 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartImageNet++ Dataset: Enhancing Visual Models with High-Quality Part Annotations
Jan 04, 2026To address the scarcity of high-quality part annotations in existing datasets, we introduce PartImageNet++ (PIN++), a dataset that provides detailed part annotations for all categories in ImageNet-1K. With 100 annotated images per category, totaling 100K images, PIN++ represents the most comprehensive dataset covering a diverse range of object categories. Leveraging PIN++, we propose a Multi-scale Part-supervised recognition Model (MPM) for robust classification on ImageNet-1K. We first trained a part segmentation network using PIN++ and used it to generate pseudo part labels for the remaining unannotated images. MPM then integrated a conventional recognition architecture with auxiliary bypass layers, jointly supervised by both pseudo part labels and the original part annotations. Furthermore, we conducted extensive experiments on PIN++, including part segmentation, object segmentation, and few-shot learning, exploring various ways to leverage part annotations in downstream tasks. Experimental results demonstrated that our approach not only enhanced part-based models for robust object recognition but also established strong baselines for multiple downstream tasks, highlighting the potential of part annotations in improving model performance. The dataset and the code are available at https://github.com/LixiaoTHU/PartImageNetPP.
PartImageNet++ Dataset: Scaling up Part-based Models for Robust Recognition
Jul 15, 2024
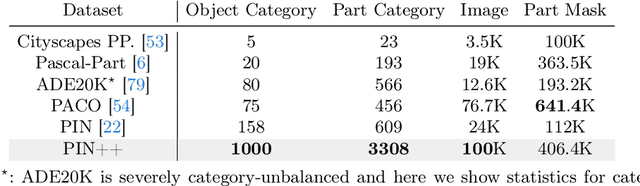

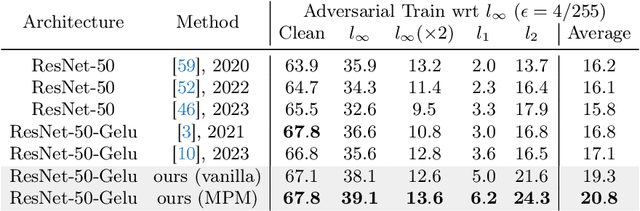
Deep learning-based object recognition systems can be easily fooled by various adversarial perturbations. One reason for the weak robustness may be that they do not have part-based inductive bias like the human recognition process. Motivated by this, several part-based recognition models have been proposed to improve the adversarial robustness of recognition. However, due to the lack of part annotations, the effectiveness of these methods is only validated on small-scale nonstandard datasets. In this work, we propose PIN++, short for PartImageNet++, a dataset providing high-quality part segmentation annotations for all categories of ImageNet-1K (IN-1K). With these annotations, we build part-based methods directly on the standard IN-1K dataset for robust recognition. Different from previous two-stage part-based models, we propose a Multi-scale Part-supervised Model (MPM), to learn a robust representation with part annotations. Experiments show that MPM yielded better adversarial robustness on the large-scale IN-1K over strong baselines across various attack settings. Furthermore, MPM achieved improved robustness on common corruptions and several out-of-distribution datasets. The dataset, together with these results, enables and encourages researchers to explore the potential of part-based models in more real applications.
Boosting Long-tailed Object Detection via Step-wise Learning on Smooth-tail Data
May 22, 2023


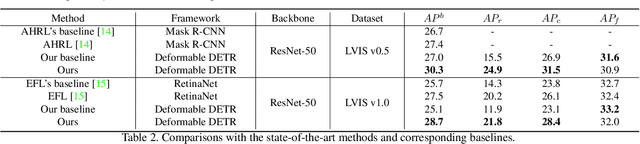
Real-world data tends to follow a long-tailed distribution, where the class imbalance results in dominance of the head classes during training. In this paper, we propose a frustratingly simple but effective step-wise learning framework to gradually enhance the capability of the model in detecting all categories of long-tailed datasets. Specifically, we build smooth-tail data where the long-tailed distribution of categories decays smoothly to correct the bias towards head classes. We pre-train a model on the whole long-tailed data to preserve discriminability between all categories. We then fine-tune the class-agnostic modules of the pre-trained model on the head class dominant replay data to get a head class expert model with improved decision boundaries from all categories. Finally, we train a unified model on the tail class dominant replay data while transferring knowledge from the head class expert model to ensure accurate detection of all categories. Extensive experiments on long-tailed datasets LVIS v0.5 and LVIS v1.0 demonstrate the superior performance of our method, where we can improve the AP with ResNet-50 backbone from 27.0% to 30.3% AP, and especially for the rare categories from 15.5% to 24.9% AP. Our best model using ResNet-101 backbone can achieve 30.7% AP, which suppresses all existing detectors using the same backbone.
