 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-Free Audio-driven Talking Face Generation for Enhanced Visual Quality and Identity Preservation
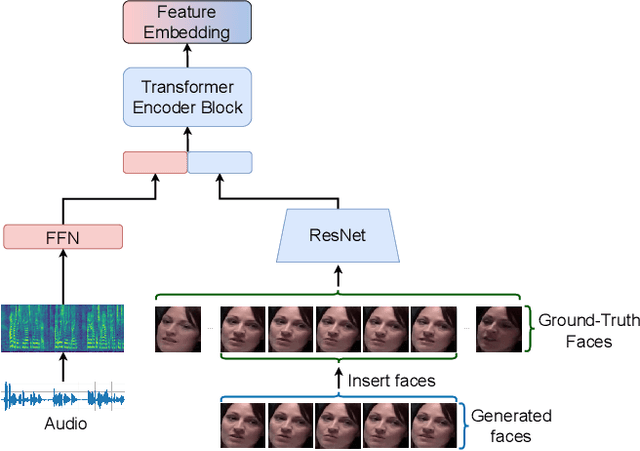
Jul 28, 2025Audio-Driven Talking Face Generation aims at generating realistic videos of talking faces, focusing on accurate audio-lip synchronization without deteriorating any identity-related visual details. Recent state-of-the-art methods are based on inpainting, meaning that the lower half of the input face is masked, and the model fills the masked region by generating lips aligned with the given audio. Hence, to preserve identity-related visual details from the lower half, these approaches additionally require an unmasked identity reference image randomly selected from the same video. However, this common masking strategy suffers from (1) information loss in the input faces, significantly affecting the networks' ability to preserve visual quality and identity details, (2) variation between identity reference and input image degrading reconstruction performance, and (3) the identity reference negatively impacting the model, causing unintended copying of elements unaligned with the audio. To address these issues, we propose a mask-free talking face generation approach while maintaining the 2D-based face editing task. Instead of masking the lower half, we transform the input images to have closed mouths, using a two-step landmark-based approach trained in an unpaired manner. Subsequently, we provide these edited but unmasked faces to a lip adaptation model alongside the audio to generate appropriate lip movements. Thus, our approach needs neither masked input images nor identity reference images. We conduct experiments on the benchmark LRS2 and HDTF datasets and perform various ablation studies to validate our contributions.
PIER: A Novel Metric for Evaluating What Matters in Code-Switching
Jan 16, 2025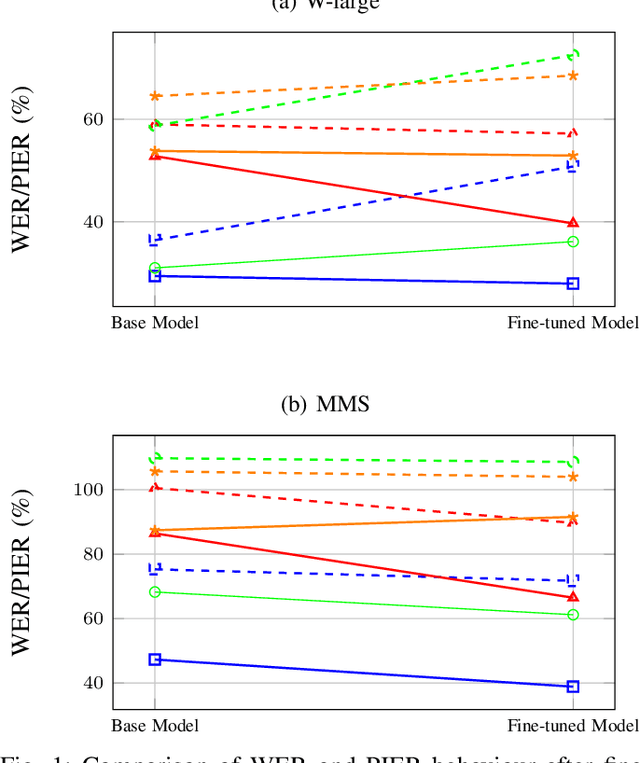
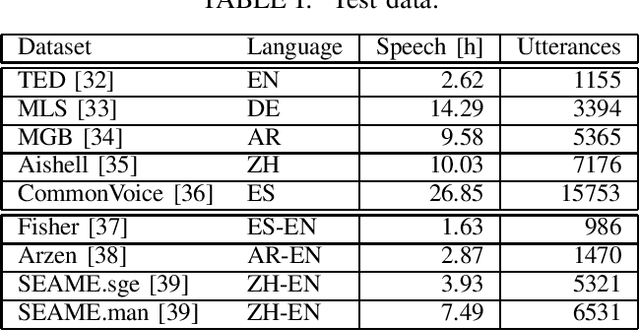
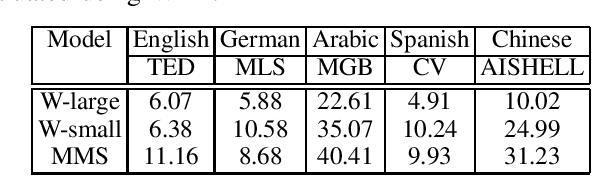
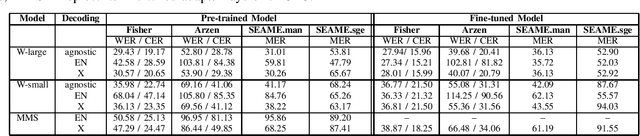
