 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Generative Style Transfer for One-Shot Medical Image Segmentation
Oct 05, 2021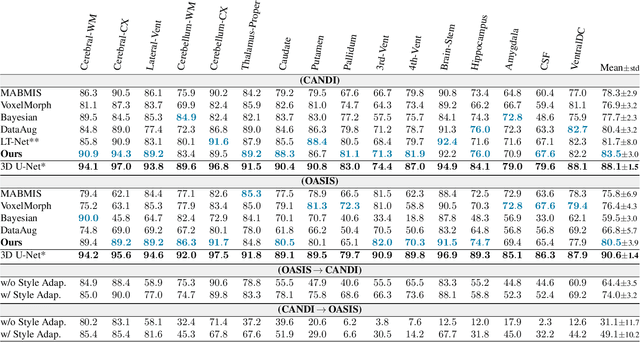
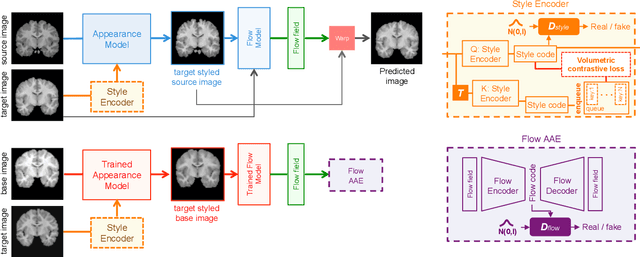
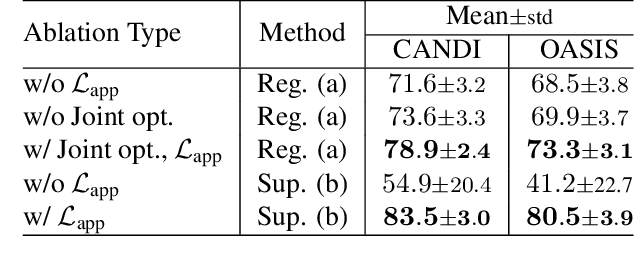
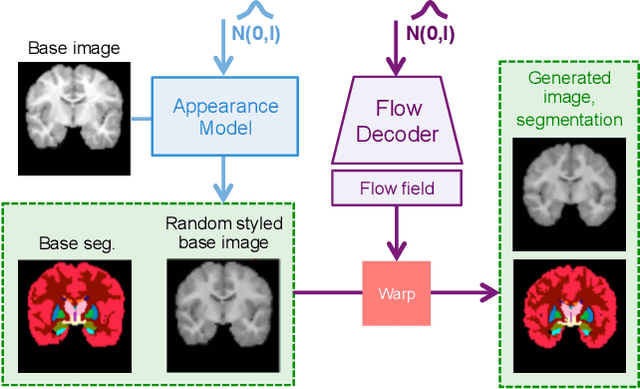
In medical image segmentation, supervised deep networks' success comes at the cost of requiring abundant labeled data. While asking domain experts to annotate only one or a few of the cohort's images is feasible, annotating all available images is impractical. This issue is further exacerbated when pre-trained deep networks are exposed to a new image dataset from an unfamiliar distribution. Using available open-source data for ad-hoc transfer learning or hand-tuned techniques for data augmentation only provides suboptimal solutions. Motivated by atlas-based segmentation, we propose a novel volumetric self-supervised learning for data augmentation capable of synthesizing volumetric image-segmentation pairs via learning transformations from a single labeled atlas to the unlabeled data. Our work's central tenet benefits from a combined view of one-shot generative learning and the proposed self-supervised training strategy that cluster unlabeled volumetric images with similar styles together. Unlike previous methods, our method does not require input volumes at inference time to synthesize new images. Instead, it can generate diversified volumetric image-segmentation pairs from a prior distribution given a single or multi-site dataset. Augmented data generated by our method used to train the segmentation network provide significant improvements over state-of-the-art deep one-shot learning methods on the task of brain MRI segmentation. Ablation studies further exemplified that the proposed appearance model and joint training are crucial to synthesize realistic examples compared to existing medical registration methods. The code, data, and models are available at https://github.com/devavratTomar/SST.
