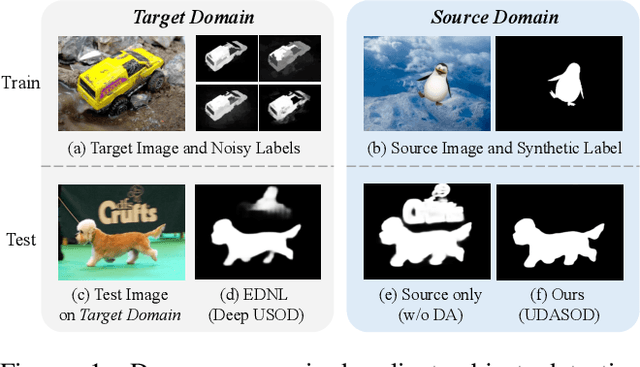
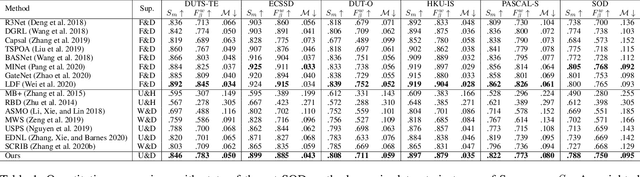


Recent advances in deep learning significantly boost the performance of salient object detection (SOD) at the expense of labeling larger-scale per-pixel annotations. To relieve the burden of labor-intensive labeling, deep unsupervised SOD methods have been proposed to exploit noisy labels generated by handcrafted saliency methods. However, it is still difficult to learn accurate saliency details from rough noisy labels. In this paper, we propose to learn saliency from synthetic but clean labels, which naturally has higher pixel-labeling quality without the effort of manual annotations. Specifically, we first construct a novel synthetic SOD dataset by a simple copy-paste strategy. Considering the large appearance differences between the synthetic and real-world scenarios, directly training with synthetic data will lead to performance degradation on real-world scenarios. To mitigate this problem, we propose a novel unsupervised domain adaptive SOD method to adapt between these two domains by uncertainty-aware self-training. Experimental results show that our proposed method outperforms the existing state-of-the-art deep unsupervised SOD methods on several benchmark datasets, and is even comparable to fully-supervised ones.
Scaling transition from momentum stochastic gradient descent to plain stochastic gradient descent
Jun 12, 2021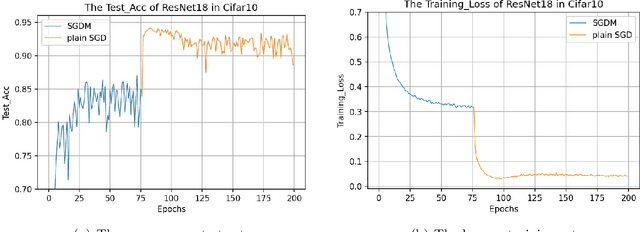


The plain stochastic gradient descent and momentum stochastic gradient descent have extremely wide applications in deep learning due to their simple settings and low computational complexity. The momentum stochastic gradient descent uses the accumulated gradient as the updated direction of the current parameters, which has a faster training speed. Because the direction of the plain stochastic gradient descent has not been corrected by the accumulated gradient. For the parameters that currently need to be updated, it is the optimal direction, and its update is more accurate. We combine the advantages of the momentum stochastic gradient descent with fast training speed and the plain stochastic gradient descent with high accuracy, and propose a scaling transition from momentum stochastic gradient descent to plain stochastic gradient descent(TSGD) method. At the same time, a learning rate that decreases linearly with the iterations is used instead of a constant learning rate. The TSGD algorithm has a larger step size in the early stage to speed up the training, and training with a smaller step size in the later stage can steadily converge. Our experimental results show that the TSGD algorithm has faster training speed, higher accuracy and better stability. Our implementation is available at: https://github.com/kunzeng/TSGD.
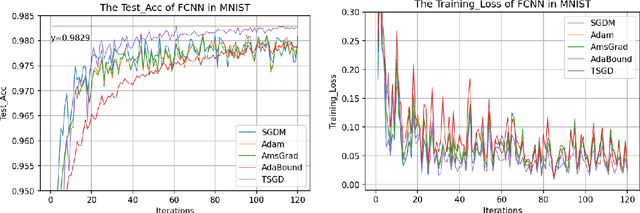
Decreasing scaling transition from adaptive gradient descent to stochastic gradient descent
Jun 12, 2021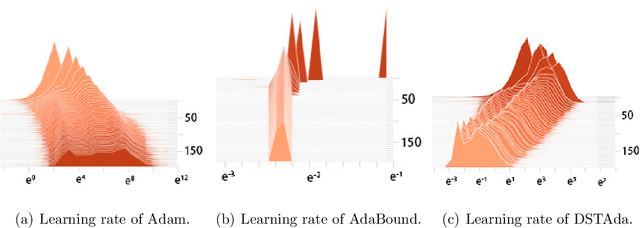