Code-switching, the alternation of languages within a single discourse, presents a significant challenge for Automatic Speech Recognition. Despite the unique nature of the task, performance is commonly measured with established metrics such as Word-Error-Rate (WER). However, in this paper, we question whether these general metrics accurately assess performance on code-switching. Specifically, using both Connectionist-Temporal-Classification and Encoder-Decoder models, we show fine-tuning on non-code-switched data from both matrix and embedded language improves classical metrics on code-switching test sets, although actual code-switched words worsen (as expected). Therefore, we propose Point-of-Interest Error Rate (PIER), a variant of WER that focuses only on specific words of interest. We instantiate PIER on code-switched utterances and show that this more accurately describes the code-switching performance, showing huge room for improvement in future work. This focused evaluation allows for a more precise assessment of model performance, particularly in challenging aspects such as inter-word and intra-word code-switching.
Episodic Memory Verbalization using Hierarchical Representations of Life-Long Robot Experience
Sep 26, 2024Verbalization of robot experience, i.e., summarization of and question answering about a robot's past, is a crucial ability for improving human-robot interaction. Previous works applied rule-based systems or fine-tuned deep models to verbalize short (several-minute-long) streams of episodic data, limiting generalization and transferability. In our work, we apply large pretrained models to tackle this task with zero or few examples, and specifically focus on verbalizing life-long experiences. For this, we derive a tree-like data structure from episodic memory (EM), with lower levels representing raw perception and proprioception data, and higher levels abstracting events to natural language concepts. Given such a hierarchical representation built from the experience stream, we apply a large language model as an agent to interactively search the EM given a user's query, dynamically expanding (initially collapsed) tree nodes to find the relevant information. The approach keeps computational costs low even when scaling to months of robot experience data. We evaluate our method on simulated household robot data, human egocentric videos, and real-world robot recordings, demonstrating its flexibility and scalability.
