 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Serving for Dynamic Agent Workflows with Prediction-based KV-Cache Management
May 07, 2026LLM-based workflows compose specialized agents to execute complex tasks, and these agents usually share substantial context, allowing KV-Cache reuse to save computation. Existing approaches either manage KV-Cache at agent level and fail to exploit the reuse opportunities within workflows, or manage cache at the workflow level but assume that each workflow calls a static sequence of agents. However, practical workflows are typically dynamic, where the sequence of invoked agents and thus induced cache reuse opportunities depend on the context of each task. To serve such dynamic workflows efficiently, we build a system dubbed PBKV (\textbf{P}rediction-\textbf{B}ased \textbf{KV}-Cache Management). For each workflow, PBKV predicts the agent invocations in several future steps by fusing the guidance from historical workflows and context of the target workflow. Based on the predictions, PBKV estimates the reuse potential of cache entries and keeps the high-potential entries in GPU memory. To be robust to prediction errors, PBKV utilizes the predictions conservatively during both cache eviction and prefetching. Experiments on three workflow benchmarks show that PBKV achieves up to $1.85\times$ speedup over LRU on dynamic workflows, and up to $1.26\times$ speedup over the SOTA baseline KVFlow on the static workflow.
Scheduling LLM Inference with Uncertainty-Aware Output Length Predictions
Apr 01, 2026To schedule LLM inference, the \textit{shortest job first} (SJF) principle is favorable by prioritizing requests with short output lengths to avoid head-of-line (HOL) blocking. Existing methods usually predict a single output length for each request to facilitate scheduling. We argue that such a \textit{point estimate} does not match the \textit{stochastic} decoding process of LLM inference, where output length is \textit{uncertain} by nature and determined by when the end-of-sequence (EOS) token is sampled. Hence, the output length of each request should be fitted with a distribution rather than a single value. With an in-depth analysis of empirical data and the stochastic decoding process, we observe that output length follows a heavy-tailed distribution and can be fitted with the log-t distribution. On this basis, we propose a simple metric called Tail Inflated Expectation (TIE) to replace the output length in SJF scheduling, which adjusts the expectation of a log-t distribution with its tail probabilities to account for the risk that a request generates long outputs. To evaluate our TIE scheduler, we compare it with three strong baselines, and the results show that TIE reduces the per-token latency by $2.31\times$ for online inference and improves throughput by $1.42\times$ for offline data generation.
Channel Estimation in MIMO Systems Using Flow Matching Models
Jan 20, 2026Multiple-input multiple-output (MIMO) systems require efficient and accurate channel estimation with low pilot overhead to unlock their full potential for high spectral and energy efficiency. While deep generative models have emerged as a powerful foundation for the channel estimation task, the existing approaches using diffusion-based and score-based models suffer from high computational runtime due to their stochastic and many-step iterative sampling. In this paper, we introduce a flow matching-based channel estimator to overcome this limitation. The proposed channel estimator is based on a deep neural network trained to learn the velocity field of wireless channels, which we then integrate into a plug-and-play proximal gradient descent (PnP-PGD) framework. Simulation results reveal that our formulated approach consistently outperforms existing state-of-the-art (SOTA) generative model-based estimators, achieves up to 49 times faster inference at test time, and reduces up to 20 times peak graphics processing unit (GPU) memory usage. Our code and models are publicly available to support reproducible research.
Causal-Tune: Mining Causal Factors from Vision Foundation Models for Domain Generalized Semantic Segmentation
Dec 18, 2025Fine-tuning Vision Foundation Models (VFMs) with a small number of parameters has shown remarkable performance in Domain Generalized Semantic Segmentation (DGSS). Most existing works either train lightweight adapters or refine intermediate features to achieve better generalization on unseen domains. However, they both overlook the fact that long-term pre-trained VFMs often exhibit artifacts, which hinder the utilization of valuable representations and ultimately degrade DGSS performance. Inspired by causal mechanisms, we observe that these artifacts are associated with non-causal factors, which usually reside in the low- and high-frequency components of the VFM spectrum. In this paper, we explicitly examine the causal and non-causal factors of features within VFMs for DGSS, and propose a simple yet effective method to identify and disentangle them, enabling more robust domain generalization. Specifically, we propose Causal-Tune, a novel fine-tuning strategy designed to extract causal factors and suppress non-causal ones from the features of VFMs. First, we extract the frequency spectrum of features from each layer using the Discrete Cosine Transform (DCT). A Gaussian band-pass filter is then applied to separate the spectrum into causal and non-causal components. To further refine the causal components, we introduce a set of causal-aware learnable tokens that operate in the frequency domain, while the non-causal components are discarded. Finally, refined features are transformed back into the spatial domain via inverse DCT and passed to the next layer. Extensive experiments conducted on various cross-domain tasks demonstrate the effectiveness of Causal-Tune. In particular, our method achieves superior performance under adverse weather conditions, improving +4.8% mIoU over the baseline in snow conditions.
You Only Evaluate Once: A Tree-based Rerank Method at Meituan
Aug 20, 2025

