 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartImageNet++ Dataset: Enhancing Visual Models with High-Quality Part Annotations
Jan 04, 2026To address the scarcity of high-quality part annotations in existing datasets, we introduce PartImageNet++ (PIN++), a dataset that provides detailed part annotations for all categories in ImageNet-1K. With 100 annotated images per category, totaling 100K images, PIN++ represents the most comprehensive dataset covering a diverse range of object categories. Leveraging PIN++, we propose a Multi-scale Part-supervised recognition Model (MPM) for robust classification on ImageNet-1K. We first trained a part segmentation network using PIN++ and used it to generate pseudo part labels for the remaining unannotated images. MPM then integrated a conventional recognition architecture with auxiliary bypass layers, jointly supervised by both pseudo part labels and the original part annotations. Furthermore, we conducted extensive experiments on PIN++, including part segmentation, object segmentation, and few-shot learning, exploring various ways to leverage part annotations in downstream tasks. Experimental results demonstrated that our approach not only enhanced part-based models for robust object recognition but also established strong baselines for multiple downstream tasks, highlighting the potential of part annotations in improving model performance. The dataset and the code are available at https://github.com/LixiaoTHU/PartImageNetPP.
KIT's Low-resource Speech Translation Systems for IWSLT2025: System Enhancement with Synthetic Data and Model Regularization
May 26, 2025This paper presents KIT's submissions to the IWSLT 2025 low-resource track. We develop both cascaded systems, consisting of Automatic Speech Recognition (ASR) and Machine Translation (MT) models, and end-to-end (E2E) Speech Translation (ST) systems for three language pairs: Bemba, North Levantine Arabic, and Tunisian Arabic into English. Building upon pre-trained models, we fine-tune our systems with different strategies to utilize resources efficiently. This study further explores system enhancement with synthetic data and model regularization. Specifically, we investigate MT-augmented ST by generating translations from ASR data using MT models. For North Levantine, which lacks parallel ST training data, a system trained solely on synthetic data slightly surpasses the cascaded system trained on real data. We also explore augmentation using text-to-speech models by generating synthetic speech from MT data, demonstrating the benefits of synthetic data in improving both ASR and ST performance for Bemba. Additionally, we apply intra-distillation to enhance model performance. Our experiments show that this approach consistently improves results across ASR, MT, and ST tasks, as well as across different pre-trained models. Finally, we apply Minimum Bayes Risk decoding to combine the cascaded and end-to-end systems, achieving an improvement of approximately 1.5 BLEU points.
Geometric Framework for 3D Cell Segmentation Correction
Feb 03, 2025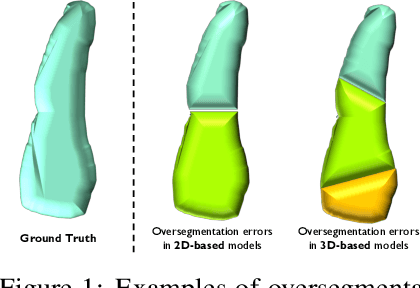
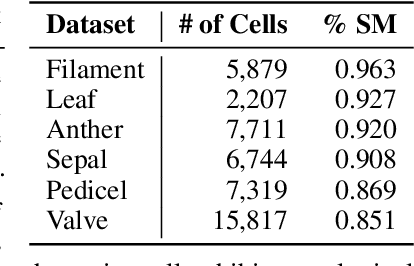
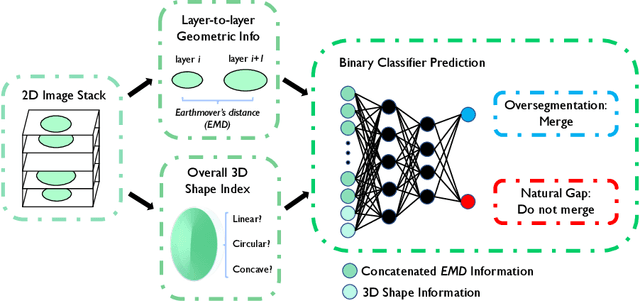
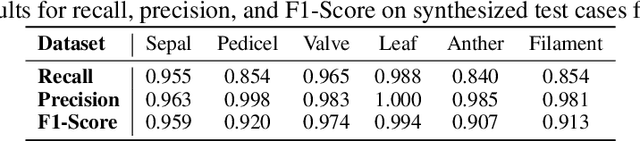
3D cellular image segmentation methods are commonly divided into non-2D-based and 2D-based approaches, the latter reconstructing 3D shapes from the segmentation results of 2D layers. However, errors in 2D results often propagate, leading to oversegmentations in the final 3D results. To tackle this issue, we introduce an interpretable geometric framework that addresses the oversegmentations by correcting the 2D segmentation results based on geometric information from adjacent layers. Leveraging both geometric (layer-to-layer, 2D) and topological (3D shape) features, we use binary classification to determine whether neighboring cells should be stitched. We develop a pre-trained classifier on public plant cell datasets and validate its performance on animal cell datasets, confirming its effectiveness in correcting oversegmentations under the transfer learning setting. Furthermore, we demonstrate that our framework can be extended to correcting oversegmentation on non-2D-based methods. A clear pipeline is provided for end-users to build the pre-trained model to any labeled dataset.
ADBM: Adversarial diffusion bridge model for reliable adversarial purification
Aug 01, 2024



