 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIAVC: Semi-Supervised Framework for Industrial Accident Video Classification
May 23, 2024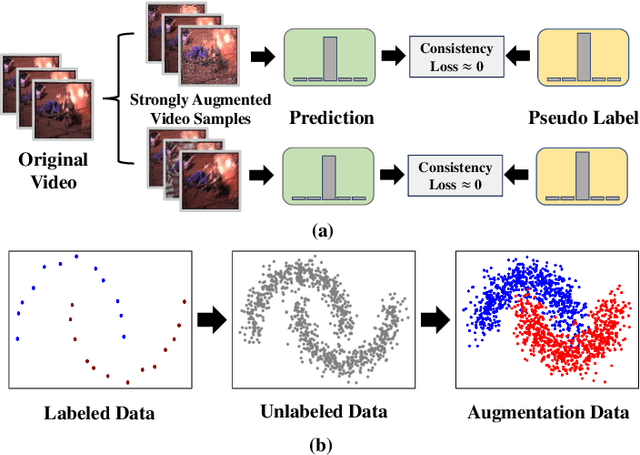
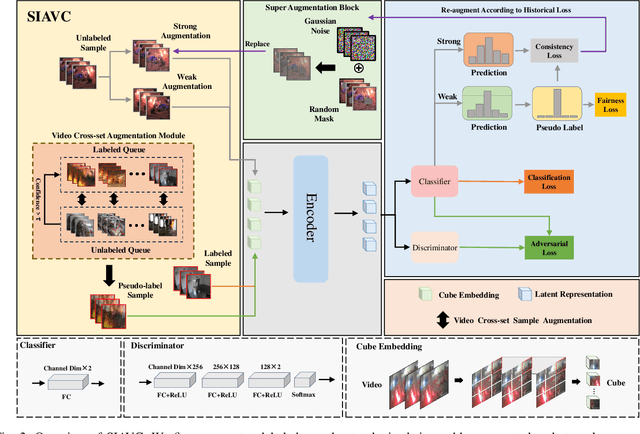
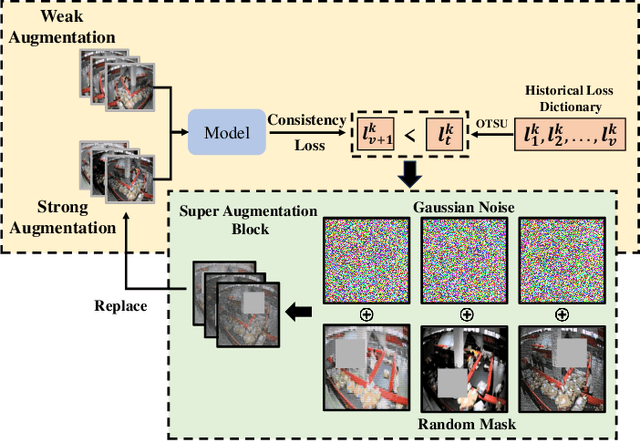
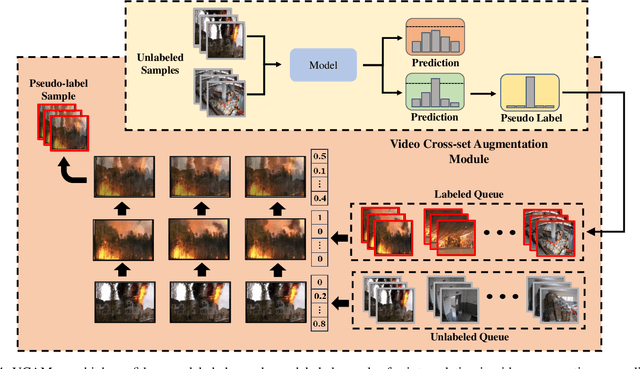
Semi-supervised learning suffers from the imbalance of labeled and unlabeled training data in the video surveillance scenario. In this paper, we propose a new semi-supervised learning method called SIAVC for industrial accident video classification. Specifically, we design a video augmentation module called the Super Augmentation Block (SAB). SAB adds Gaussian noise and randomly masks video frames according to historical loss on the unlabeled data for model optimization. Then, we propose a Video Cross-set Augmentation Module (VCAM) to generate diverse pseudo-label samples from the high-confidence unlabeled samples, which alleviates the mismatch of sampling experience and provides high-quality training data. Additionally, we construct a new industrial accident surveillance video dataset with frame-level annotation, namely ECA9, to evaluate our proposed method. Compared with the state-of-the-art semi-supervised learning based methods, SIAVC demonstrates outstanding video classification performance, achieving 88.76\% and 89.13\% accuracy on ECA9 and Fire Detection datasets, respectively. The source code and the constructed dataset ECA9 will be released in \url{https://github.com/AlchemyEmperor/SIAVC}.
