 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge50 questions on Active Assisted Living technologies. Global edition
Oct 22, 2024This booklet on Active Assisted Living (AAL) technologies has been created as part of the GoodBrother COST Action, which has run from 2020 to 2024. COST Actions are European research programs that promote collaboration across borders, uniting researchers, professionals, and institutions to address key societal challenges. GoodBrother focused on ethical and privacy concerns surrounding video and audio monitoring in care settings. The aim was to ensure that while AAL technologies help older adults and vulnerable individuals, their privacy and data protection rights remain a top priority. This booklet is designed to guide you through the role that AAL technologies play in improving the quality of life for older adults, caregivers, and people with disabilities. AAL technologies offer tools for those facing cognitive or physical challenges. They can enhance independence, assist with daily routines, and promote a safer living environment. However, the rise of these technologies also brings important questions about data protection and user autonomy. This resource is intended for a wide audience, including end users, caregivers, healthcare professionals, and policymakers. It provides practical guidance on integrating AAL technologies into care settings while safeguarding privacy and ensuring ethical use. The insights offered here aim to empower users and caregivers to make informed choices that enhance both the quality of care and respect for personal autonomy.
Plug the Leaks: Advancing Audio-driven Talking Face Generation by Preventing Unintended Information Flow
Jul 18, 2023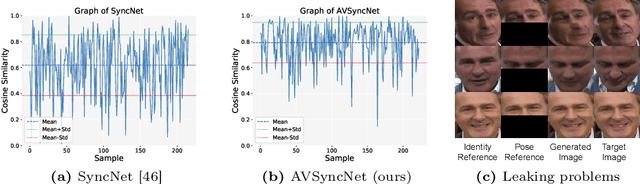
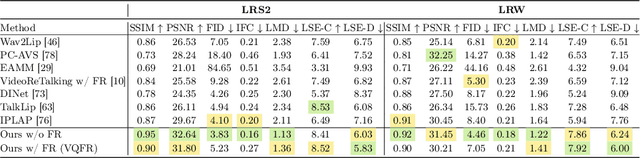


Audio-driven talking face generation is the task of creating a lip-synchronized, realistic face video from given audio and reference frames. This involves two major challenges: overall visual quality of generated images on the one hand, and audio-visual synchronization of the mouth part on the other hand. In this paper, we start by identifying several problematic aspects of synchronization methods in recent audio-driven talking face generation approaches. Specifically, this involves unintended flow of lip and pose information from the reference to the generated image, as well as instabilities during model training. Subsequently, we propose various techniques for obviating these issues: First, a silent-lip reference image generator prevents leaking of lips from the reference to the generated image. Second, an adaptive triplet loss handles the pose leaking problem. Finally, we propose a stabilized formulation of synchronization loss, circumventing aforementioned training instabilities while additionally further alleviating the lip leaking issue. Combining the individual improvements, we present state-of-the art performance on LRS2 and LRW in both synchronization and visual quality. We further validate our design in various ablation experiments, confirming the individual contributions as well as their complementary effects.
State of the Art of Audio- and Video-Based Solutions for AAL
Jul 05, 2022The report illustrates the state of the art of the most successful AAL applications and functions based on audio and video data, namely (i) lifelogging and self-monitoring, (ii) remote monitoring of vital signs, (iii) emotional state recognition, (iv) food intake monitoring, activity and behaviour recognition, (v) activity and personal assistance, (vi) gesture recognition, (vii) fall detection and prevention, (viii) mobility assessment and frailty recognition, and (ix) cognitive and motor rehabilitation. For these application scenarios, the report illustrates the state of play in terms of scientific advances, available products and research project. The open challenges are also highlighted.