Recently Diffusion-based Purification (DiffPure) has been recognized as an effective defense method against adversarial examples. However, we find DiffPure which directly employs the original pre-trained diffusion models for adversarial purification, to be suboptimal. This is due to an inherent trade-off between noise purification performance and data recovery quality. Additionally, the reliability of existing evaluations for DiffPure is questionable, as they rely on weak adaptive attacks. In this work, we propose a novel Adversarial Diffusion Bridge Model, termed ADBM. ADBM directly constructs a reverse bridge from the diffused adversarial data back to its original clean examples, enhancing the purification capabilities of the original diffusion models. Through theoretical analysis and experimental validation across various scenarios, ADBM has proven to be a superior and robust defense mechanism, offering significant promise for practical applications.
Speech Editing -- a Summary
Jul 24, 2024



With the rise of video production and social media, speech editing has become crucial for creators to address issues like mispronunciations, missing words, or stuttering in audio recordings. This paper explores text-based speech editing methods that modify audio via text transcripts without manual waveform editing. These approaches ensure edited audio is indistinguishable from the original by altering the mel-spectrogram. Recent advancements, such as context-aware prosody correction and advanced attention mechanisms, have improved speech editing quality. This paper reviews state-of-the-art methods, compares key metrics, and examines widely used datasets. The aim is to highlight ongoing issues and inspire further research and innovation in speech editing.
PartImageNet++ Dataset: Scaling up Part-based Models for Robust Recognition
Jul 15, 2024
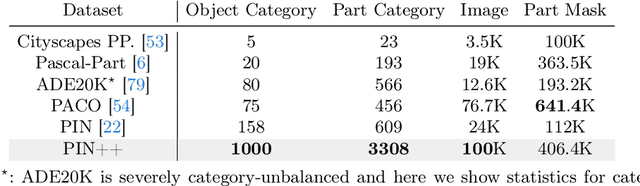

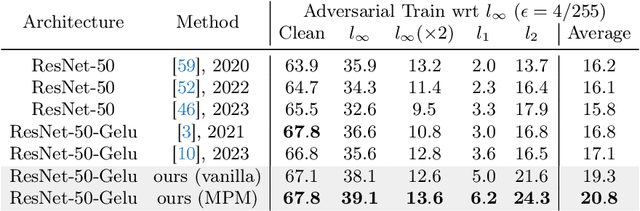
Deep learning-based object recognition systems can be easily fooled by various adversarial perturbations. One reason for the weak robustness may be that they do not have part-based inductive bias like the human recognition process. Motivated by this, several part-based recognition models have been proposed to improve the adversarial robustness of recognition. However, due to the lack of part annotations, the effectiveness of these methods is only validated on small-scale nonstandard datasets. In this work, we propose PIN++, short for PartImageNet++, a dataset providing high-quality part segmentation annotations for all categories of ImageNet-1K (IN-1K). With these annotations, we build part-based methods directly on the standard IN-1K dataset for robust recognition. Different from previous two-stage part-based models, we propose a Multi-scale Part-supervised Model (MPM), to learn a robust representation with part annotations. Experiments show that MPM yielded better adversarial robustness on the large-scale IN-1K over strong baselines across various attack settings. Furthermore, MPM achieved improved robustness on common corruptions and several out-of-distribution datasets. The dataset, together with these results, enables and encourages researchers to explore the potential of part-based models in more real applications.
Anchor-Based Adversarially Robust Zero-Shot Learning Driven by Language
Jan 30, 2023Deep neural networks are vulnerable to adversarial attacks. We consider adversarial defense in the case of zero-shot image classification setting, which has rarely been explored because both adversarial defense and zero-shot learning are challenging. We propose LAAT, a novel Language-driven, Anchor-based Adversarial Training strategy, to improve the adversarial robustness in a zero-shot setting. LAAT uses a text encoder to obtain fixed anchors (normalized feature embeddings) of each category, then uses these anchors to perform adversarial training. The text encoder has the property that semantically similar categories can be mapped to neighboring anchors in the feature space. By leveraging this property, LAAT can make the image model adversarially robust on novel categories without any extra examples. Experimental results show that our method achieves impressive zero-shot adversarial performance, even surpassing the previous state-of-the-art adversarially robust one-shot methods in most attacking settings. When models are trained with LAAT on large datasets like ImageNet-1K, they can have substantial zero-shot adversarial robustness across several downstream datasets.