 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Non Co-occurrence with Unlabeled In-the-wild Data for Incremental Object Detection
Paper and Code

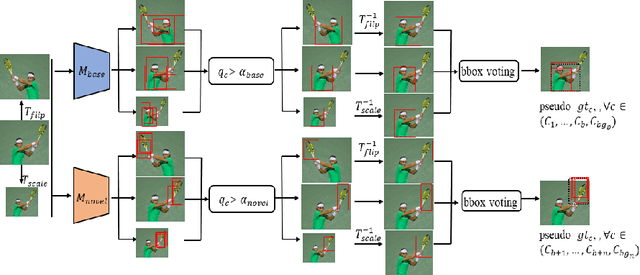
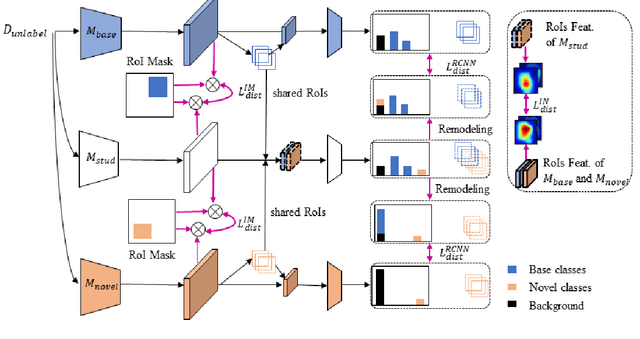
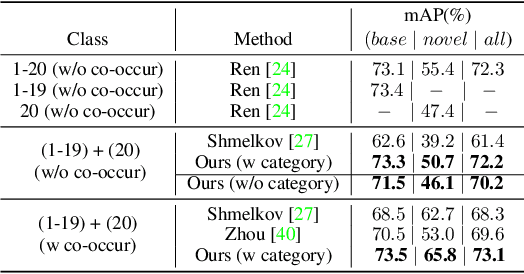
Deep networks have shown remarkable results in the task of object detection. However, their performance suffers critical drops when they are subsequently trained on novel classes without any sample from the base classes originally used to train the model. This phenomenon is known as catastrophic forgetting. Recently, several incremental learning methods are proposed to mitigate catastrophic forgetting for object detection. Despite the effectiveness, these methods require co-occurrence of the unlabeled base classes in the training data of the novel classes. This requirement is impractical in many real-world settings since the base classes do not necessarily co-occur with the novel classes. In view of this limitation, we consider a more practical setting of complete absence of co-occurrence of the base and novel classes for the object detection task. We propose the use of unlabeled in-the-wild data to bridge the non co-occurrence caused by the missing base classes during the training of additional novel classes. To this end, we introduce a blind sampling strategy based on the responses of the base-class model and pre-trained novel-class model to select a smaller relevant dataset from the large in-the-wild dataset for incremental learning. We then design a dual-teacher distillation framework to transfer the knowledge distilled from the base- and novel-class teacher models to the student model using the sampled in-the-wild data. Experimental results on the PASCAL VOC and MS COCO datasets show that our proposed method significantly outperforms other state-of-the-art class-incremental object detection methods when there is no co-occurrence between the base and novel classes during training.