FireMatch: A Semi-Supervised Video Fire Detection Network Based on Consistency and Distribution Alignment
Nov 09, 2023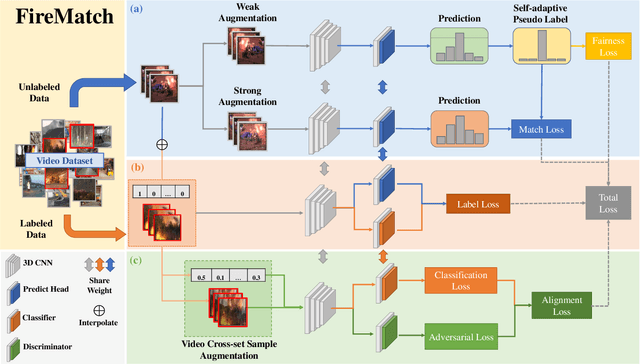
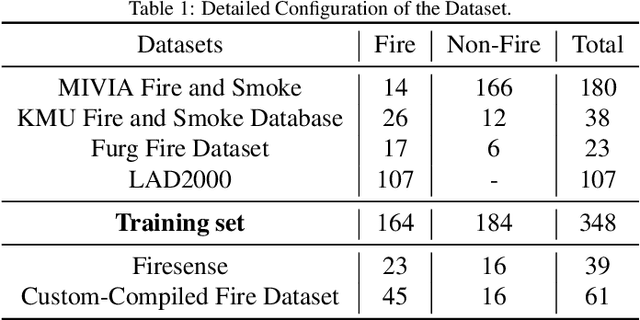
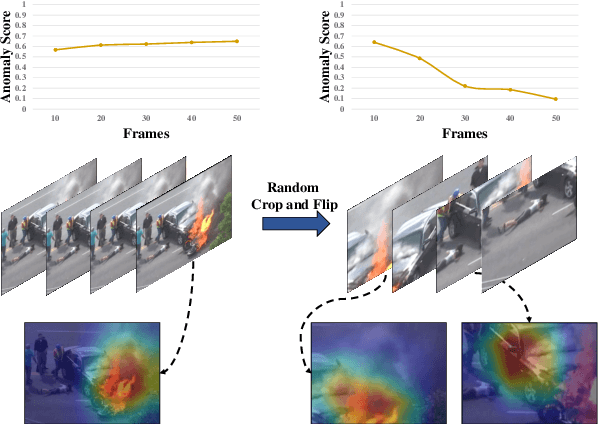
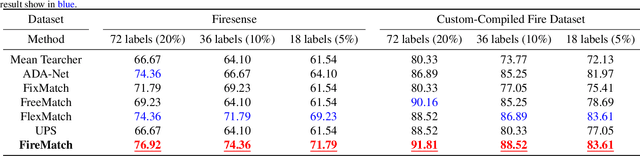
Deep learning techniques have greatly enhanced the performance of fire detection in videos. However, video-based fire detection models heavily rely on labeled data, and the process of data labeling is particularly costly and time-consuming, especially when dealing with videos. Considering the limited quantity of labeled video data, we propose a semi-supervised fire detection model called FireMatch, which is based on consistency regularization and adversarial distribution alignment. Specifically, we first combine consistency regularization with pseudo-label. For unlabeled data, we design video data augmentation to obtain corresponding weakly augmented and strongly augmented samples. The proposed model predicts weakly augmented samples and retains pseudo-label above a threshold, while training on strongly augmented samples to predict these pseudo-labels for learning more robust feature representations. Secondly, we generate video cross-set augmented samples by adversarial distribution alignment to expand the training data and alleviate the decline in classification performance caused by insufficient labeled data. Finally, we introduce a fairness loss to help the model produce diverse predictions for input samples, thereby addressing the issue of high confidence with the non-fire class in fire classification scenarios. The FireMatch achieved an accuracy of 76.92% and 91.81% on two real-world fire datasets, respectively. The experimental results demonstrate that the proposed method outperforms the current state-of-the-art semi-supervised classification methods.