Open World DETR: Transformer based Open World Object Detection
Dec 06, 2022


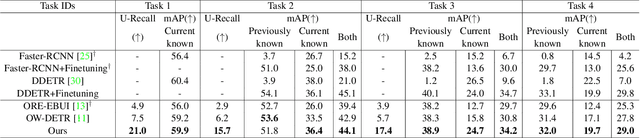
Open world object detection aims at detecting objects that are absent in the object classes of the training data as unknown objects without explicit supervision. Furthermore, the exact classes of the unknown objects must be identified without catastrophic forgetting of the previous known classes when the corresponding annotations of unknown objects are given incrementally. In this paper, we propose a two-stage training approach named Open World DETR for open world object detection based on Deformable DETR. In the first stage, we pre-train a model on the current annotated data to detect objects from the current known classes, and concurrently train an additional binary classifier to classify predictions into foreground or background classes. This helps the model to build an unbiased feature representations that can facilitate the detection of unknown classes in subsequent process. In the second stage, we fine-tune the class-specific components of the model with a multi-view self-labeling strategy and a consistency constraint. Furthermore, we alleviate catastrophic forgetting when the annotations of the unknown classes becomes available incrementally by using knowledge distillation and exemplar replay. Experimental results on PASCAL VOC and MS-COCO show that our proposed method outperforms other state-of-the-art open world object detection methods by a large margin.
Incremental-DETR: Incremental Few-Shot Object Detection via Self-Supervised Learning
May 19, 2022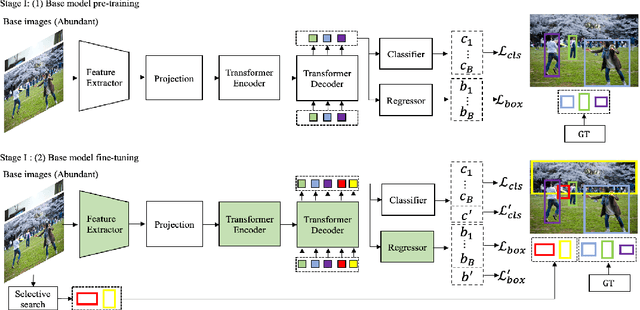

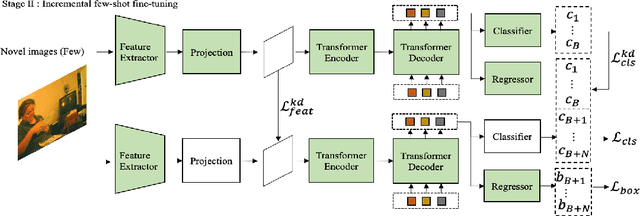
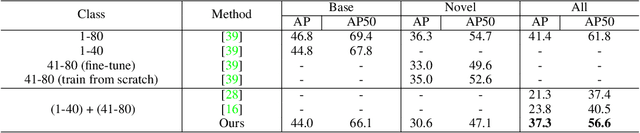
Incremental few-shot object detection aims at detecting novel classes without forgetting knowledge of the base classes with only a few labeled training data from the novel classes. Most related prior works are on incremental object detection that rely on the availability of abundant training samples per novel class that substantially limits the scalability to real-world setting where novel data can be scarce. In this paper, we propose the Incremental-DETR that does incremental few-shot object detection via fine-tuning and self-supervised learning on the DETR object detector. To alleviate severe over-fitting with few novel class data, we first fine-tune the class-specific components of DETR with self-supervision from additional object proposals generated using Selective Search as pseudo labels. We further introduce a incremental few-shot fine-tuning strategy with knowledge distillation on the class-specific components of DETR to encourage the network in detecting novel classes without catastrophic forgetting. Extensive experiments conducted on standard incremental object detection and incremental few-shot object detection settings show that our approach significantly outperforms state-of-the-art methods by a large margin.
