 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Long-Form Speech Instruction Following: KIT's Submission to IWSLT 2026
Jun 03, 2026With the advent of Large Language Models, single-task and token-based multi-task models have evolved into instruction-based systems that infer task and target language implicitly from natural language prompts. This trend is reflected in IWSLT's Instruction Following Track, which this year introduced new tasks including an unknown surprise task, posing a genuine challenge against overfitting to known tasks. We present KIT's submission to the Long and Short Instruction Following tracks in the unconstrained setting. Our approach combines a general data augmentation pipeline that converts short-form corpora into long-form training data through segment concatenation, LLM-based label generation, and cross-lingual translation, yielding over 1M instances across six tasks and four languages. We further show that likelihood-based re-ranking, while highly effective for ASR, systematically degrades semantic tasks by spuriously selecting candidates generated from segmented audio processing rather than holistic long-form inference, a failure mode resolved by combining likelihood with Minimum Bayes Risk decoding.
KIT's Low-resource Speech Translation Systems for IWSLT2025: System Enhancement with Synthetic Data and Model Regularization
May 26, 2025This paper presents KIT's submissions to the IWSLT 2025 low-resource track. We develop both cascaded systems, consisting of Automatic Speech Recognition (ASR) and Machine Translation (MT) models, and end-to-end (E2E) Speech Translation (ST) systems for three language pairs: Bemba, North Levantine Arabic, and Tunisian Arabic into English. Building upon pre-trained models, we fine-tune our systems with different strategies to utilize resources efficiently. This study further explores system enhancement with synthetic data and model regularization. Specifically, we investigate MT-augmented ST by generating translations from ASR data using MT models. For North Levantine, which lacks parallel ST training data, a system trained solely on synthetic data slightly surpasses the cascaded system trained on real data. We also explore augmentation using text-to-speech models by generating synthetic speech from MT data, demonstrating the benefits of synthetic data in improving both ASR and ST performance for Bemba. Additionally, we apply intra-distillation to enhance model performance. Our experiments show that this approach consistently improves results across ASR, MT, and ST tasks, as well as across different pre-trained models. Finally, we apply Minimum Bayes Risk decoding to combine the cascaded and end-to-end systems, achieving an improvement of approximately 1.5 BLEU points.
PIER: A Novel Metric for Evaluating What Matters in Code-Switching
Jan 16, 2025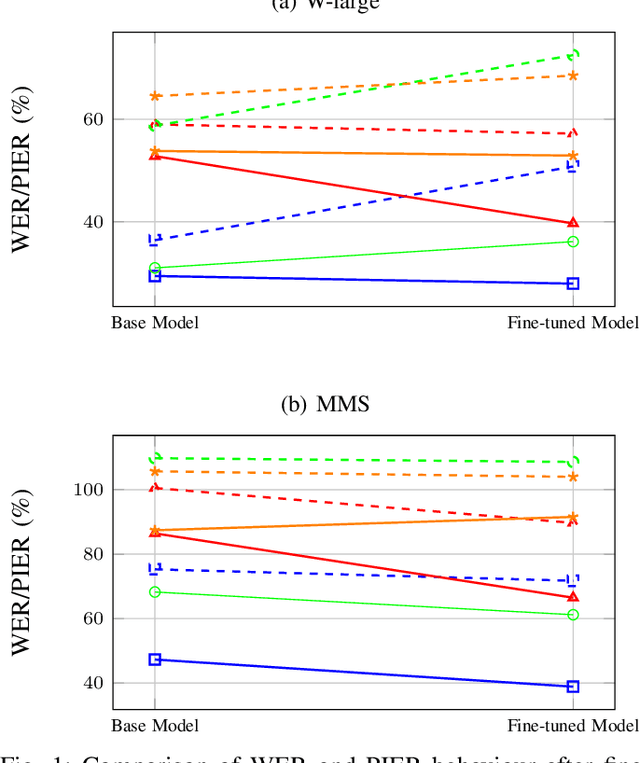
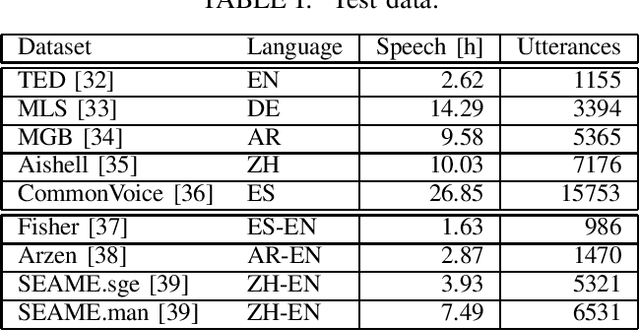
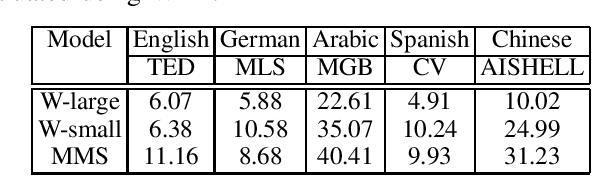
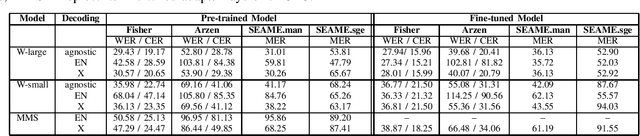