Class-Specific Distribution Alignment for Semi-Supervised Medical Image Classification
Jul 29, 2023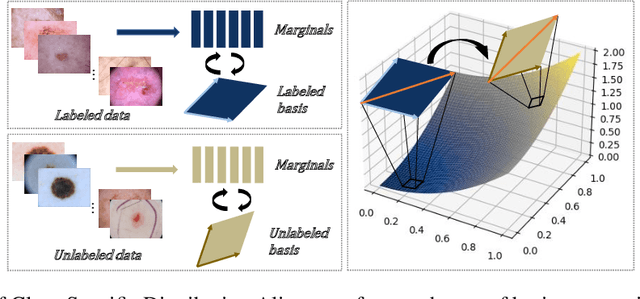

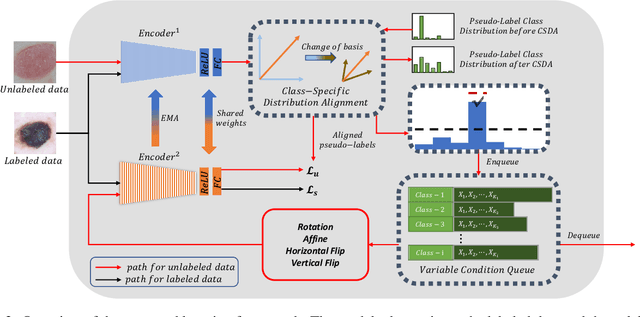
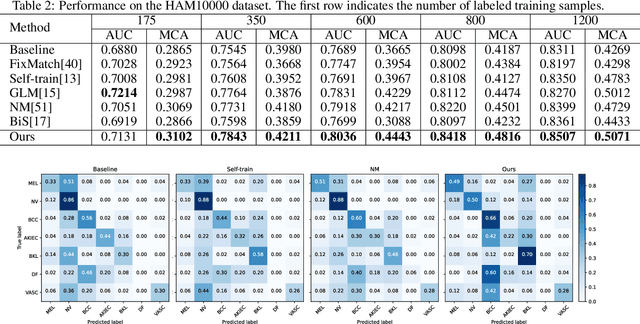
Despite the success of deep neural networks in medical image classification, the problem remains challenging as data annotation is time-consuming, and the class distribution is imbalanced due to the relative scarcity of diseases. To address this problem, we propose Class-Specific Distribution Alignment (CSDA), a semi-supervised learning framework based on self-training that is suitable to learn from highly imbalanced datasets. Specifically, we first provide a new perspective to distribution alignment by considering the process as a change of basis in the vector space spanned by marginal predictions, and then derive CSDA to capture class-dependent marginal predictions on both labeled and unlabeled data, in order to avoid the bias towards majority classes. Furthermore, we propose a Variable Condition Queue (VCQ) module to maintain a proportionately balanced number of unlabeled samples for each class. Experiments on three public datasets HAM10000, CheXpert and Kvasir show that our method provides competitive performance on semi-supervised skin disease, thoracic disease, and endoscopic image classification tasks.