Test-Time Adaptation for Super-Resolution: You Only Need to Overfit on a Few More Images
Apr 06, 2021
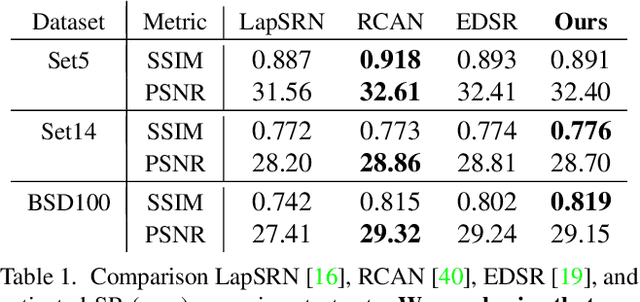
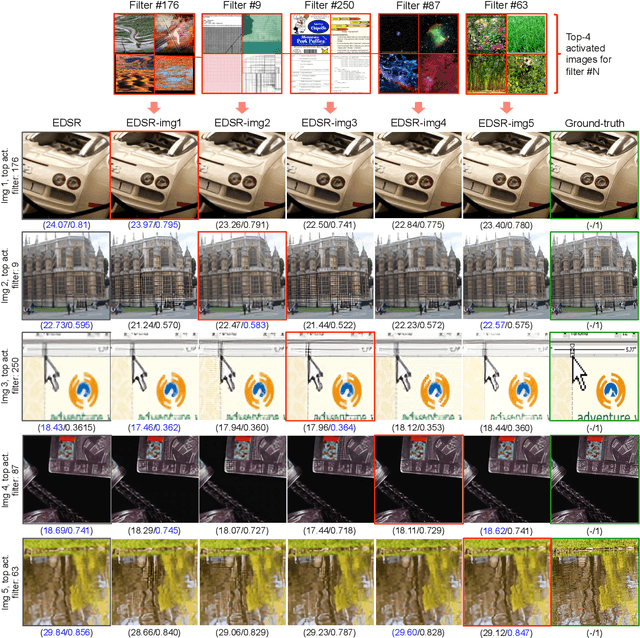
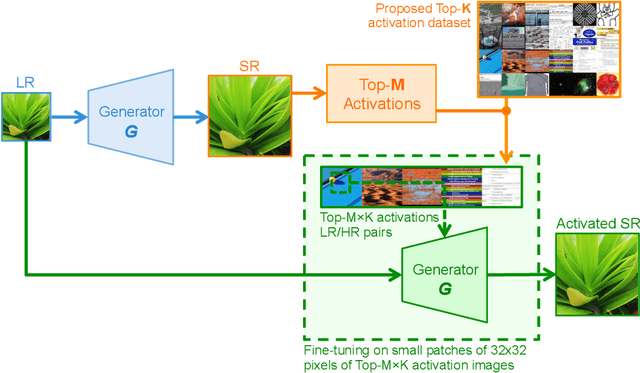
Existing reference (RF)-based super-resolution (SR) models try to improve perceptual quality in SR under the assumption of the availability of high-resolution RF images paired with low-resolution (LR) inputs at testing. As the RF images should be similar in terms of content, colors, contrast, etc. to the test image, this hinders the applicability in a real scenario. Other approaches to increase the perceptual quality of images, including perceptual loss and adversarial losses, tend to dramatically decrease fidelity to the ground-truth through significant decreases in PSNR/SSIM. Addressing both issues, we propose a simple yet universal approach to improve the perceptual quality of the HR prediction from a pre-trained SR network on a given LR input by further fine-tuning the SR network on a subset of images from the training dataset with similar patterns of activation as the initial HR prediction, with respect to the filters of a feature extractor. In particular, we show the effects of fine-tuning on these images in terms of the perceptual quality and PSNR/SSIM values. Contrary to perceptually driven approaches, we demonstrate that the fine-tuned network produces a HR prediction with both greater perceptual quality and minimal changes to the PSNR/SSIM with respect to the initial HR prediction. Further, we present novel numerical experiments concerning the filters of SR networks, where we show through filter correlation, that the filters of the fine-tuned network from our method are closer to "ideal" filters, than those of the baseline network or a network fine-tuned on random images.