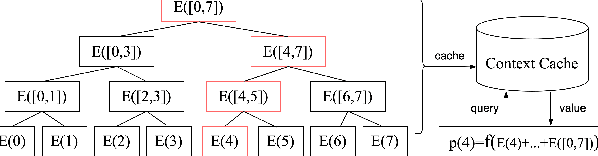

Reranking plays a crucial role in modern recommender systems by capturing the mutual influences within the list. Due to the inherent challenges of combinatorial search spaces, most methods adopt a two-stage search paradigm: a simple General Search Unit (GSU) efficiently reduces the candidate space, and an Exact Search Unit (ESU) effectively selects the optimal sequence. These methods essentially involve making trade-offs between effectiveness and efficiency, while suffering from a severe \textbf{inconsistency problem}, that is, the GSU often misses high-value lists from ESU. To address this problem, we propose YOLOR, a one-stage reranking method that removes the GSU while retaining only the ESU. Specifically, YOLOR includes: (1) a Tree-based Context Extraction Module (TCEM) that hierarchically aggregates multi-scale contextual features to achieve "list-level effectiveness", and (2) a Context Cache Module (CCM) that enables efficient feature reuse across candidate permutations to achieve "permutation-level efficiency". Extensive experiments across public and industry datasets validate YOLOR's performance, and we have successfully deployed YOLOR on the Meituan food delivery platform.
Multi-Modality Driven LoRA for Adverse Condition Depth Estimation
Dec 28, 2024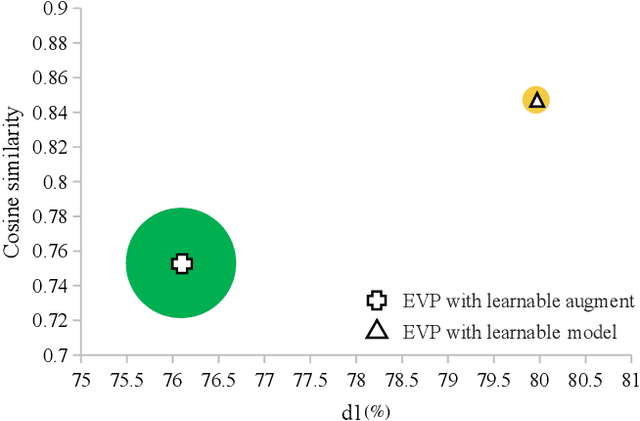
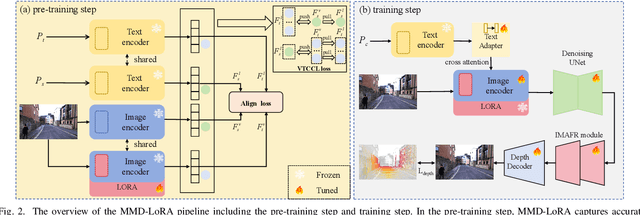
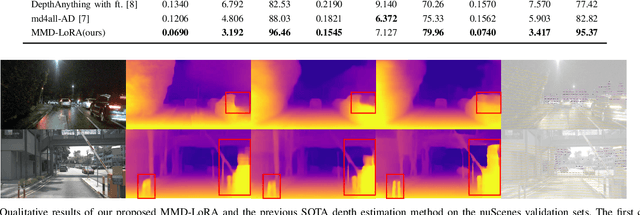

The autonomous driving community is increasingly focused on addressing corner case problems, particularly those related to ensuring driving safety under adverse conditions (e.g., nighttime, fog, rain). To this end, the task of Adverse Condition Depth Estimation (ACDE) has gained significant attention. Previous approaches in ACDE have primarily relied on generative models, which necessitate additional target images to convert the sunny condition into adverse weather, or learnable parameters for feature augmentation to adapt domain gaps, resulting in increased model complexity and tuning efforts. Furthermore, unlike CLIP-based methods where textual and visual features have been pre-aligned, depth estimation models lack sufficient alignment between multimodal features, hindering coherent understanding under adverse conditions. To address these limitations, we propose Multi-Modality Driven LoRA (MMD-LoRA), which leverages low-rank adaptation matrices for efficient fine-tuning from source-domain to target-domain. It consists of two core components: Prompt Driven Domain Alignment (PDDA) and Visual-Text Consistent Contrastive Learning(VTCCL). During PDDA, the image encoder with MMD-LoRA generates target-domain visual representations, supervised by alignment loss that the source-target difference between language and image should be equal. Meanwhile, VTCCL bridges the gap between textual features from CLIP and visual features from diffusion model, pushing apart different weather representations (vision and text) and bringing together similar ones. Through extensive experiments, the proposed method achieves state-of-the-art performance on the nuScenes and Oxford RobotCar datasets, underscoring robustness and efficiency in adapting to varied adverse environments.
Geo-ConvGRU: Geographically Masked Convolutional Gated Recurrent Unit for Bird-Eye View Segmentation
Dec 28, 2024Convolutional Neural Networks (CNNs) have significantly impacted various computer vision tasks, however, they inherently struggle to model long-range dependencies explicitly due to the localized nature of convolution operations. Although Transformers have addressed limitations in long-range dependencies for the spatial dimension, the temporal dimension remains underexplored. In this paper, we first highlight that 3D CNNs exhibit limitations in capturing long-range temporal dependencies. Though Transformers mitigate spatial dimension issues, they result in a considerable increase in parameter and processing speed reduction. To overcome these challenges, we introduce a simple yet effective module, Geographically Masked Convolutional Gated Recurrent Unit (Geo-ConvGRU), tailored for Bird's-Eye View segmentation. Specifically, we substitute the 3D CNN layers with ConvGRU in the temporal module to bolster the capacity of networks for handling temporal dependencies. Additionally, we integrate a geographical mask into the Convolutional Gated Recurrent Unit to suppress noise introduced by the temporal module. Comprehensive experiments conducted on the NuScenes dataset substantiate the merits of the proposed Geo-ConvGRU, revealing that our approach attains state-of-the-art performance in Bird's-Eye View segmentation.
Boosting Long-tailed Object Detection via Step-wise Learning on Smooth-tail Data
May 22, 2023


