 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGL: Advancing Continual GUI Learning via Reinforcement Fine-Tuning
Mar 03, 2026Graphical User Interface (GUI) Agents, benefiting from recent advances in multimodal large language models (MLLM), have achieved significant development. However, due to the frequent updates of GUI applications, adapting to new tasks without forgetting old tasks in GUI continual learning remains an open problem. In this work, we reveal that while Supervised Fine-Tuning (SFT) facilitates fast adaptation, it often triggers knowledge overwriting, whereas Reinforcement Learning (RL) demonstrates an inherent resilience that shields prior interaction logic from erasure. Based on this insight, we propose a \textbf{C}ontinual \textbf{G}UI \textbf{L}earning (CGL) framework that dynamically balances adaptation efficiency and skill retention by enhancing the synergy between SFT and RL. Specifically, we introduce an SFT proportion adjustment mechanism guided by policy entropy to dynamically control the weight allocation between the SFT and RL training phases. To resolve explicit gradient interference, we further develop a specialized gradient surgery strategy. By projecting exploratory SFT gradients onto GRPO-based anchor gradients, our method explicitly clips the components of SFT gradients that conflict with GRPO. On top of that, we establish an AndroidControl-CL benchmark, which divides GUI applications into distinct task groups to effectively simulate and evaluate the performance of continual GUI learning. Experimental results demonstrate the effectiveness of our proposed CGL framework across continual learning scenarios. The benchmark, code, and model will be made publicly available.
Text to Image for Multi-Label Image Recognition with Joint Prompt-Adapter Learning
Jun 12, 2025



Benefited from image-text contrastive learning, pre-trained vision-language models, e.g., CLIP, allow to direct leverage texts as images (TaI) for parameter-efficient fine-tuning (PEFT). While CLIP is capable of making image features to be similar to the corresponding text features, the modality gap remains a nontrivial issue and limits image recognition performance of TaI. Using multi-label image recognition (MLR) as an example, we present a novel method, called T2I-PAL to tackle the modality gap issue when using only text captions for PEFT. The core design of T2I-PAL is to leverage pre-trained text-to-image generation models to generate photo-realistic and diverse images from text captions, thereby reducing the modality gap. To further enhance MLR, T2I-PAL incorporates a class-wise heatmap and learnable prototypes. This aggregates local similarities, making the representation of local visual features more robust and informative for multi-label recognition. For better PEFT, we further combine both prompt tuning and adapter learning to enhance classification performance. T2I-PAL offers significant advantages: it eliminates the need for fully semantically annotated training images, thereby reducing the manual annotation workload, and it preserves the intrinsic mode of the CLIP model, allowing for seamless integration with any existing CLIP framework. Extensive experiments on multiple benchmarks, including MS-COCO, VOC2007, and NUS-WIDE, show that our T2I-PAL can boost recognition performance by 3.47% in average above the top-ranked state-of-the-art methods.
VR-RAG: Open-vocabulary Species Recognition with RAG-Assisted Large Multi-Modal Models
May 08, 2025Open-vocabulary recognition remains a challenging problem in computer vision, as it requires identifying objects from an unbounded set of categories. This is particularly relevant in nature, where new species are discovered every year. In this work, we focus on open-vocabulary bird species recognition, where the goal is to classify species based on their descriptions without being constrained to a predefined set of taxonomic categories. Traditional benchmarks like CUB-200-2011 and Birdsnap have been evaluated in a closed-vocabulary paradigm, limiting their applicability to real-world scenarios where novel species continually emerge. We show that the performance of current systems when evaluated under settings closely aligned with open-vocabulary drops by a huge margin. To address this gap, we propose a scalable framework integrating structured textual knowledge from Wikipedia articles of 11,202 bird species distilled via GPT-4o into concise, discriminative summaries. We propose Visual Re-ranking Retrieval-Augmented Generation(VR-RAG), a novel, retrieval-augmented generation framework that uses visual similarities to rerank the top m candidates retrieved by a set of multimodal vision language encoders. This allows for the recognition of unseen taxa. Extensive experiments across five established classification benchmarks show that our approach is highly effective. By integrating VR-RAG, we improve the average performance of state-of-the-art Large Multi-Modal Model QWEN2.5-VL by 15.4% across five benchmarks. Our approach outperforms conventional VLM-based approaches, which struggle with unseen species. By bridging the gap between encyclopedic knowledge and visual recognition, our work advances open-vocabulary recognition, offering a flexible, scalable solution for biodiversity monitoring and ecological research.