Semi-Supervised Medical Image Segmentation with Co-Distribution Alignment
Jul 24, 2023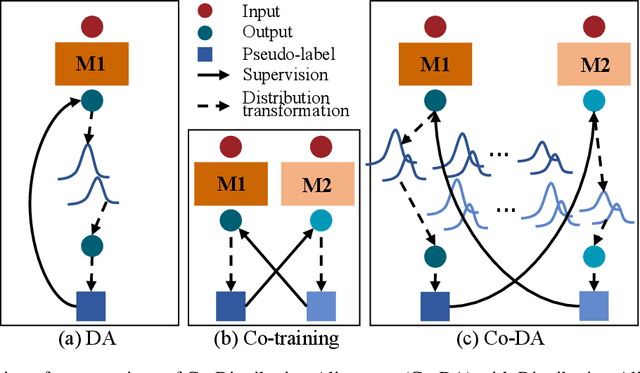
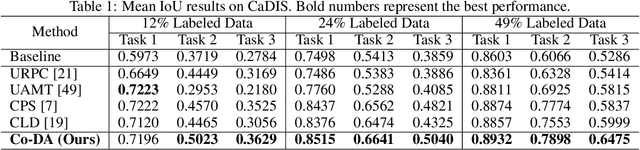
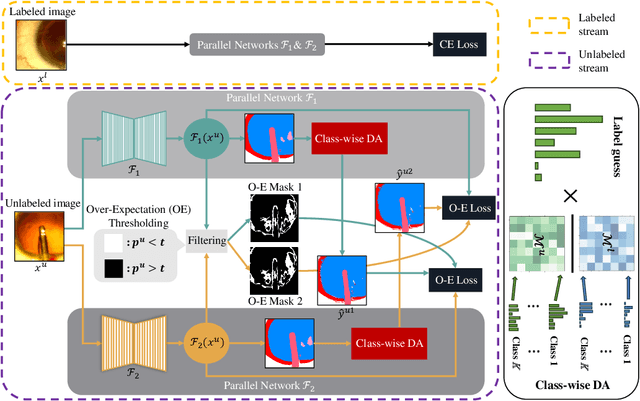

Medical image segmentation has made significant progress when a large amount of labeled data are available. However, annotating medical image segmentation datasets is expensive due to the requirement of professional skills. Additionally, classes are often unevenly distributed in medical images, which severely affects the classification performance on minority classes. To address these problems, this paper proposes Co-Distribution Alignment (Co-DA) for semi-supervised medical image segmentation. Specifically, Co-DA aligns marginal predictions on unlabeled data to marginal predictions on labeled data in a class-wise manner with two differently initialized models before using the pseudo-labels generated by one model to supervise the other. Besides, we design an over-expectation cross-entropy loss for filtering the unlabeled pixels to reduce noise in their pseudo-labels. Quantitative and qualitative experiments on three public datasets demonstrate that the proposed approach outperforms existing state-of-the-art semi-supervised medical image segmentation methods on both the 2D CaDIS dataset and the 3D LGE-MRI and ACDC datasets, achieving an mIoU of 0.8515 with only 24% labeled data on CaDIS, and a Dice score of 0.8824 and 0.8773 with only 20% data on LGE-MRI and ACDC, respectively.
dugMatting: Decomposed-Uncertainty-Guided Matting
Jun 02, 2023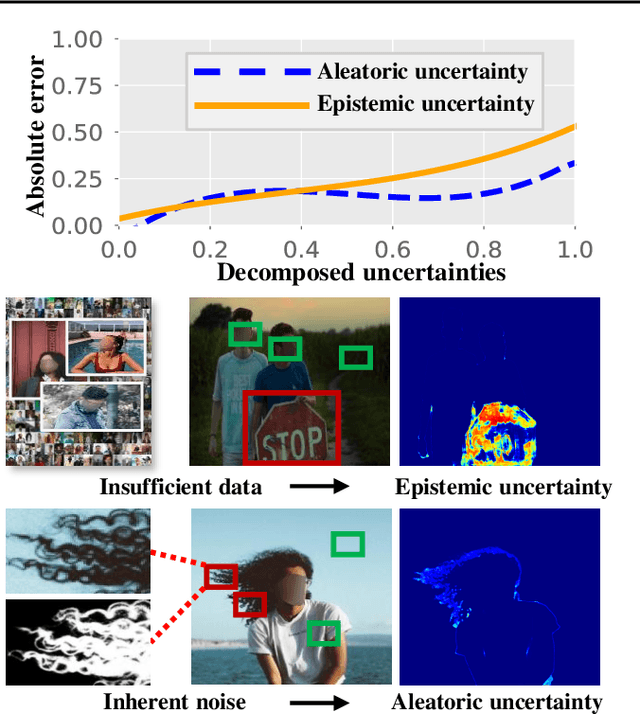
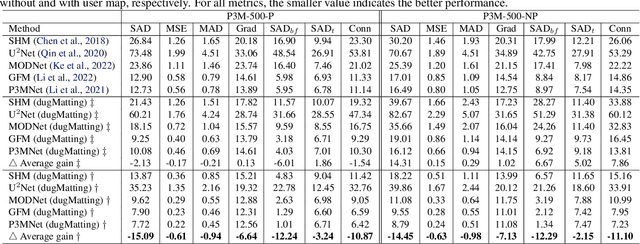
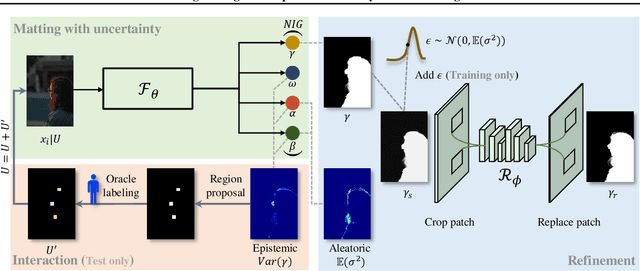
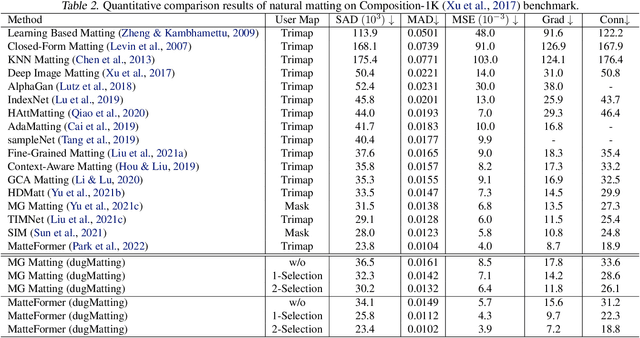