Benefitting from Bicubically Down-Sampled Images for Learning Real-World Image Super-Resolution
Jul 06, 2020

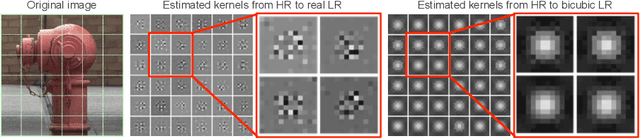
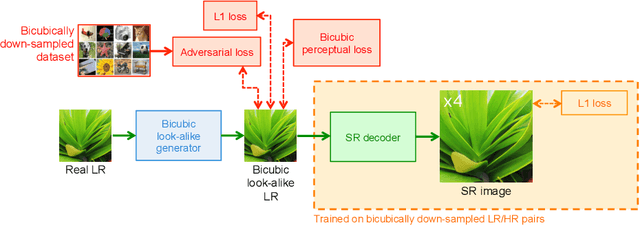
Super-resolution (SR) has traditionally been based on pairs of high-resolution images (HR) and their low-resolution (LR) counterparts obtained artificially with bicubic downsampling. However, in real-world SR, there is a large variety of realistic image degradations and analytically modeling these realistic degradations can prove quite difficult. In this work, we propose to handle real-world SR by splitting this ill-posed problem into two comparatively more well-posed steps. First, we train a network to transform real LR images to the space of bicubically downsampled images in a supervised manner, by using both real LR/HR pairs and synthetic pairs. Second, we take a generic SR network trained on bicubically downsampled images to super-resolve the transformed LR image. The first step of the pipeline addresses the problem by registering the large variety of degraded images to a common, well understood space of images. The second step then leverages the already impressive performance of SR on bicubically downsampled images, sidestepping the issues of end-to-end training on datasets with many different image degradations. We demonstrate the effectiveness of our proposed method by comparing it to recent methods in real-world SR and show that our proposed approach outperforms the state-of-the-art works in terms of both qualitative and quantitative results, as well as results of an extensive user study conducted on several real image datasets.
SROBB: Targeted Perceptual Loss for Single Image Super-Resolution
Aug 20, 2019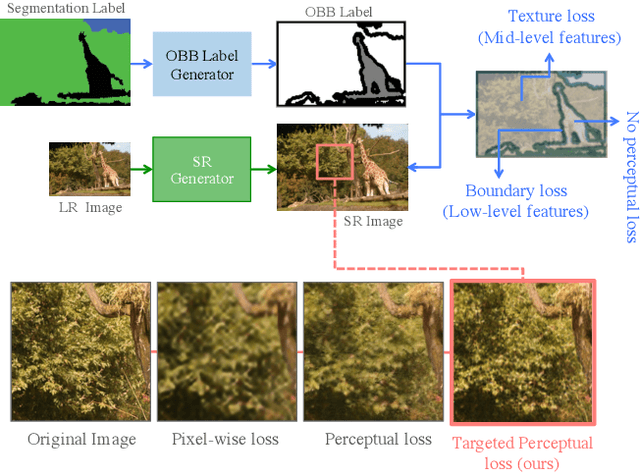
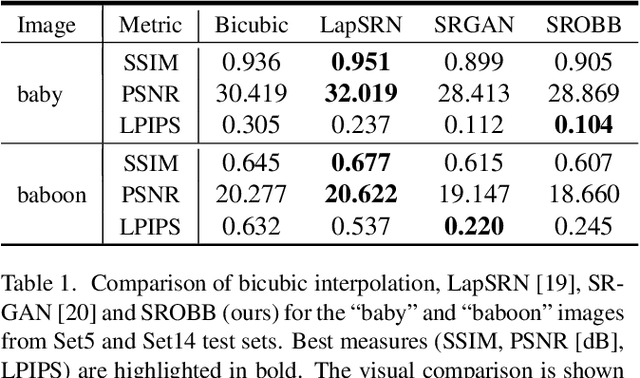

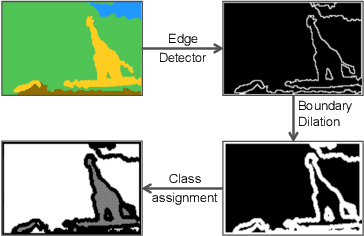
By benefiting from perceptual losses, recent studies have improved significantly the performance of the super-resolution task, where a high-resolution image is resolved from its low-resolution counterpart. Although such objective functions generate near-photorealistic results, their capability is limited, since they estimate the reconstruction error for an entire image in the same way, without considering any semantic information. In this paper, we propose a novel method to benefit from perceptual loss in a more objective way. We optimize a deep network-based decoder with a targeted objective function that penalizes images at different semantic levels using the corresponding terms. In particular, the proposed method leverages our proposed OBB (Object, Background and Boundary) labels, generated from segmentation labels, to estimate a suitable perceptual loss for boundaries, while considering texture similarity for backgrounds. We show that our proposed approach results in more realistic textures and sharper edges, and outperforms other state-of-the-art algorithms in terms of both qualitative results on standard benchmarks and results of extensive user studies.