Empowering Large Language Models with 3D Situation Awareness
Mar 29, 2025Driven by the great success of Large Language Models (LLMs) in the 2D image domain, their applications in 3D scene understanding has emerged as a new trend. A key difference between 3D and 2D is that the situation of an egocentric observer in 3D scenes can change, resulting in different descriptions (e.g., ''left" or ''right"). However, current LLM-based methods overlook the egocentric perspective and simply use datasets from a global viewpoint. To address this issue, we propose a novel approach to automatically generate a situation-aware dataset by leveraging the scanning trajectory during data collection and utilizing Vision-Language Models (VLMs) to produce high-quality captions and question-answer pairs. Furthermore, we introduce a situation grounding module to explicitly predict the position and orientation of observer's viewpoint, thereby enabling LLMs to ground situation description in 3D scenes. We evaluate our approach on several benchmarks, demonstrating that our method effectively enhances the 3D situational awareness of LLMs while significantly expanding existing datasets and reducing manual effort.
WikiAutoGen: Towards Multi-Modal Wikipedia-Style Article Generation
Mar 24, 2025Knowledge discovery and collection are intelligence-intensive tasks that traditionally require significant human effort to ensure high-quality outputs. Recent research has explored multi-agent frameworks for automating Wikipedia-style article generation by retrieving and synthesizing information from the internet. However, these methods primarily focus on text-only generation, overlooking the importance of multimodal content in enhancing informativeness and engagement. In this work, we introduce WikiAutoGen, a novel system for automated multimodal Wikipedia-style article generation. Unlike prior approaches, WikiAutoGen retrieves and integrates relevant images alongside text, enriching both the depth and visual appeal of generated content. To further improve factual accuracy and comprehensiveness, we propose a multi-perspective self-reflection mechanism, which critically assesses retrieved content from diverse viewpoints to enhance reliability, breadth, and coherence, etc. Additionally, we introduce WikiSeek, a benchmark comprising Wikipedia articles with topics paired with both textual and image-based representations, designed to evaluate multimodal knowledge generation on more challenging topics. Experimental results show that WikiAutoGen outperforms previous methods by 8%-29% on our WikiSeek benchmark, producing more accurate, coherent, and visually enriched Wikipedia-style articles. We show some of our generated examples in https://wikiautogen.github.io/ .
PiSA: A Self-Augmented Data Engine and Training Strategy for 3D Understanding with Large Models
Mar 13, 2025



3D Multimodal Large Language Models (MLLMs) have recently made substantial advancements. However, their potential remains untapped, primarily due to the limited quantity and suboptimal quality of 3D datasets. Current approaches attempt to transfer knowledge from 2D MLLMs to expand 3D instruction data, but still face modality and domain gaps. To this end, we introduce PiSA-Engine (Point-Self-Augmented-Engine), a new framework for generating instruction point-language datasets enriched with 3D spatial semantics. We observe that existing 3D MLLMs offer a comprehensive understanding of point clouds for annotation, while 2D MLLMs excel at cross-validation by providing complementary information. By integrating holistic 2D and 3D insights from off-the-shelf MLLMs, PiSA-Engine enables a continuous cycle of high-quality data generation. We select PointLLM as the baseline and adopt this co-evolution training framework to develop an enhanced 3D MLLM, termed PointLLM-PiSA. Additionally, we identify limitations in previous 3D benchmarks, which often feature coarse language captions and insufficient category diversity, resulting in inaccurate evaluations. To address this gap, we further introduce PiSA-Bench, a comprehensive 3D benchmark covering six key aspects with detailed and diverse labels. Experimental results demonstrate PointLLM-PiSA's state-of-the-art performance in zero-shot 3D object captioning and generative classification on our PiSA-Bench, achieving significant improvements of 46.45% (+8.33%) and 63.75% (+16.25%), respectively. We will release the code, datasets, and benchmark.