Cutting out an object and estimating its opacity mask, known as image matting, is a key task in image and video editing. Due to the highly ill-posed issue, additional inputs, typically user-defined trimaps or scribbles, are usually needed to reduce the uncertainty. Although effective, it is either time consuming or only suitable for experienced users who know where to place the strokes. In this work, we propose a decomposed-uncertainty-guided matting (dugMatting) algorithm, which explores the explicitly decomposed uncertainties to efficiently and effectively improve the results. Basing on the characteristic of these uncertainties, the epistemic uncertainty is reduced in the process of guiding interaction (which introduces prior knowledge), while the aleatoric uncertainty is reduced in modeling data distribution (which introduces statistics for both data and possible noise). The proposed matting framework relieves the requirement for users to determine the interaction areas by using simple and efficient labeling. Extensively quantitative and qualitative results validate that the proposed method significantly improves the original matting algorithms in terms of both efficiency and efficacy.
Spatio-Temporal Context Modeling for Road Obstacle Detection
Jan 19, 2023Road obstacle detection is an important problem for vehicle driving safety. In this paper, we aim to obtain robust road obstacle detection based on spatio-temporal context modeling. Firstly, a data-driven spatial context model of the driving scene is constructed with the layouts of the training data. Then, obstacles in the input image are detected via the state-of-the-art object detection algorithms, and the results are combined with the generated scene layout. In addition, to further improve the performance and robustness, temporal information in the image sequence is taken into consideration, and the optical flow is obtained in the vicinity of the detected objects to track the obstacles across neighboring frames. Qualitative and quantitative experiments were conducted on the Small Obstacle Detection (SOD) dataset and the Lost and Found dataset. The results indicate that our method with spatio-temporal context modeling is superior to existing methods for road obstacle detection.