Benefiting from Multitask Learning to Improve Single Image Super-Resolution
Jul 29, 2019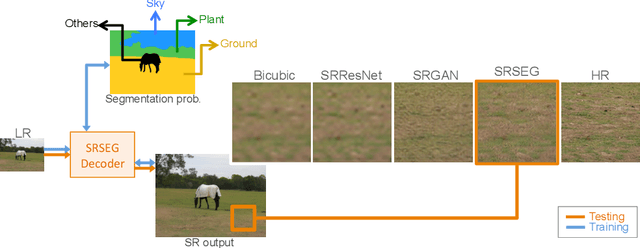
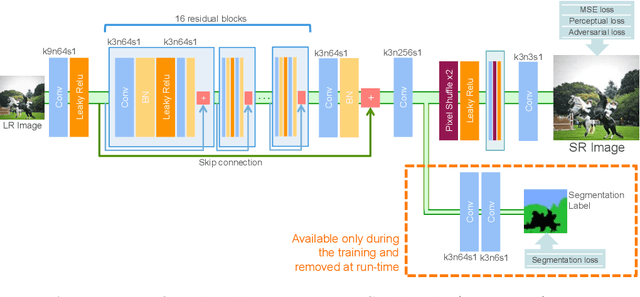
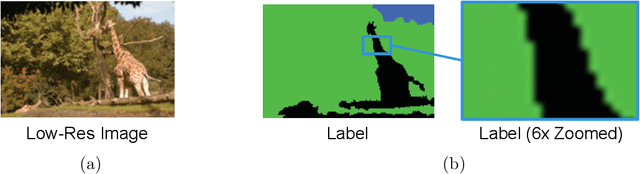
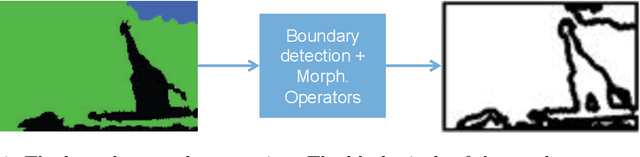
Despite significant progress toward super resolving more realistic images by deeper convolutional neural networks (CNNs), reconstructing fine and natural textures still remains a challenging problem. Recent works on single image super resolution (SISR) are mostly based on optimizing pixel and content wise similarity between recovered and high-resolution (HR) images and do not benefit from recognizability of semantic classes. In this paper, we introduce a novel approach using categorical information to tackle the SISR problem; we present a decoder architecture able to extract and use semantic information to super-resolve a given image by using multitask learning, simultaneously for image super-resolution and semantic segmentation. To explore categorical information during training, the proposed decoder only employs one shared deep network for two task-specific output layers. At run-time only layers resulting HR image are used and no segmentation label is required. Extensive perceptual experiments and a user study on images randomly selected from COCO-Stuff dataset demonstrate the effectiveness of our proposed method and it outperforms the state-of-the-art methods.
Using Photorealistic Face Synthesis and Domain Adaptation to Improve Facial Expression Analysis
May 17, 2019
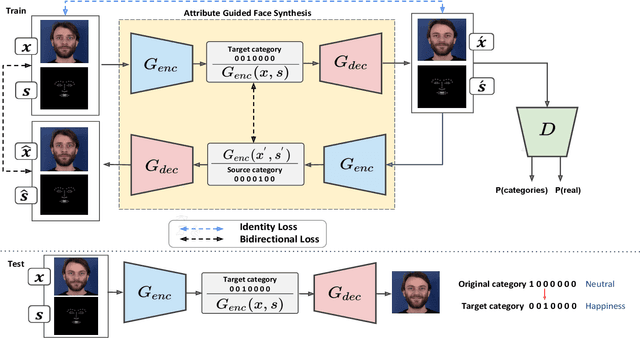


Cross-domain synthesizing realistic faces to learn deep models has attracted increasing attention for facial expression analysis as it helps to improve the performance of expression recognition accuracy despite having small number of real training images. However, learning from synthetic face images can be problematic due to the distribution discrepancy between low-quality synthetic images and real face images and may not achieve the desired performance when the learned model applies to real world scenarios. To this end, we propose a new attribute guided face image synthesis to perform a translation between multiple image domains using a single model. In addition, we adopt the proposed model to learn from synthetic faces by matching the feature distributions between different domains while preserving each domain's characteristics. We evaluate the effectiveness of the proposed approach on several face datasets on generating realistic face images. We demonstrate that the expression recognition performance can be enhanced by benefiting from our face synthesis model. Moreover, we also conduct experiments on a near-infrared dataset containing facial expression videos of drivers to assess the performance using in-the-wild data for driver emotion recognition.
