 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSmoothLoRA: Toward Smoother and Faster Convergence in Federated Low-Rank Adaptation
May 28, 2026Federated fine-tuning of foundation models with Low-Rank Adaptation (LoRA) provides an efficient solution for reducing communication and computation costs while preserving data locality. However, the direct combination of FedAvg and LoRA suffers from three key issues: limited update space, which restricts the model's effective learning capacity; inter-round state mismatch, which disrupts cross-round local optimization continuity; and a client-agnostic starting state, which slows local convergence on clients. Although recent methods mitigate the limited update space issue by merging LoRA updates into the backbone across communication rounds, inter-round state mismatch and the client-agnostic starting state remain insufficiently addressed. To address these issues, we propose FedSmoothLoRA, a federated LoRA tuning framework that preserves the enlarged update space, improves cross-round local optimization continuity, and provides a client-aware starting state for local training. At each communication round, FedSmoothLoRA constructs the local LoRA initialization using two matrices: a Round-Matching matrix that preserves cross-round local state continuity, and a Gradient-Aligned matrix that provides client-specific optimization guidance from gradient signals estimated on local data. Together, these designs enable smoother and faster convergence. Extensive experiments on image classification and natural language generation tasks demonstrate that FedSmoothLoRA consistently outperforms existing federated LoRA tuning methods. Code: https://github.com/wangzehao0704/FedSmoothLoRA
MIRAGE: Assessing Hallucination in Multimodal Reasoning Chains of MLLM
May 30, 2025Multimodal hallucination in multimodal large language models (MLLMs) restricts the correctness of MLLMs. However, multimodal hallucinations are multi-sourced and arise from diverse causes. Existing benchmarks fail to adequately distinguish between perception-induced hallucinations and reasoning-induced hallucinations. This failure constitutes a significant issue and hinders the diagnosis of multimodal reasoning failures within MLLMs. To address this, we propose the {\dataset} benchmark, which isolates reasoning hallucinations by constructing questions where input images are correctly perceived by MLLMs yet reasoning errors persist. {\dataset} introduces multi-granular evaluation metrics: accuracy, factuality, and LLMs hallucination score for hallucination quantification. Our analysis reveals that (1) the model scale, data scale, and training stages significantly affect the degree of logical, fabrication, and factual hallucinations; (2) current MLLMs show no effective improvement on spatial hallucinations caused by misinterpreted spatial relationships, indicating their limited visual reasoning capabilities; and (3) question types correlate with distinct hallucination patterns, highlighting targeted challenges and potential mitigation strategies. To address these challenges, we propose {\method}, a method that combines curriculum reinforcement fine-tuning to encourage models to generate logic-consistent reasoning chains by stepwise reducing learning difficulty, and collaborative hint inference to reduce reasoning complexity. {\method} establishes a baseline on {\dataset}, and reduces the logical hallucinations in original base models.
Segmenting Objectiveness and Task-awareness Unknown Region for Autonomous Driving
Apr 27, 2025



With the emergence of transformer-based architectures and large language models (LLMs), the accuracy of road scene perception has substantially advanced. Nonetheless, current road scene segmentation approaches are predominantly trained on closed-set data, resulting in insufficient detection capabilities for out-of-distribution (OOD) objects. To overcome this limitation, road anomaly detection methods have been proposed. However, existing methods primarily depend on image inpainting and OOD distribution detection techniques, facing two critical issues: (1) inadequate consideration of the objectiveness attributes of anomalous regions, causing incomplete segmentation when anomalous objects share similarities with known classes, and (2) insufficient attention to environmental constraints, leading to the detection of anomalies irrelevant to autonomous driving tasks. In this paper, we propose a novel framework termed Segmenting Objectiveness and Task-Awareness (SOTA) for autonomous driving scenes. Specifically, SOTA enhances the segmentation of objectiveness through a Semantic Fusion Block (SFB) and filters anomalies irrelevant to road navigation tasks using a Scene-understanding Guided Prompt-Context Adaptor (SG-PCA). Extensive empirical evaluations on multiple benchmark datasets, including Fishyscapes Lost and Found, Segment-Me-If-You-Can, and RoadAnomaly, demonstrate that the proposed SOTA consistently improves OOD detection performance across diverse detectors, achieving robust and accurate segmentation outcomes.