Deep Dual Support Vector Data Description for Anomaly Detection on Attributed Networks
Sep 01, 2021
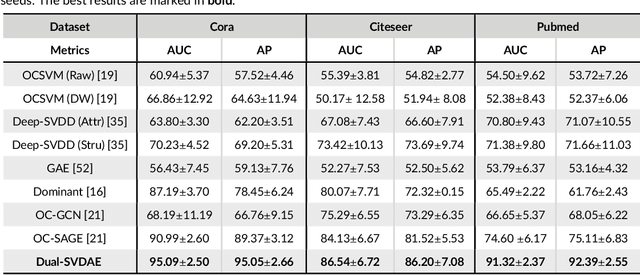
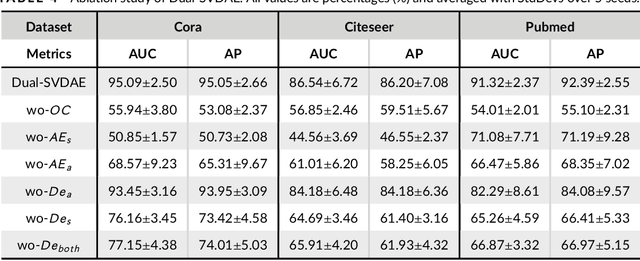
Networks are ubiquitous in the real world such as social networks and communication networks, and anomaly detection on networks aims at finding nodes whose structural or attributed patterns deviate significantly from the majority of reference nodes. However, most of the traditional anomaly detection methods neglect the relation structure information among data points and therefore cannot effectively generalize to the graph structure data. In this paper, we propose an end-to-end model of Deep Dual Support Vector Data description based Autoencoder (Dual-SVDAE) for anomaly detection on attributed networks, which considers both the structure and attribute for attributed networks. Specifically, Dual-SVDAE consists of a structure autoencoder and an attribute autoencoder to learn the latent representation of the node in the structure space and attribute space respectively. Then, a dual-hypersphere learning mechanism is imposed on them to learn two hyperspheres of normal nodes from the structure and attribute perspectives respectively. Moreover, to achieve joint learning between the structure and attribute of the network, we fuse the structure embedding and attribute embedding as the final input of the feature decoder to generate the node attribute. Finally, abnormal nodes can be detected by measuring the distance of nodes to the learned center of each hypersphere in the latent structure space and attribute space respectively. Extensive experiments on the real-world attributed networks show that Dual-SVDAE consistently outperforms the state-of-the-arts, which demonstrates the effectiveness of the proposed method.
AnomalyDAE: Dual autoencoder for anomaly detection on attributed networks
Feb 12, 2020
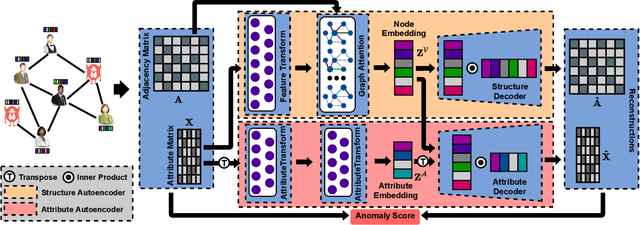
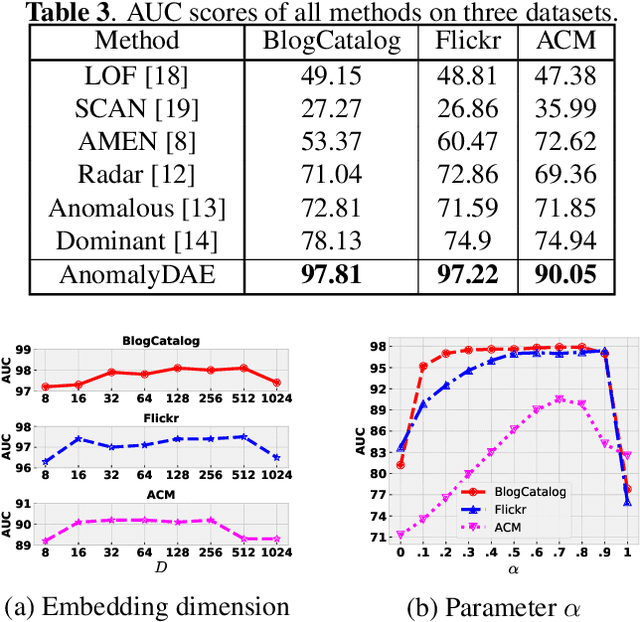
Anomaly detection on attributed networks aims at finding nodes whose patterns deviate significantly from the majority of reference nodes, which is pervasive in many applications such as network intrusion detection and social spammer detection. However, most existing methods neglect the complex cross-modality interactions between network structure and node attribute. In this paper, we propose a deep joint representation learning framework for anomaly detection through a dual autoencoder (AnomalyDAE), which captures the complex interactions between network structure and node attribute for high-quality embeddings. Specifically, AnomalyDAE consists of a structure autoencoder and an attribute autoencoder to learn both node embedding and attribute embedding jointly in latent space. Moreover, attention mechanism is employed in structure encoder to learn the importance between a node and its neighbors for an effective capturing of structure pattern, which is important to anomaly detection. Besides, by taking both the node embedding and attribute embedding as inputs of attribute decoder, the cross-modality interactions between network structure and node attribute are learned during the reconstruction of node attribute. Finally, anomalies can be detected by measuring the reconstruction errors of nodes from both the structure and attribute perspectives. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed method.