Code-switching, the alternation of languages within a single discourse, presents a significant challenge for Automatic Speech Recognition. Despite the unique nature of the task, performance is commonly measured with established metrics such as Word-Error-Rate (WER). However, in this paper, we question whether these general metrics accurately assess performance on code-switching. Specifically, using both Connectionist-Temporal-Classification and Encoder-Decoder models, we show fine-tuning on non-code-switched data from both matrix and embedded language improves classical metrics on code-switching test sets, although actual code-switched words worsen (as expected). Therefore, we propose Point-of-Interest Error Rate (PIER), a variant of WER that focuses only on specific words of interest. We instantiate PIER on code-switched utterances and show that this more accurately describes the code-switching performance, showing huge room for improvement in future work. This focused evaluation allows for a more precise assessment of model performance, particularly in challenging aspects such as inter-word and intra-word code-switching.
Titanic Calling: Low Bandwidth Video Conference from the Titanic Wreck
Oct 15, 2024



In this paper, we report on communication experiments conducted in the summer of 2022 during a deep dive to the wreck of the Titanic. Radio transmission is not possible in deep sea water, and communication links rely on sonar signals. Due to the low bandwidth of sonar signals and the need to communicate readable data, text messaging is used in deep-sea missions. In this paper, we report results and experiences from a messaging system that converts speech to text in a submarine, sends text messages to the surface, and reconstructs those messages as synthetic lip-synchronous videos of the speakers. The resulting system was tested during an actual dive to Titanic in the summer of 2022. We achieved an acceptable latency for a system of such complexity as well as good quality. The system demonstration video can be found at the following link: https://youtu.be/C4lyM86-5Ig
End-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.
KIT's Multilingual Speech Translation System for IWSLT 2023
Jun 15, 2023



Many existing speech translation benchmarks focus on native-English speech in high-quality recording conditions, which often do not match the conditions in real-life use-cases. In this paper, we describe our speech translation system for the multilingual track of IWSLT 2023, which evaluates translation quality on scientific conference talks. The test condition features accented input speech and terminology-dense contents. The task requires translation into 10 languages of varying amounts of resources. In absence of training data from the target domain, we use a retrieval-based approach (kNN-MT) for effective adaptation (+0.8 BLEU for speech translation). We also use adapters to easily integrate incremental training data from data augmentation, and show that it matches the performance of re-training. We observe that cascaded systems are more easily adaptable towards specific target domains, due to their separate modules. Our cascaded speech system substantially outperforms its end-to-end counterpart on scientific talk translation, although their performance remains similar on TED talks.