MMRC: A Large-Scale Benchmark for Understanding Multimodal Large Language Model in Real-World Conversation
Feb 17, 2025Recent multimodal large language models (MLLMs) have demonstrated significant potential in open-ended conversation, generating more accurate and personalized responses. However, their abilities to memorize, recall, and reason in sustained interactions within real-world scenarios remain underexplored. This paper introduces MMRC, a Multi-Modal Real-world Conversation benchmark for evaluating six core open-ended abilities of MLLMs: information extraction, multi-turn reasoning, information update, image management, memory recall, and answer refusal. With data collected from real-world scenarios, MMRC comprises 5,120 conversations and 28,720 corresponding manually labeled questions, posing a significant challenge to existing MLLMs. Evaluations on 20 MLLMs in MMRC indicate an accuracy drop during open-ended interactions. We identify four common failure patterns: long-term memory degradation, inadequacies in updating factual knowledge, accumulated assumption of error propagation, and reluctance to say no. To mitigate these issues, we propose a simple yet effective NOTE-TAKING strategy, which can record key information from the conversation and remind the model during its responses, enhancing conversational capabilities. Experiments across six MLLMs demonstrate significant performance improvements.
Unprejudiced Training Auxiliary Tasks Makes Primary Better: A Multi-Task Learning Perspective
Dec 27, 2024Human beings can leverage knowledge from relative tasks to improve learning on a primary task. Similarly, multi-task learning methods suggest using auxiliary tasks to enhance a neural network's performance on a specific primary task. However, previous methods often select auxiliary tasks carefully but treat them as secondary during training. The weights assigned to auxiliary losses are typically smaller than the primary loss weight, leading to insufficient training on auxiliary tasks and ultimately failing to support the main task effectively. To address this issue, we propose an uncertainty-based impartial learning method that ensures balanced training across all tasks. Additionally, we consider both gradients and uncertainty information during backpropagation to further improve performance on the primary task. Extensive experiments show that our method achieves performance comparable to or better than state-of-the-art approaches. Moreover, our weighting strategy is effective and robust in enhancing the performance of the primary task regardless the noise auxiliary tasks' pseudo labels.
Diffusion-Enhanced Test-time Adaptation with Text and Image Augmentation
Dec 12, 2024Existing test-time prompt tuning (TPT) methods focus on single-modality data, primarily enhancing images and using confidence ratings to filter out inaccurate images. However, while image generation models can produce visually diverse images, single-modality data enhancement techniques still fail to capture the comprehensive knowledge provided by different modalities. Additionally, we note that the performance of TPT-based methods drops significantly when the number of augmented images is limited, which is not unusual given the computational expense of generative augmentation. To address these issues, we introduce IT3A, a novel test-time adaptation method that utilizes a pre-trained generative model for multi-modal augmentation of each test sample from unknown new domains. By combining augmented data from pre-trained vision and language models, we enhance the ability of the model to adapt to unknown new test data. Additionally, to ensure that key semantics are accurately retained when generating various visual and text enhancements, we employ cosine similarity filtering between the logits of the enhanced images and text with the original test data. This process allows us to filter out some spurious augmentation and inadequate combinations. To leverage the diverse enhancements provided by the generation model across different modals, we have replaced prompt tuning with an adapter for greater flexibility in utilizing text templates. Our experiments on the test datasets with distribution shifts and domain gaps show that in a zero-shot setting, IT3A outperforms state-of-the-art test-time prompt tuning methods with a 5.50% increase in accuracy.