Robust Classification with Sparse Representation Fusion on Diverse Data Subsets
Jun 10, 2019
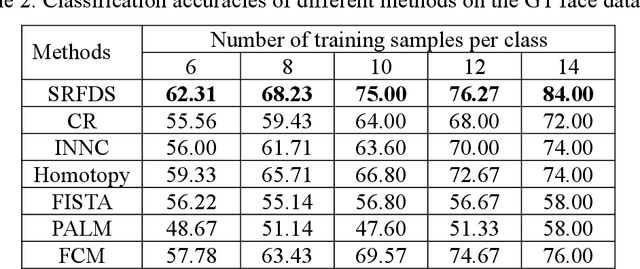
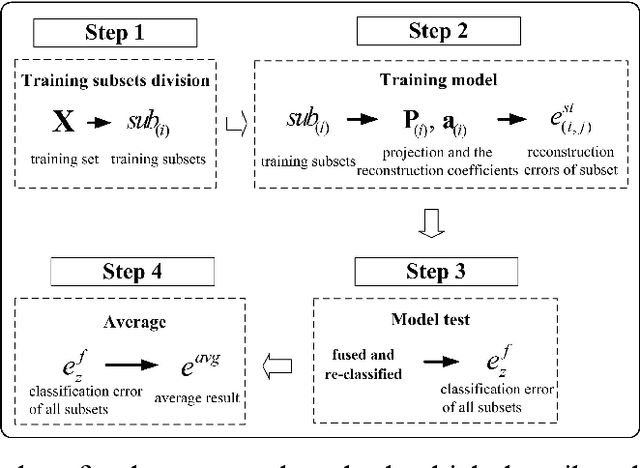

Sparse Representation (SR) techniques encode the test samples into a sparse linear combination of all training samples and then classify the test samples into the class with the minimum residual. The classification of SR techniques depends on the representation capability on the test samples. However, most of these models view the representation problem of the test samples as a deterministic problem, ignoring the uncertainty of the representation. The uncertainty is caused by two factors, random noise in the samples and the intrinsic randomness of the sample set, which means that if we capture a group of samples, the obtained set of samples will be different in different conditions. In this paper, we propose a novel method based upon Collaborative Representation that is a special instance of SR and has closed-form solution. It performs Sparse Representation Fusion based on the Diverse Subset of training samples (SRFDS), which reduces the impact of randomness of the sample set and enhances the robustness of classification results. The proposed method is suitable for multiple types of data and has no requirement on the pattern type of the tasks. In addition, SRFDS not only preserves a closed-form solution but also greatly improves the classification performance. Promising results on various datasets serve as the evidence of better performance of SRFDS than other SR-based methods. The Matlab code of SRFDS will be accessible at http://www.yongxu.org/lunwen.html.
Joint Learning of Self-Representation and Indicator for Multi-View Image Clustering
May 11, 2019
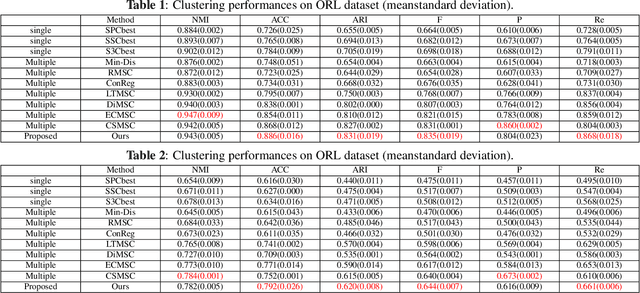
Multi-view subspace clustering aims to divide a set of multisource data into several groups according to their underlying subspace structure. Although the spectral clustering based methods achieve promotion in multi-view clustering, their utility is limited by the separate learning manner in which affinity matrix construction and cluster indicator estimation are isolated. In this paper, we propose to jointly learn the self-representation, continue and discrete cluster indicators in an unified model. Our model can explore the subspace structure of each view and fusion them to facilitate clustering simultaneously. Experimental results on two benchmark datasets demonstrate that our method outperforms other existing competitive multi-view clustering methods.