Bridging Non Co-occurrence with Unlabeled In-the-wild Data for Incremental Object Detection
Oct 28, 2021
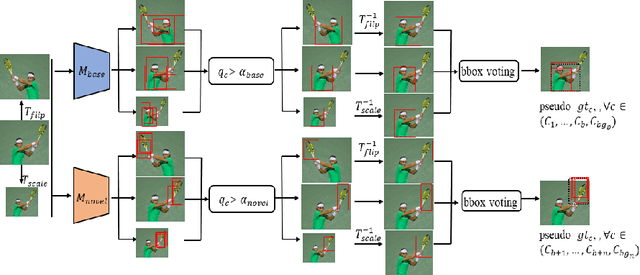
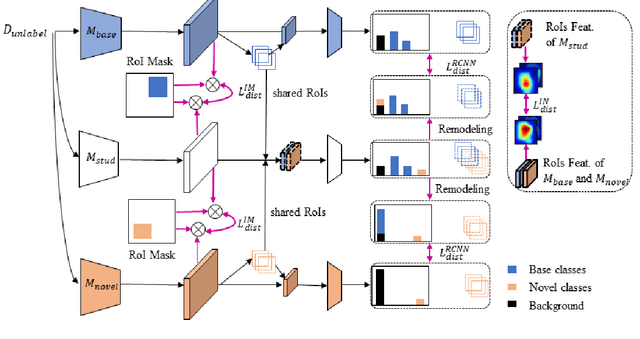
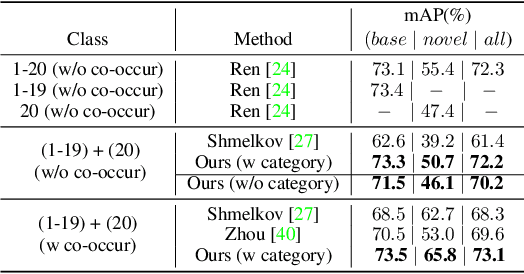
Deep networks have shown remarkable results in the task of object detection. However, their performance suffers critical drops when they are subsequently trained on novel classes without any sample from the base classes originally used to train the model. This phenomenon is known as catastrophic forgetting. Recently, several incremental learning methods are proposed to mitigate catastrophic forgetting for object detection. Despite the effectiveness, these methods require co-occurrence of the unlabeled base classes in the training data of the novel classes. This requirement is impractical in many real-world settings since the base classes do not necessarily co-occur with the novel classes. In view of this limitation, we consider a more practical setting of complete absence of co-occurrence of the base and novel classes for the object detection task. We propose the use of unlabeled in-the-wild data to bridge the non co-occurrence caused by the missing base classes during the training of additional novel classes. To this end, we introduce a blind sampling strategy based on the responses of the base-class model and pre-trained novel-class model to select a smaller relevant dataset from the large in-the-wild dataset for incremental learning. We then design a dual-teacher distillation framework to transfer the knowledge distilled from the base- and novel-class teacher models to the student model using the sampled in-the-wild data. Experimental results on the PASCAL VOC and MS COCO datasets show that our proposed method significantly outperforms other state-of-the-art class-incremental object detection methods when there is no co-occurrence between the base and novel classes during training.
White blood cell classification
Sep 04, 2020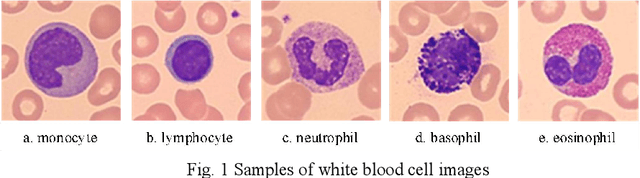

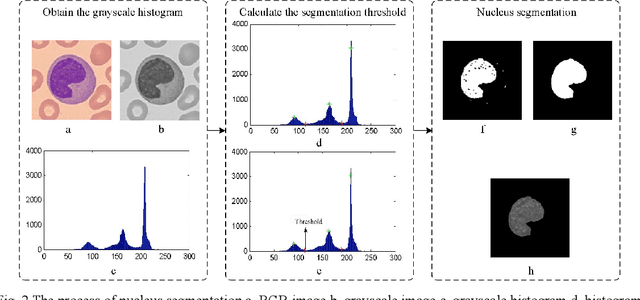
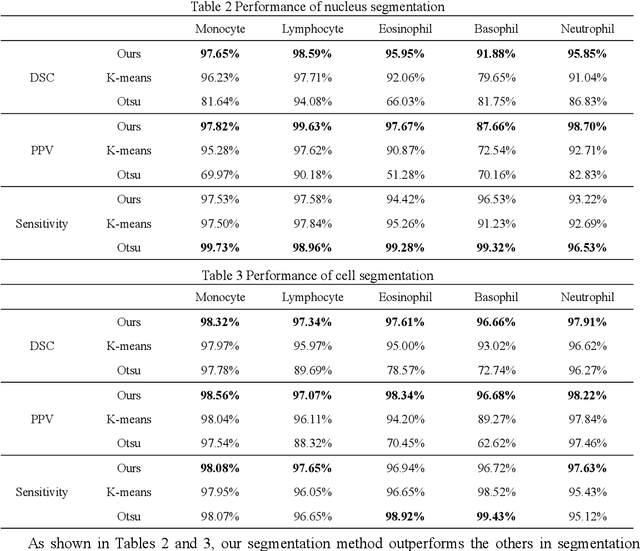
This paper proposes a novel automatic classification framework for the recognition of five types of white blood cells. Segmenting complete white blood cells from blood smears images and extracting advantageous features from them remain challenging tasks in the classification of white blood cells. Therefore, we present an adaptive threshold segmentation method to deal with blood smears images with non-uniform color and uneven illumination, which is designed based on color space information and threshold segmentation. Subsequently, after successfully separating the white blood cell from the blood smear image, a large number of nonlinear features including geometrical, color and texture features are extracted. Nevertheless, redundant features can affect the classification speed and efficiency, and in view of that, a feature selection algorithm based on classification and regression trees (CART) is designed. Through in-depth analysis of the nonlinear relationship between features, the irrelevant and redundant features are successfully removed from the initial nonlinear features. Afterwards, the selected prominent features are fed into particle swarm optimization support vector machine (PSO-SVM) classifier to recognize the types of the white blood cells. Finally, to evaluate the performance of the proposed white blood cell classification methodology, we build a white blood cell data set containing 500 blood smear images for experiments. By comparing with the ground truth obtained manually, the proposed segmentation method achieves an average of 95.98% and 97.57% dice similarity for segmented nucleus and cell regions respectively. Furthermore, the proposed methodology achieves 99.76% classification accuracy, which well demonstrates its effectiveness.