MOCCA: Multi-Layer One-Class Classification for Anomaly Detection
Dec 09, 2020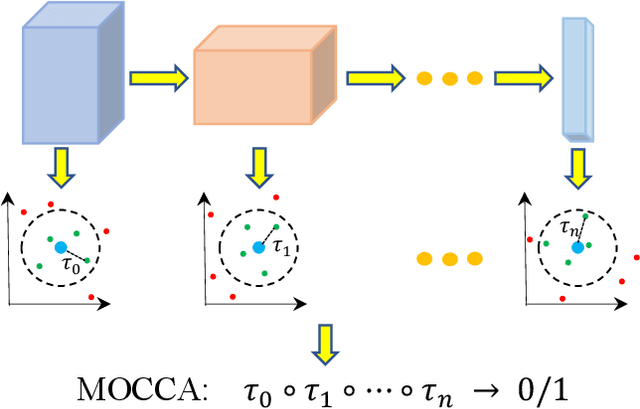
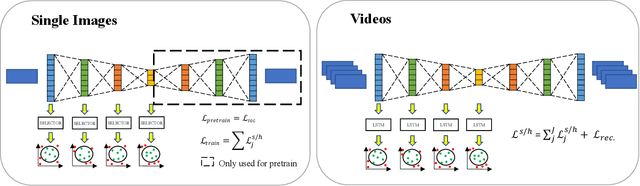
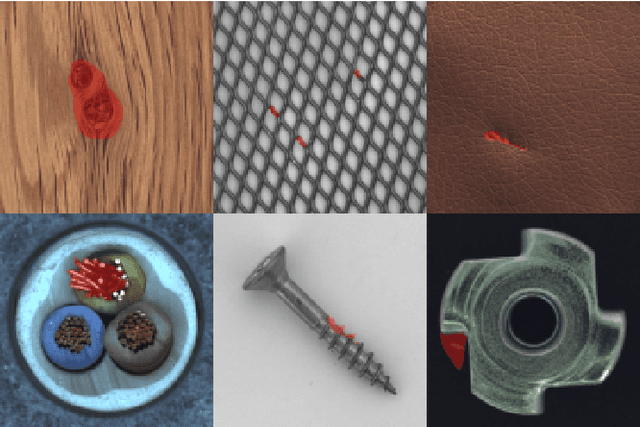

Anomalies are ubiquitous in all scientific fields and can express an unexpected event due to incomplete knowledge about the data distribution or an unknown process that suddenly comes into play and distorts the observations. Due to such events' rarity, it is common to train deep learning models on "normal", i.e. non-anomalous, datasets only, thus letting the neural network to model the distribution beneath the input data. In this context, we propose our deep learning approach to the anomaly detection problem named Multi-LayerOne-Class Classification (MOCCA). We explicitly leverage the piece-wise nature of deep neural networks by exploiting information extracted at different depths to detect abnormal data instances. We show how combining the representations extracted from multiple layers of a model leads to higher discrimination performance than typical approaches proposed in the literature that are based neural networks' final output only. We propose to train the model by minimizing the $L_2$ distance between the input representation and a reference point, the anomaly-free training data centroid, at each considered layer. We conduct extensive experiments on publicly available datasets for anomaly detection, namely CIFAR10, MVTec AD, and ShanghaiTech, considering both the single-image and video-based scenarios. We show that our method reaches superior performances compared to the state-of-the-art approaches available in the literature. Moreover, we provide a model analysis to give insight on how our approach works.