MetricDepth: Enhancing Monocular Depth Estimation with Deep Metric Learning
Dec 29, 2024



Deep metric learning aims to learn features relying on the consistency or divergence of class labels. However, in monocular depth estimation, the absence of a natural definition of class poses challenges in the leveraging of deep metric learning. Addressing this gap, this paper introduces MetricDepth, a novel method that integrates deep metric learning to enhance the performance of monocular depth estimation. To overcome the inapplicability of the class-based sample identification in previous deep metric learning methods to monocular depth estimation task, we design the differential-based sample identification. This innovative approach identifies feature samples as different sample types by their depth differentials relative to anchor, laying a foundation for feature regularizing in monocular depth estimation models. Building upon this advancement, we then address another critical problem caused by the vast range and the continuity of depth annotations in monocular depth estimation. The extensive and continuous annotations lead to the diverse differentials of negative samples to anchor feature, representing the varied impact of negative samples during feature regularizing. Recognizing the inadequacy of the uniform strategy in previous deep metric learning methods for handling negative samples in monocular depth estimation task, we propose the multi-range strategy. Through further distinction on negative samples according to depth differential ranges and implementation of diverse regularizing, our multi-range strategy facilitates differentiated regularization interactions between anchor feature and its negative samples. Experiments across various datasets and model types demonstrate the effectiveness and versatility of MetricDepth,confirming its potential for performance enhancement in monocular depth estimation task.
Multi-Modality Driven LoRA for Adverse Condition Depth Estimation
Dec 28, 2024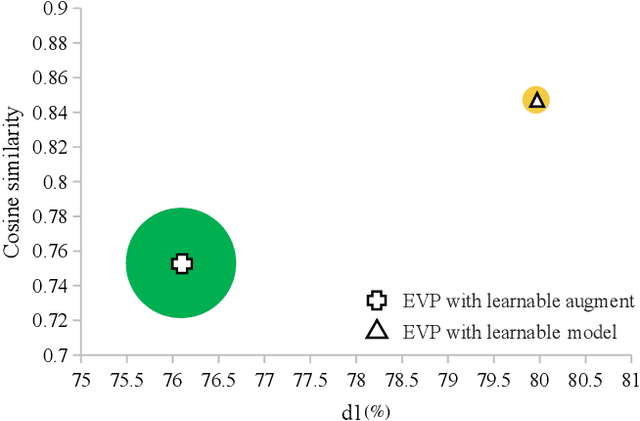
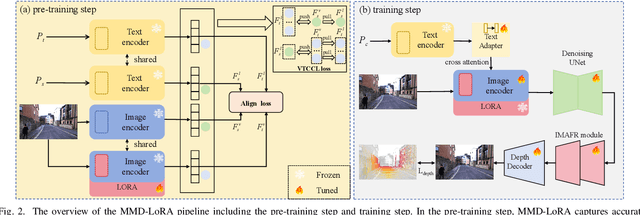
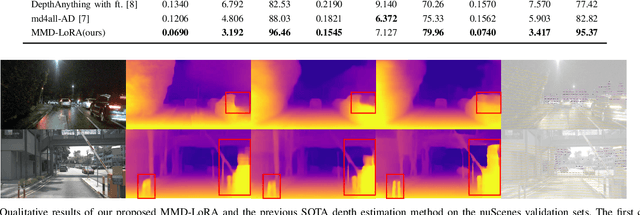

The autonomous driving community is increasingly focused on addressing corner case problems, particularly those related to ensuring driving safety under adverse conditions (e.g., nighttime, fog, rain). To this end, the task of Adverse Condition Depth Estimation (ACDE) has gained significant attention. Previous approaches in ACDE have primarily relied on generative models, which necessitate additional target images to convert the sunny condition into adverse weather, or learnable parameters for feature augmentation to adapt domain gaps, resulting in increased model complexity and tuning efforts. Furthermore, unlike CLIP-based methods where textual and visual features have been pre-aligned, depth estimation models lack sufficient alignment between multimodal features, hindering coherent understanding under adverse conditions. To address these limitations, we propose Multi-Modality Driven LoRA (MMD-LoRA), which leverages low-rank adaptation matrices for efficient fine-tuning from source-domain to target-domain. It consists of two core components: Prompt Driven Domain Alignment (PDDA) and Visual-Text Consistent Contrastive Learning(VTCCL). During PDDA, the image encoder with MMD-LoRA generates target-domain visual representations, supervised by alignment loss that the source-target difference between language and image should be equal. Meanwhile, VTCCL bridges the gap between textual features from CLIP and visual features from diffusion model, pushing apart different weather representations (vision and text) and bringing together similar ones. Through extensive experiments, the proposed method achieves state-of-the-art performance on the nuScenes and Oxford RobotCar datasets, underscoring robustness and efficiency in adapting to varied adverse environments.