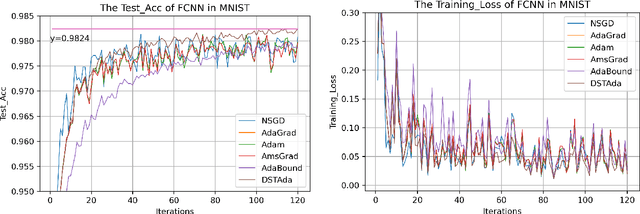

Currently, researchers have proposed the adaptive gradient descent algorithm and its variants, such as AdaGrad, RMSProp, Adam, AmsGrad, etc. Although these algorithms have a faster speed in the early stage, the generalization ability in the later stage of training is often not as good as the stochastic gradient descent. Recently, some researchers have combined the adaptive gradient descent and stochastic gradient descent to obtain the advantages of both and achieved good results. Based on this research, we propose a decreasing scaling transition from adaptive gradient descent to stochastic gradient descent method(DSTAda). For the training stage of the stochastic gradient descent, we use a learning rate that decreases linearly with the number of iterations instead of a constant learning rate. We achieve a smooth and stable transition from adaptive gradient descent to stochastic gradient descent through scaling. At the same time, we give a theoretical proof of the convergence of DSTAda under the framework of online learning. Our experimental results show that the DSTAda algorithm has a faster convergence speed, higher accuracy, and better stability and robustness. Our implementation is available at: https://github.com/kunzeng/DSTAdam.
Real-Time Quantized Image Super-Resolution on Mobile NPUs, Mobile AI 2021 Challenge: Report
May 17, 2021
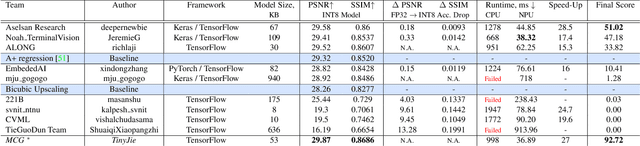
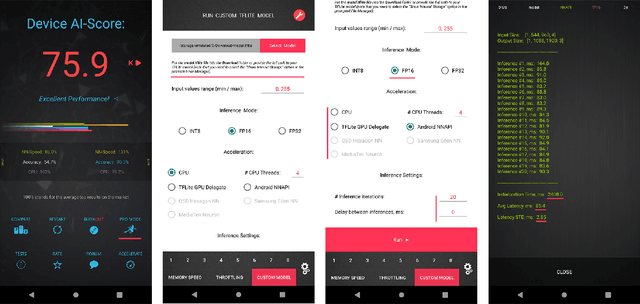
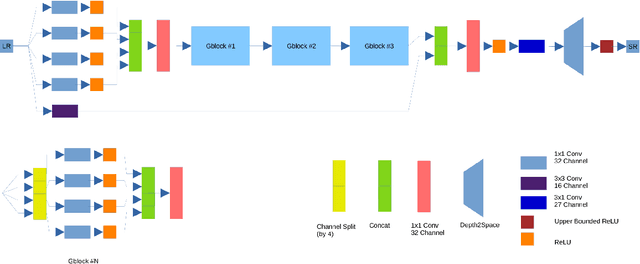
Image super-resolution is one of the most popular computer vision problems with many important applications to mobile devices. While many solutions have been proposed for this task, they are usually not optimized even for common smartphone AI hardware, not to mention more constrained smart TV platforms that are often supporting INT8 inference only. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image super-resolution solutions that can demonstrate a real-time performance on mobile or edge NPUs. For this, the participants were provided with the DIV2K dataset and trained quantized models to do an efficient 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated NPU capable of accelerating quantized neural networks. The proposed solutions are fully compatible with all major mobile AI accelerators and are capable of reconstructing Full HD images under 40-60 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
SparseNet: A Sparse DenseNet for Image Classification
Apr 15, 2018



Deep neural networks have made remarkable progresses on various computer vision tasks. Recent works have shown that depth, width and shortcut connections of networks are all vital to their performances. In this paper, we introduce a method to sparsify DenseNet which can reduce connections of a L-layer DenseNet from O(L^2) to O(L), and thus we can simultaneously increase depth, width and connections of neural networks in a more parameter-efficient and computation-efficient way. Moreover, an attention module is introduced to further boost our network's performance. We denote our network as SparseNet. We evaluate SparseNet on datasets of CIFAR(including CIFAR10 and CIFAR100) and SVHN. Experiments show that SparseNet can obtain improvements over the state-of-the-art on CIFAR10 and SVHN. Furthermore, while achieving comparable performances as DenseNet on these datasets, SparseNet is x2.6 smaller and x3.7 faster than the original DenseNet.