SciEx: Benchmarking Large Language Models on Scientific Exams with Human Expert Grading and Automatic Grading
Jun 14, 2024
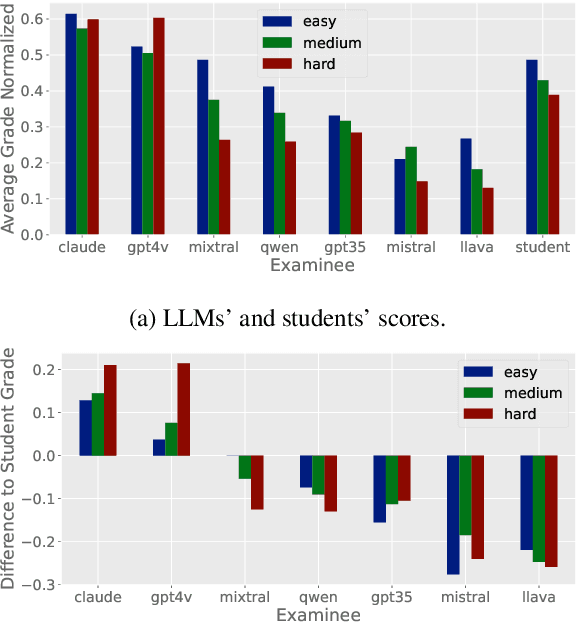

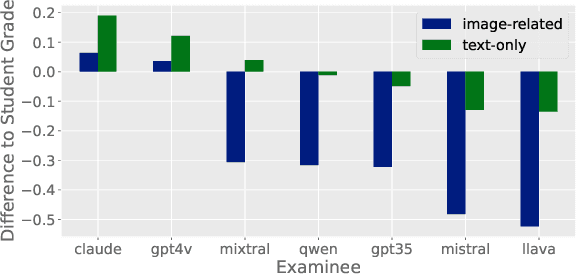
With the rapid development of Large Language Models (LLMs), it is crucial to have benchmarks which can evaluate the ability of LLMs on different domains. One common use of LLMs is performing tasks on scientific topics, such as writing algorithms, querying databases or giving mathematical proofs. Inspired by the way university students are evaluated on such tasks, in this paper, we propose SciEx - a benchmark consisting of university computer science exam questions, to evaluate LLMs ability on solving scientific tasks. SciEx is (1) multilingual, containing both English and German exams, and (2) multi-modal, containing questions that involve images, and (3) contains various types of freeform questions with different difficulty levels, due to the nature of university exams. We evaluate the performance of various state-of-the-art LLMs on our new benchmark. Since SciEx questions are freeform, it is not straightforward to evaluate LLM performance. Therefore, we provide human expert grading of the LLM outputs on SciEx. We show that the free-form exams in SciEx remain challenging for the current LLMs, where the best LLM only achieves 59.4\% exam grade on average. We also provide detailed comparisons between LLM performance and student performance on SciEx. To enable future evaluation of new LLMs, we propose using LLM-as-a-judge to grade the LLM answers on SciEx. Our experiments show that, although they do not perform perfectly on solving the exams, LLMs are decent as graders, achieving 0.948 Pearson correlation with expert grading.
Audio-Visual Speech Representation Expert for Enhanced Talking Face Video Generation and Evaluation
May 07, 2024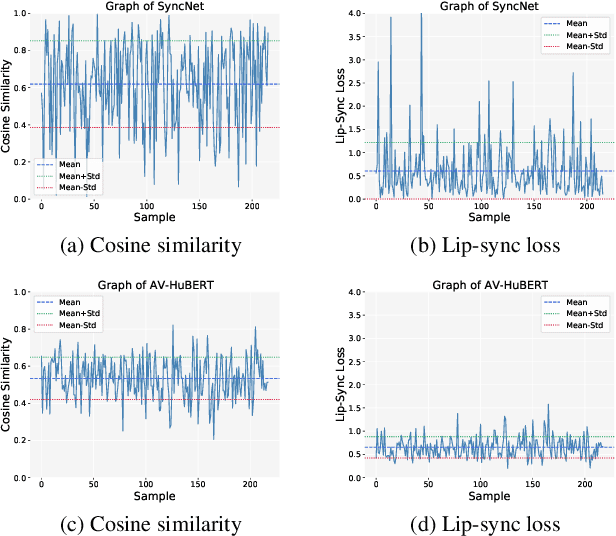
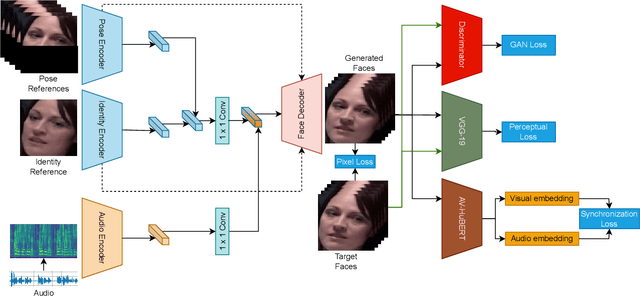

In the task of talking face generation, the objective is to generate a face video with lips synchronized to the corresponding audio while preserving visual details and identity information. Current methods face the challenge of learning accurate lip synchronization while avoiding detrimental effects on visual quality, as well as robustly evaluating such synchronization. To tackle these problems, we propose utilizing an audio-visual speech representation expert (AV-HuBERT) for calculating lip synchronization loss during training. Moreover, leveraging AV-HuBERT's features, we introduce three novel lip synchronization evaluation metrics, aiming to provide a comprehensive assessment of lip synchronization performance. Experimental results, along with a detailed ablation study, demonstrate the effectiveness of our approach and the utility of the proposed evaluation metrics.