Geo-ConvGRU: Geographically Masked Convolutional Gated Recurrent Unit for Bird-Eye View Segmentation
Dec 28, 2024Convolutional Neural Networks (CNNs) have significantly impacted various computer vision tasks, however, they inherently struggle to model long-range dependencies explicitly due to the localized nature of convolution operations. Although Transformers have addressed limitations in long-range dependencies for the spatial dimension, the temporal dimension remains underexplored. In this paper, we first highlight that 3D CNNs exhibit limitations in capturing long-range temporal dependencies. Though Transformers mitigate spatial dimension issues, they result in a considerable increase in parameter and processing speed reduction. To overcome these challenges, we introduce a simple yet effective module, Geographically Masked Convolutional Gated Recurrent Unit (Geo-ConvGRU), tailored for Bird's-Eye View segmentation. Specifically, we substitute the 3D CNN layers with ConvGRU in the temporal module to bolster the capacity of networks for handling temporal dependencies. Additionally, we integrate a geographical mask into the Convolutional Gated Recurrent Unit to suppress noise introduced by the temporal module. Comprehensive experiments conducted on the NuScenes dataset substantiate the merits of the proposed Geo-ConvGRU, revealing that our approach attains state-of-the-art performance in Bird's-Eye View segmentation.
Unprejudiced Training Auxiliary Tasks Makes Primary Better: A Multi-Task Learning Perspective
Dec 27, 2024Human beings can leverage knowledge from relative tasks to improve learning on a primary task. Similarly, multi-task learning methods suggest using auxiliary tasks to enhance a neural network's performance on a specific primary task. However, previous methods often select auxiliary tasks carefully but treat them as secondary during training. The weights assigned to auxiliary losses are typically smaller than the primary loss weight, leading to insufficient training on auxiliary tasks and ultimately failing to support the main task effectively. To address this issue, we propose an uncertainty-based impartial learning method that ensures balanced training across all tasks. Additionally, we consider both gradients and uncertainty information during backpropagation to further improve performance on the primary task. Extensive experiments show that our method achieves performance comparable to or better than state-of-the-art approaches. Moreover, our weighting strategy is effective and robust in enhancing the performance of the primary task regardless the noise auxiliary tasks' pseudo labels.
MR-GDINO: Efficient Open-World Continual Object Detection
Dec 23, 2024



Open-world (OW) recognition and detection models show strong zero- and few-shot adaptation abilities, inspiring their use as initializations in continual learning methods to improve performance. Despite promising results on seen classes, such OW abilities on unseen classes are largely degenerated due to catastrophic forgetting. To tackle this challenge, we propose an open-world continual object detection task, requiring detectors to generalize to old, new, and unseen categories in continual learning scenarios. Based on this task, we present a challenging yet practical OW-COD benchmark to assess detection abilities. The goal is to motivate OW detectors to simultaneously preserve learned classes, adapt to new classes, and maintain open-world capabilities under few-shot adaptations. To mitigate forgetting in unseen categories, we propose MR-GDINO, a strong, efficient and scalable baseline via memory and retrieval mechanisms within a highly scalable memory pool. Experimental results show that existing continual detectors suffer from severe forgetting for both seen and unseen categories. In contrast, MR-GDINO largely mitigates forgetting with only 0.1% activated extra parameters, achieving state-of-the-art performance for old, new, and unseen categories.