Benefitting from Bicubically Down-Sampled Images for Learning Real-World Image Super-Resolution
Jul 06, 2020

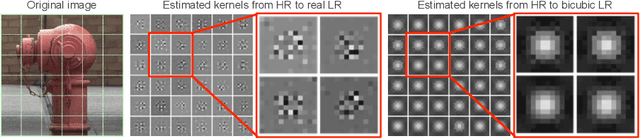
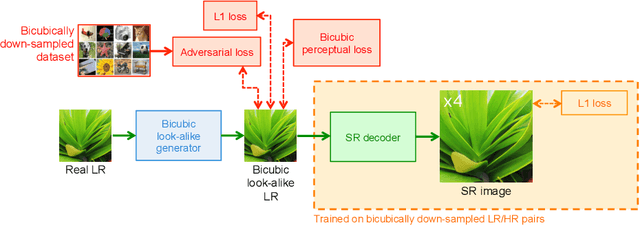
Super-resolution (SR) has traditionally been based on pairs of high-resolution images (HR) and their low-resolution (LR) counterparts obtained artificially with bicubic downsampling. However, in real-world SR, there is a large variety of realistic image degradations and analytically modeling these realistic degradations can prove quite difficult. In this work, we propose to handle real-world SR by splitting this ill-posed problem into two comparatively more well-posed steps. First, we train a network to transform real LR images to the space of bicubically downsampled images in a supervised manner, by using both real LR/HR pairs and synthetic pairs. Second, we take a generic SR network trained on bicubically downsampled images to super-resolve the transformed LR image. The first step of the pipeline addresses the problem by registering the large variety of degraded images to a common, well understood space of images. The second step then leverages the already impressive performance of SR on bicubically downsampled images, sidestepping the issues of end-to-end training on datasets with many different image degradations. We demonstrate the effectiveness of our proposed method by comparing it to recent methods in real-world SR and show that our proposed approach outperforms the state-of-the-art works in terms of both qualitative and quantitative results, as well as results of an extensive user study conducted on several real image datasets.
SROBB: Targeted Perceptual Loss for Single Image Super-Resolution
Aug 20, 2019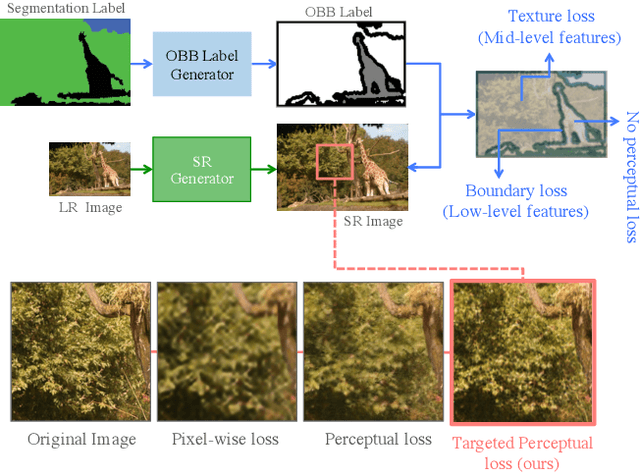
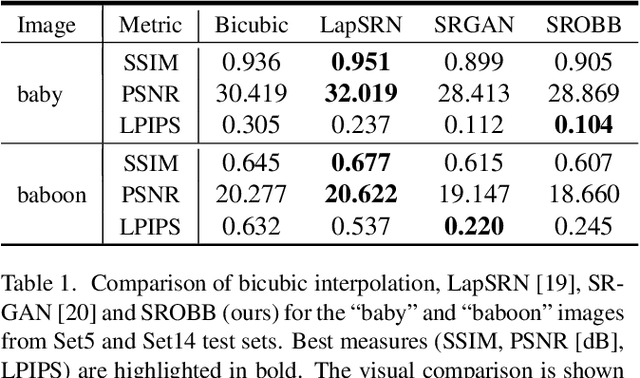

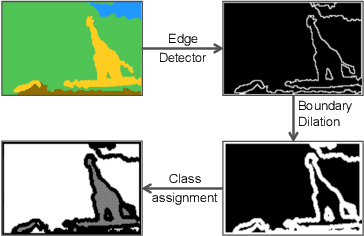
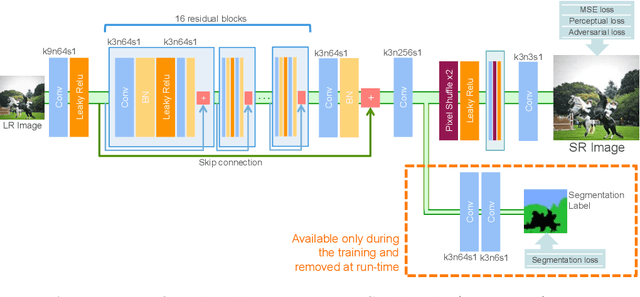
By benefiting from perceptual losses, recent studies have improved significantly the performance of the super-resolution task, where a high-resolution image is resolved from its low-resolution counterpart. Although such objective functions generate near-photorealistic results, their capability is limited, since they estimate the reconstruction error for an entire image in the same way, without considering any semantic information. In this paper, we propose a novel method to benefit from perceptual loss in a more objective way. We optimize a deep network-based decoder with a targeted objective function that penalizes images at different semantic levels using the corresponding terms. In particular, the proposed method leverages our proposed OBB (Object, Background and Boundary) labels, generated from segmentation labels, to estimate a suitable perceptual loss for boundaries, while considering texture similarity for backgrounds. We show that our proposed approach results in more realistic textures and sharper edges, and outperforms other state-of-the-art algorithms in terms of both qualitative results on standard benchmarks and results of extensive user studies.