Language-agnostic Code-Switching in End-To-End Speech Recognition
Oct 17, 2022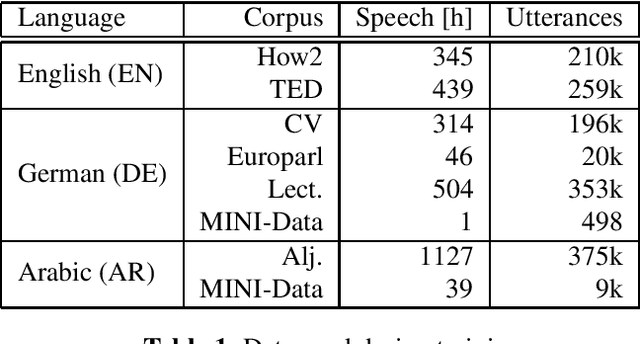
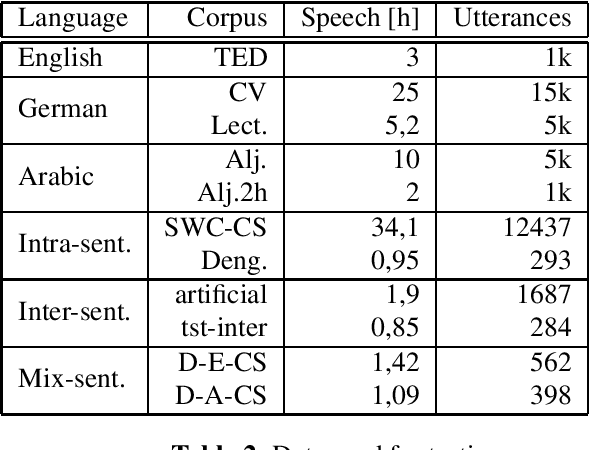
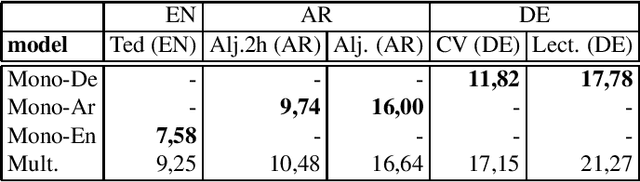
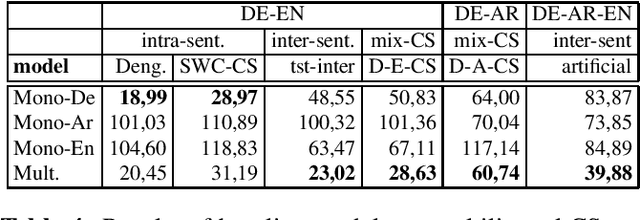
Code-Switching (CS) is referred to the phenomenon of alternately using words and phrases from different languages. While today's neural end-to-end (E2E) models deliver state-of-the-art performances on the task of automatic speech recognition (ASR) it is commonly known that these systems are very data-intensive. However, there is only a few transcribed and aligned CS speech available. To overcome this problem and train multilingual systems which can transcribe CS speech, we propose a simple yet effective data augmentation in which audio and corresponding labels of different source languages are concatenated. By using this training data, our E2E model improves on transcribing CS speech and improves performance over the multilingual model, as well. The results show that this augmentation technique can even improve the model's performance on inter-sentential language switches not seen during training by 5,03\% WER.