LayerMatch: Do Pseudo-labels Benefit All Layers?
Jun 20, 2024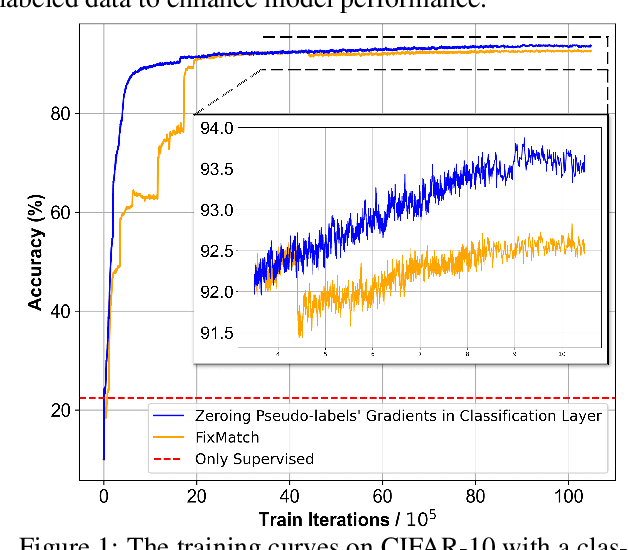
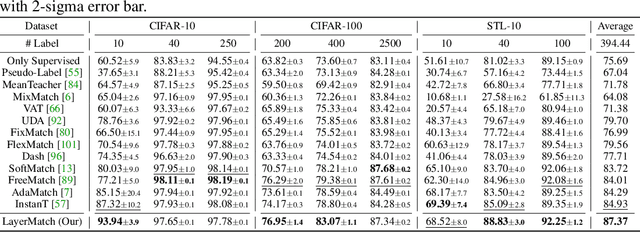
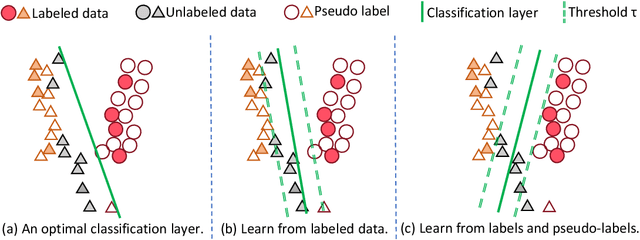
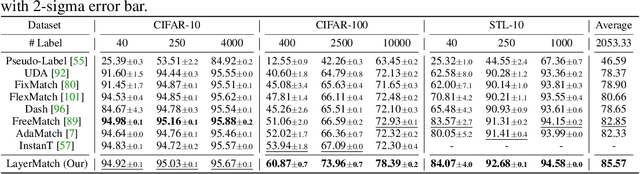
Deep neural networks have achieved remarkable performance across various tasks when supplied with large-scale labeled data. However, the collection of labeled data can be time-consuming and labor-intensive. Semi-supervised learning (SSL), particularly through pseudo-labeling algorithms that iteratively assign pseudo-labels for self-training, offers a promising solution to mitigate the dependency of labeled data. Previous research generally applies a uniform pseudo-labeling strategy across all model layers, assuming that pseudo-labels exert uniform influence throughout. Contrasting this, our theoretical analysis and empirical experiment demonstrate feature extraction layer and linear classification layer have distinct learning behaviors in response to pseudo-labels. Based on these insights, we develop two layer-specific pseudo-label strategies, termed Grad-ReLU and Avg-Clustering. Grad-ReLU mitigates the impact of noisy pseudo-labels by removing the gradient detrimental effects of pseudo-labels in the linear classification layer. Avg-Clustering accelerates the convergence of feature extraction layer towards stable clustering centers by integrating consistent outputs. Our approach, LayerMatch, which integrates these two strategies, can avoid the severe interference of noisy pseudo-labels in the linear classification layer while accelerating the clustering capability of the feature extraction layer. Through extensive experimentation, our approach consistently demonstrates exceptional performance on standard semi-supervised learning benchmarks, achieving a significant improvement of 10.38% over baseline method and a 2.44% increase compared to state-of-the-art methods.