Benefiting from Multitask Learning to Improve Single Image Super-Resolution
Jul 29, 2019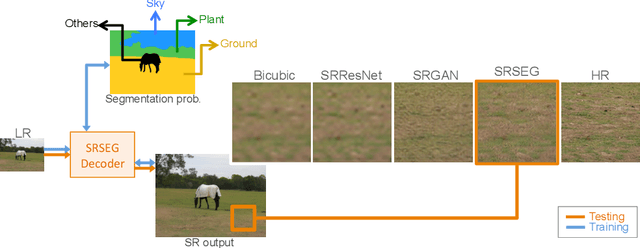
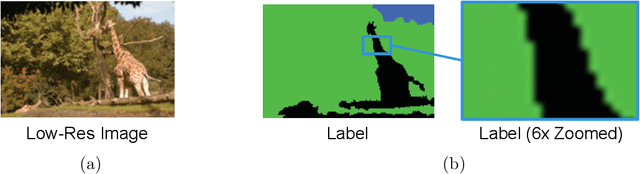
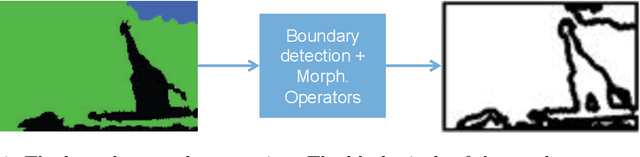
Despite significant progress toward super resolving more realistic images by deeper convolutional neural networks (CNNs), reconstructing fine and natural textures still remains a challenging problem. Recent works on single image super resolution (SISR) are mostly based on optimizing pixel and content wise similarity between recovered and high-resolution (HR) images and do not benefit from recognizability of semantic classes. In this paper, we introduce a novel approach using categorical information to tackle the SISR problem; we present a decoder architecture able to extract and use semantic information to super-resolve a given image by using multitask learning, simultaneously for image super-resolution and semantic segmentation. To explore categorical information during training, the proposed decoder only employs one shared deep network for two task-specific output layers. At run-time only layers resulting HR image are used and no segmentation label is required. Extensive perceptual experiments and a user study on images randomly selected from COCO-Stuff dataset demonstrate the effectiveness of our proposed method and it outperforms the state-of-the-art methods.