Learn to synthesize and synthesize to learn
May 01, 2019


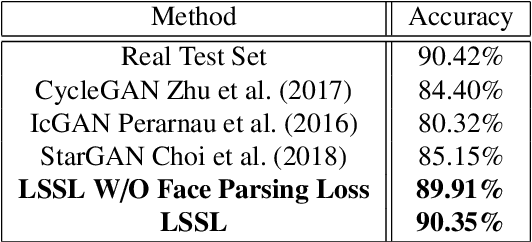
Attribute guided face image synthesis aims to manipulate attributes on a face image. Most existing methods for image-to-image translation can either perform a fixed translation between any two image domains using a single attribute or require training data with the attributes of interest for each subject. Therefore, these methods could only train one specific model for each pair of image domains, which limits their ability in dealing with more than two domains. Another disadvantage of these methods is that they often suffer from the common problem of mode collapse that degrades the quality of the generated images. To overcome these shortcomings, we propose attribute guided face image generation method using a single model, which is capable to synthesize multiple photo-realistic face images conditioned on the attributes of interest. In addition, we adopt the proposed model to increase the realism of the simulated face images while preserving the face characteristics. Compared to existing models, synthetic face images generated by our method present a good photorealistic quality on several face datasets. Finally, we demonstrate that generated facial images can be used for synthetic data augmentation, and improve the performance of the classifier used for facial expression recognition.
A Computer Vision System to Localize and Classify Wastes on the Streets
Oct 31, 2017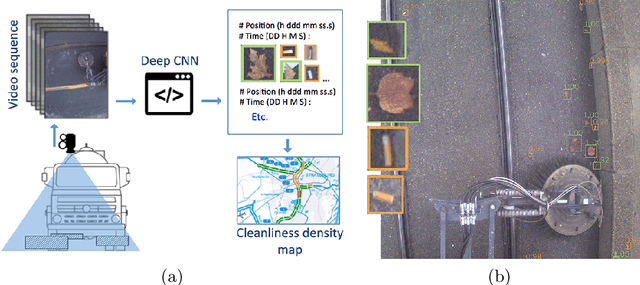
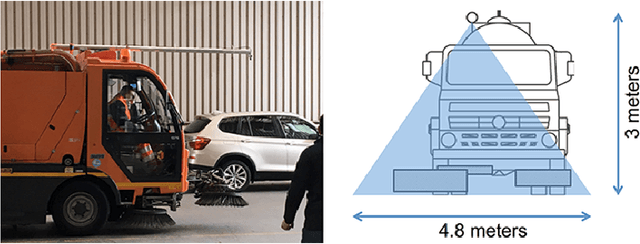

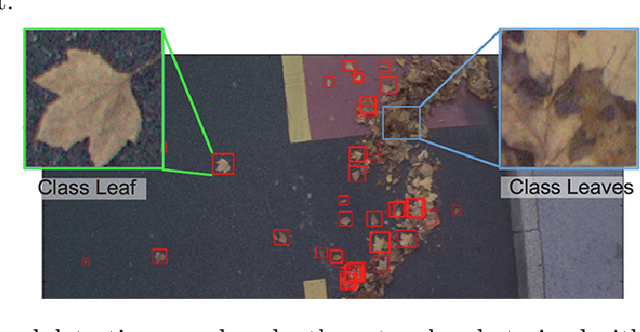
Littering quantification is an important step for improving cleanliness of cities. When human interpretation is too cumbersome or in some cases impossible, an objective index of cleanliness could reduce the littering by awareness actions. In this paper, we present a fully automated computer vision application for littering quantification based on images taken from the streets and sidewalks. We have employed a deep learning based framework to localize and classify different types of wastes. Since there was no waste dataset available, we built our acquisition system mounted on a vehicle. Collected images containing different types of wastes. These images are then annotated for training and benchmarking the developed system. Our results on real case scenarios show accurate detection of littering on variant backgrounds.