ConSept: Continual Semantic Segmentation via Adapter-based Vision Transformer
Feb 26, 2024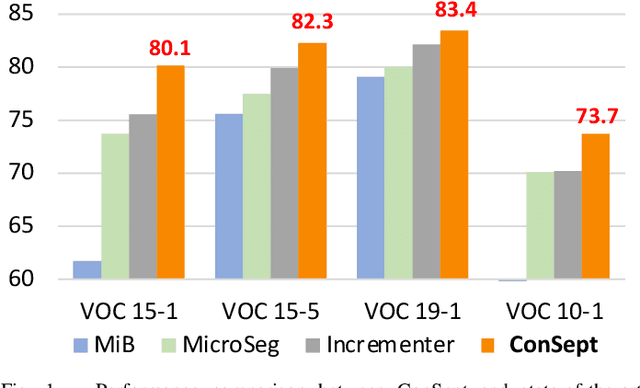
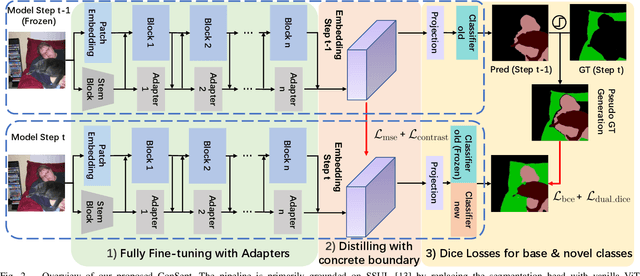
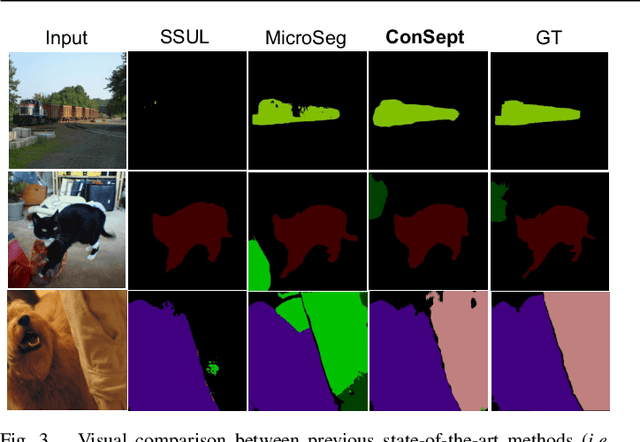

In this paper, we delve into the realm of vision transformers for continual semantic segmentation, a problem that has not been sufficiently explored in previous literature. Empirical investigations on the adaptation of existing frameworks to vanilla ViT reveal that incorporating visual adapters into ViTs or fine-tuning ViTs with distillation terms is advantageous for enhancing the segmentation capability of novel classes. These findings motivate us to propose Continual semantic Segmentation via Adapter-based ViT, namely ConSept. Within the simplified architecture of ViT with linear segmentation head, ConSept integrates lightweight attention-based adapters into vanilla ViTs. Capitalizing on the feature adaptation abilities of these adapters, ConSept not only retains superior segmentation ability for old classes, but also attains promising segmentation quality for novel classes. To further harness the intrinsic anti-catastrophic forgetting ability of ConSept and concurrently enhance the segmentation capabilities for both old and new classes, we propose two key strategies: distillation with a deterministic old-classes boundary for improved anti-catastrophic forgetting, and dual dice losses to regularize segmentation maps, thereby improving overall segmentation performance. Extensive experiments show the effectiveness of ConSept on multiple continual semantic segmentation benchmarks under overlapped or disjoint settings. Code will be publicly available at \url{https://github.com/DongSky/ConSept}.