* Accepted by International Journal of Computer Vision
Class Balance Matters to Active Class-Incremental Learning
Dec 09, 2024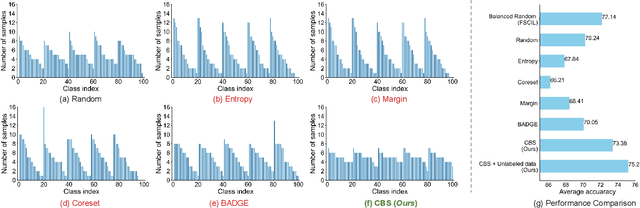
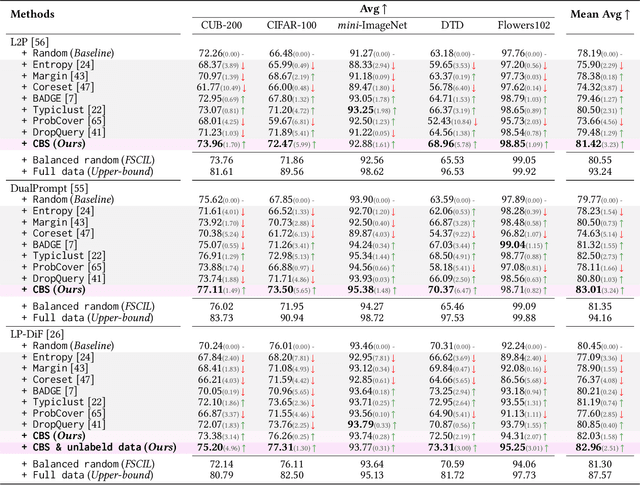

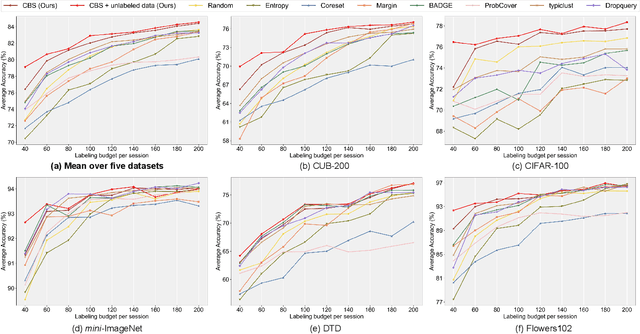
Few-Shot Class-Incremental Learning has shown remarkable efficacy in efficient learning new concepts with limited annotations. Nevertheless, the heuristic few-shot annotations may not always cover the most informative samples, which largely restricts the capability of incremental learner. We aim to start from a pool of large-scale unlabeled data and then annotate the most informative samples for incremental learning. Based on this premise, this paper introduces the Active Class-Incremental Learning (ACIL). The objective of ACIL is to select the most informative samples from the unlabeled pool to effectively train an incremental learner, aiming to maximize the performance of the resulting model. Note that vanilla active learning algorithms suffer from class-imbalanced distribution among annotated samples, which restricts the ability of incremental learning. To achieve both class balance and informativeness in chosen samples, we propose Class-Balanced Selection (CBS) strategy. Specifically, we first cluster the features of all unlabeled images into multiple groups. Then for each cluster, we employ greedy selection strategy to ensure that the Gaussian distribution of the sampled features closely matches the Gaussian distribution of all unlabeled features within the cluster. Our CBS can be plugged and played into those CIL methods which are based on pretrained models with prompts tunning technique. Extensive experiments under ACIL protocol across five diverse datasets demonstrate that CBS outperforms both random selection and other SOTA active learning approaches. Code is publicly available at https://github.com/1170300714/CBS.