FUNSD: A Dataset for Form Understanding in Noisy Scanned Documents
May 27, 2019


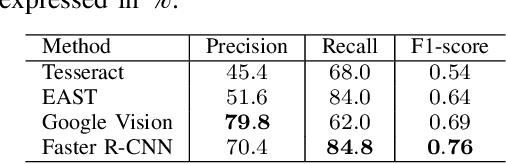
In this paper, we present a new dataset for Form Understanding in Noisy Scanned Documents (FUNSD). Form Understanding (FoUn) aims at extracting and structuring the textual content of forms. The dataset comprises 200 fully annotated real scanned forms. The documents are noisy and exhibit large variabilities in their representation making FoUn a challenging task. The proposed dataset can be used for various tasks including text detection, optical character recognition (OCR), spatial layout analysis and entity labeling/linking. To the best of our knowledge this is the first publicly available dataset with comprehensive annotations addressing the FoUn task. We also present a set of baselines and introduce metrics to evaluate performance on the FUNSD dataset. The FUNSD dataset can be downloaded at https://guillaumejaume.github. io/FUNSD/.
Using Photorealistic Face Synthesis and Domain Adaptation to Improve Facial Expression Analysis
May 17, 2019
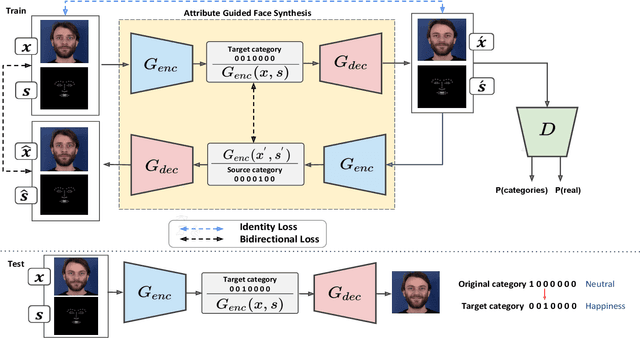


Cross-domain synthesizing realistic faces to learn deep models has attracted increasing attention for facial expression analysis as it helps to improve the performance of expression recognition accuracy despite having small number of real training images. However, learning from synthetic face images can be problematic due to the distribution discrepancy between low-quality synthetic images and real face images and may not achieve the desired performance when the learned model applies to real world scenarios. To this end, we propose a new attribute guided face image synthesis to perform a translation between multiple image domains using a single model. In addition, we adopt the proposed model to learn from synthetic faces by matching the feature distributions between different domains while preserving each domain's characteristics. We evaluate the effectiveness of the proposed approach on several face datasets on generating realistic face images. We demonstrate that the expression recognition performance can be enhanced by benefiting from our face synthesis model. Moreover, we also conduct experiments on a near-infrared dataset containing facial expression videos of drivers to assess the performance using in-the-wild data for driver emotion recognition.
Image-Level Attentional Context Modeling Using Nested-Graph Neural Networks
Nov 12, 2018


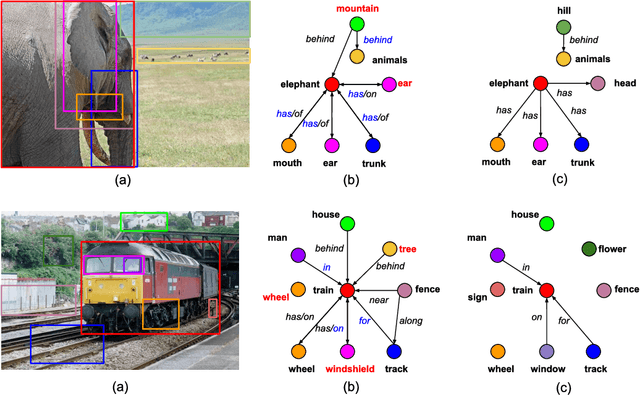
We introduce a new scene graph generation method called image-level attentional context modeling (ILAC). Our model includes an attentional graph network that effectively propagates contextual information across the graph using image-level features. Whereas previous works use an object-centric context, we build an image-level context agent to encode the scene properties. The proposed method comprises a single-stream network that iteratively refines the scene graph with a nested graph neural network. We demonstrate that our approach achieves competitive performance with the state-of-the-art for scene graph generation on the Visual Genome dataset, while requiring fewer parameters than other methods. We also show that ILAC can improve regular object detectors by incorporating relational image-level information.