Research on fuzzy PID Shared control method of small brain-controlled uav
May 29, 2019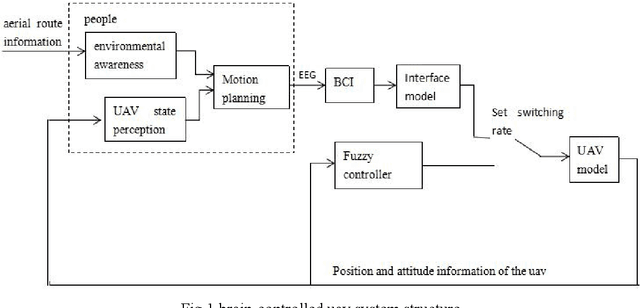
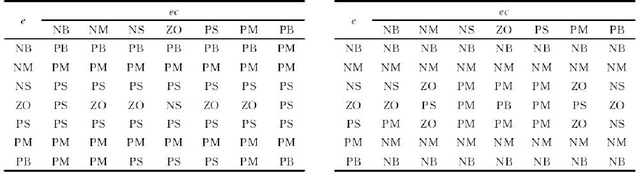
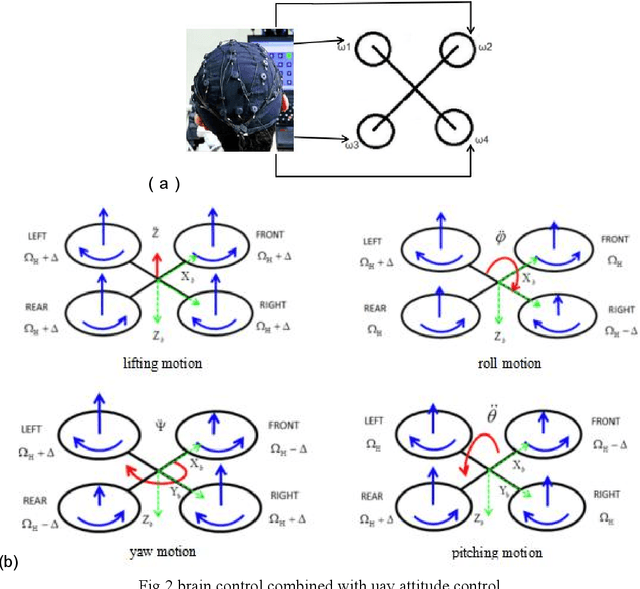
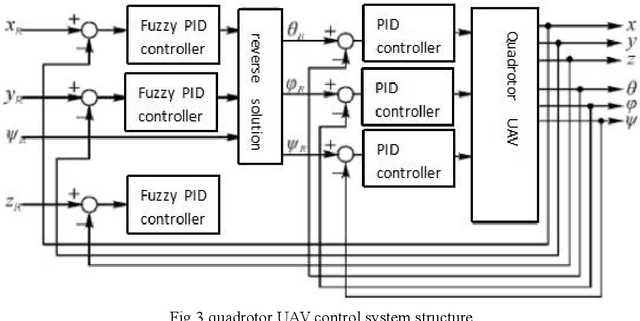
Brain-controlled unmanned aerial vehicle (uav) is a uav that can analyze human brain electrical signals through BCI to obtain flight commands. The research of brain-controlled uav can promote the integration of brain-computer and has a broad application prospect. At present, BCI still has some problems, such as limited recognition accuracy, limited recognition time and small number of recognition commands in the acquisition of control commands by analyzing eeg signals. Therefore, the control performance of the quadrotor which is controlled only by brain is not ideal. Based on the concept of Shared control, this paper designs an assistant controller using fuzzy PID control, and realizes the cooperative control between automatic control and brain control. By evaluating the current flight status and setting the switching rate, the switching mechanism of automatic control and brain control can be decided to improve the system control performance. Finally, a rectangular trajectory tracking control experiment of the same height is designed for small quadrotor to verify the algorithm.