Incremental Learning of Humanoid Robot Behavior from Natural Interaction and Large Language Models
Sep 08, 2023



Natural-language dialog is key for intuitive human-robot interaction. It can be used not only to express humans' intents, but also to communicate instructions for improvement if a robot does not understand a command correctly. Of great importance is to endow robots with the ability to learn from such interaction experience in an incremental way to allow them to improve their behaviors or avoid mistakes in the future. In this paper, we propose a system to achieve incremental learning of complex behavior from natural interaction, and demonstrate its implementation on a humanoid robot. Building on recent advances, we present a system that deploys Large Language Models (LLMs) for high-level orchestration of the robot's behavior, based on the idea of enabling the LLM to generate Python statements in an interactive console to invoke both robot perception and action. The interaction loop is closed by feeding back human instructions, environment observations, and execution results to the LLM, thus informing the generation of the next statement. Specifically, we introduce incremental prompt learning, which enables the system to interactively learn from its mistakes. For that purpose, the LLM can call another LLM responsible for code-level improvements of the current interaction based on human feedback. The improved interaction is then saved in the robot's memory, and thus retrieved on similar requests. We integrate the system in the robot cognitive architecture of the humanoid robot ARMAR-6 and evaluate our methods both quantitatively (in simulation) and qualitatively (in simulation and real-world) by demonstrating generalized incrementally-learned knowledge.
Plug the Leaks: Advancing Audio-driven Talking Face Generation by Preventing Unintended Information Flow
Jul 18, 2023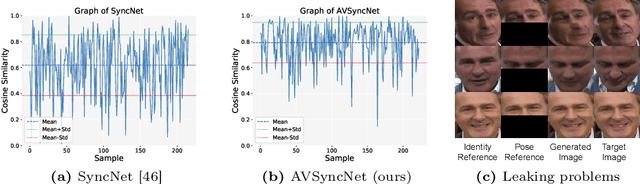
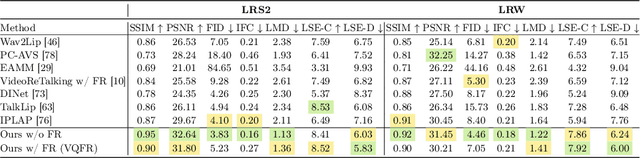


Audio-driven talking face generation is the task of creating a lip-synchronized, realistic face video from given audio and reference frames. This involves two major challenges: overall visual quality of generated images on the one hand, and audio-visual synchronization of the mouth part on the other hand. In this paper, we start by identifying several problematic aspects of synchronization methods in recent audio-driven talking face generation approaches. Specifically, this involves unintended flow of lip and pose information from the reference to the generated image, as well as instabilities during model training. Subsequently, we propose various techniques for obviating these issues: First, a silent-lip reference image generator prevents leaking of lips from the reference to the generated image. Second, an adaptive triplet loss handles the pose leaking problem. Finally, we propose a stabilized formulation of synchronization loss, circumventing aforementioned training instabilities while additionally further alleviating the lip leaking issue. Combining the individual improvements, we present state-of-the art performance on LRS2 and LRW in both synchronization and visual quality. We further validate our design in various ablation experiments, confirming the individual contributions as well as their complementary effects.