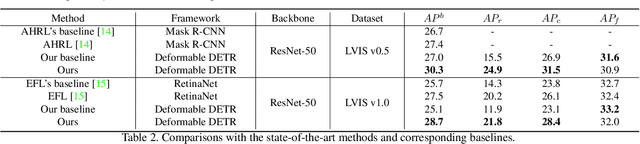
Real-world data tends to follow a long-tailed distribution, where the class imbalance results in dominance of the head classes during training. In this paper, we propose a frustratingly simple but effective step-wise learning framework to gradually enhance the capability of the model in detecting all categories of long-tailed datasets. Specifically, we build smooth-tail data where the long-tailed distribution of categories decays smoothly to correct the bias towards head classes. We pre-train a model on the whole long-tailed data to preserve discriminability between all categories. We then fine-tune the class-agnostic modules of the pre-trained model on the head class dominant replay data to get a head class expert model with improved decision boundaries from all categories. Finally, we train a unified model on the tail class dominant replay data while transferring knowledge from the head class expert model to ensure accurate detection of all categories. Extensive experiments on long-tailed datasets LVIS v0.5 and LVIS v1.0 demonstrate the superior performance of our method, where we can improve the AP with ResNet-50 backbone from 27.0% to 30.3% AP, and especially for the rare categories from 15.5% to 24.9% AP. Our best model using ResNet-101 backbone can achieve 30.7% AP, which suppresses all existing detectors using the same backbone.
NeFII: Inverse Rendering for Reflectance Decomposition with Near-Field Indirect Illumination
Mar 29, 2023



Inverse rendering methods aim to estimate geometry, materials and illumination from multi-view RGB images. In order to achieve better decomposition, recent approaches attempt to model indirect illuminations reflected from different materials via Spherical Gaussians (SG), which, however, tends to blur the high-frequency reflection details. In this paper, we propose an end-to-end inverse rendering pipeline that decomposes materials and illumination from multi-view images, while considering near-field indirect illumination. In a nutshell, we introduce the Monte Carlo sampling based path tracing and cache the indirect illumination as neural radiance, enabling a physics-faithful and easy-to-optimize inverse rendering method. To enhance efficiency and practicality, we leverage SG to represent the smooth environment illuminations and apply importance sampling techniques. To supervise indirect illuminations from unobserved directions, we develop a novel radiance consistency constraint between implicit neural radiance and path tracing results of unobserved rays along with the joint optimization of materials and illuminations, thus significantly improving the decomposition performance. Extensive experiments demonstrate that our method outperforms the state-of-the-art on multiple synthetic and real datasets, especially in terms of inter-reflection decomposition.
Open World DETR: Transformer based Open World Object Detection
Dec 06, 2022


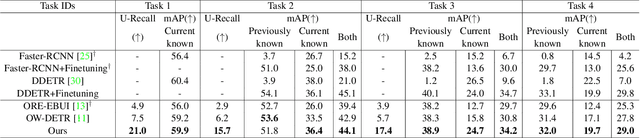
Open world object detection aims at detecting objects that are absent in the object classes of the training data as unknown objects without explicit supervision. Furthermore, the exact classes of the unknown objects must be identified without catastrophic forgetting of the previous known classes when the corresponding annotations of unknown objects are given incrementally. In this paper, we propose a two-stage training approach named Open World DETR for open world object detection based on Deformable DETR. In the first stage, we pre-train a model on the current annotated data to detect objects from the current known classes, and concurrently train an additional binary classifier to classify predictions into foreground or background classes. This helps the model to build an unbiased feature representations that can facilitate the detection of unknown classes in subsequent process. In the second stage, we fine-tune the class-specific components of the model with a multi-view self-labeling strategy and a consistency constraint. Furthermore, we alleviate catastrophic forgetting when the annotations of the unknown classes becomes available incrementally by using knowledge distillation and exemplar replay. Experimental results on PASCAL VOC and MS-COCO show that our proposed method outperforms other state-of-the-art open world object detection methods by a large margin.