Code-Switching without Switching: Language Agnostic End-to-End Speech Translation
Oct 04, 2022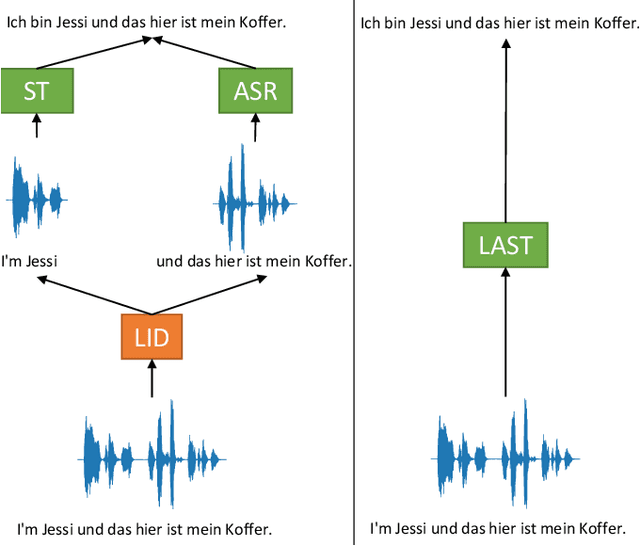
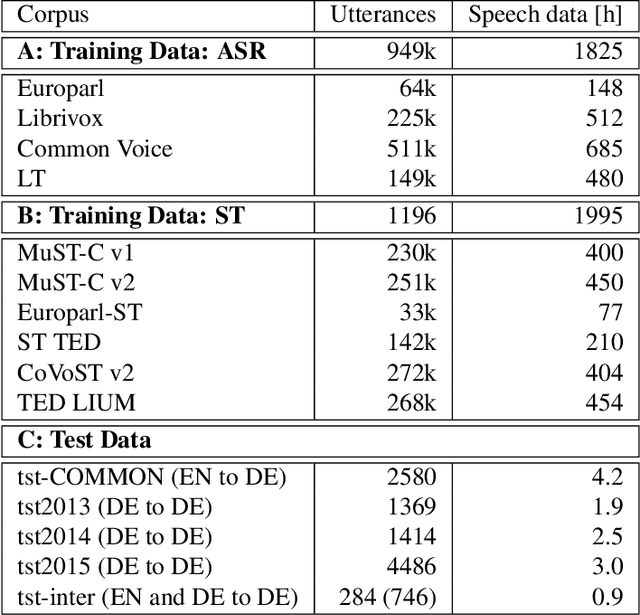
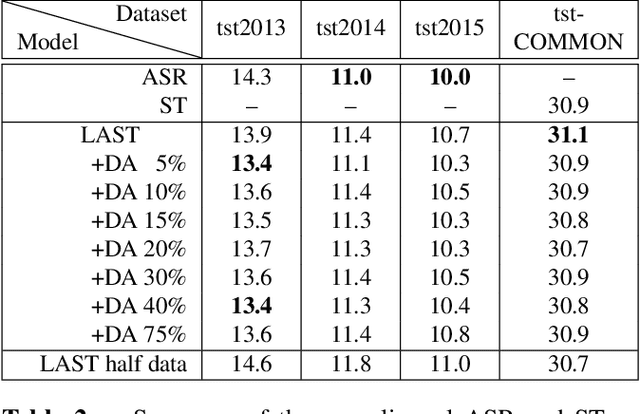
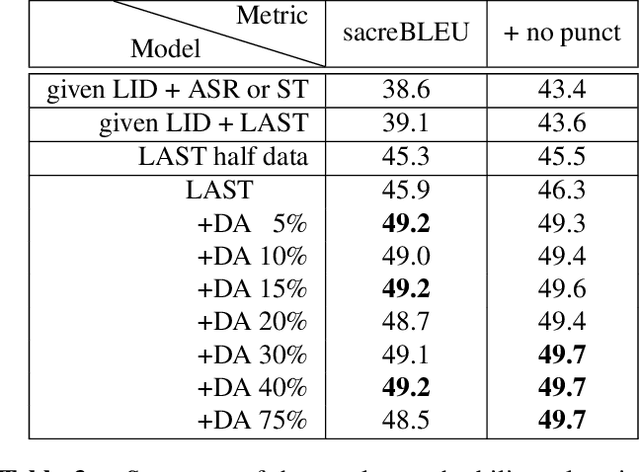
We propose a) a Language Agnostic end-to-end Speech Translation model (LAST), and b) a data augmentation strategy to increase code-switching (CS) performance. With increasing globalization, multiple languages are increasingly used interchangeably during fluent speech. Such CS complicates traditional speech recognition and translation, as we must recognize which language was spoken first and then apply a language-dependent recognizer and subsequent translation component to generate the desired target language output. Such a pipeline introduces latency and errors. In this paper, we eliminate the need for that, by treating speech recognition and translation as one unified end-to-end speech translation problem. By training LAST with both input languages, we decode speech into one target language, regardless of the input language. LAST delivers comparable recognition and speech translation accuracy in monolingual usage, while reducing latency and error rate considerably when CS is observed.