 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEELA: A Clinically-Constrained Benchmark for Liver Vessel Segmentation in Computed Tomography Angiography
May 21, 2026Accurate segmentation of hepatic and portal vessels in contrast-enhanced computed tomography angiography (CTA) remains challenging due to complex vascular topology, peripheral visibility limitations, and acquisition-induced ambiguities. While existing public datasets offer valuable benchmarks, few include clinically realistic annotation constraints. We introduce VEELA (Vessel Extraction and Extrication for Liver Analysis), a rigorously curated liver vessel dataset derived from 40 CTA scans inherited from the CHAOS grand-challenge cohort. All vessels were manually delineated slice-by-slice under multi-expert consensus, using a strict visibility-driven annotation policy and avoiding anatomically inferred interpolation. This design explicitly captures anatomical variability and imaging-related uncertainty. As a continuation of the CHAOS challenge, VEELA enables reproducible cross-benchmark evaluation while extending the scope to fine-grained hepatic and portal vessel segmentation. We further establish a standardized benchmarking framework and analyze complementary evaluation metrics, including topology-aware (clDice), overlap-based (IoU), boundary-sensitive (NSD), and geometry-aware (area, length) measures. Our results demonstrate that different metrics capture distinct aspects of vascular integrity, underscoring the necessity of multi-perspective evaluation for clinically meaningful vessel segmentation. VEELA is publicly released to facilitate reproducible research and support the development of robust vascular segmentation methods. Researchers can access the evaluation metrics, dataset, and submission platform at https://www.synapse.org/Synapse:syn65471967.
Improved MambdaBDA Framework for Robust Building Damage Assessment Across Disaster Domains
Mar 04, 2026Reliable post-disaster building damage assessment (BDA) from satellite imagery is hindered by severe class imbalance, background clutter, and domain shift across disaster types and geographies. In this work, we address these problems and explore ways to improve the MambaBDA, the BDA network of ChangeMamba architecture, one of the most successful BDA models. The approach enhances the MambaBDA with three modular components: (i) Focal Loss to mitigate class imbalance damage classification, (ii) lightweight Attention Gates to suppress irrelevant context, and (iii) a compact Alignment Module to spatially warp pre-event features toward post-event content before decoding. We experiment on multiple satellite imagery datasets, including xBD, Pakistan Flooding, Turkey Earthquake, and Ida Hurricane, and conduct in-domain and crossdataset tests. The proposed modular enhancements yield consistent improvements over the baseline model, with 0.8% to 5% performance gains in-domain, and up to 27% on unseen disasters. This indicates that the proposed enhancements are especially beneficial for the generalization capability of the system.
Yolo-Key-6D: Single Stage Monocular 6D Pose Estimation with Keypoint Enhancements
Mar 04, 2026Estimating the 6D pose of objects from a single RGB image is a critical task for robotics and extended reality applications. However, state-of-the-art multi stage methods often suffer from high latency, making them unsuitable for real time use. In this paper, we present Yolo-Key-6D, a novel single stage, end-to-end framework for monocular 6D pose estimation designed for both speed and accuracy. Our approach enhances a YOLO based architecture by integrating an auxiliary head that regresses the 2D projections of an object's 3D bounding box corners. This keypoint detection task significantly improves the network's understanding of 3D geometry. For stable end-to-end training, we directly regress rotation using a continuous 9D representation projected to SO(3) via singular value decomposition. On the LINEMOD and LINEMOD-Occluded benchmarks, YOLO-Key-6D achieves competitive accuracy scores of 96.24% and 69.41%, respectively, with the ADD(-S) 0.1d metric, while proving itself to operate in real time. Our results demonstrate that a carefully designed single stage method can provide a practical and effective balance of performance and efficiency for real world deployment.
Assessing Identity Leakage in Talking Face Generation: Metrics and Evaluation Framework
Nov 05, 2025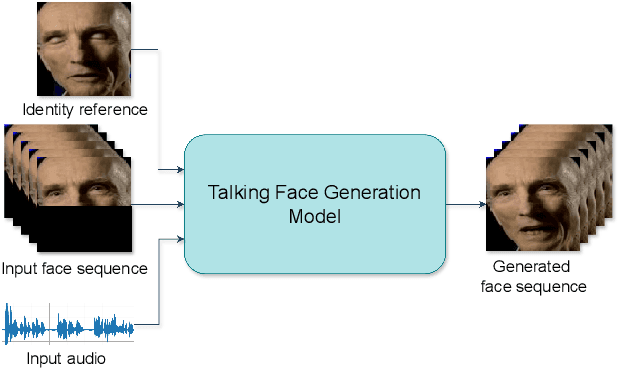


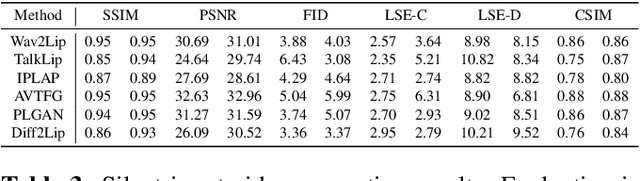
Inpainting-based talking face generation aims to preserve video details such as pose, lighting, and gestures while modifying only lip motion, often using an identity reference image to maintain speaker consistency. However, this mechanism can introduce lip leaking, where generated lips are influenced by the reference image rather than solely by the driving audio. Such leakage is difficult to detect with standard metrics and conventional test setup. To address this, we propose a systematic evaluation methodology to analyze and quantify lip leakage. Our framework employs three complementary test setups: silent-input generation, mismatched audio-video pairing, and matched audio-video synthesis. We also introduce derived metrics including lip-sync discrepancy and silent-audio-based lip-sync scores. In addition, we study how different identity reference selections affect leakage, providing insights into reference design. The proposed methodology is model-agnostic and establishes a more reliable benchmark for future research in talking face generation.
CAPE: A CLIP-Aware Pointing Ensemble of Complementary Heatmap Cues for Embodied Reference Understanding
Jul 29, 2025We address the problem of Embodied Reference Understanding, which involves predicting the object that a person in the scene is referring to through both pointing gesture and language. Accurately identifying the referent requires multimodal understanding: integrating textual instructions, visual pointing, and scene context. However, existing methods often struggle to effectively leverage visual clues for disambiguation. We also observe that, while the referent is often aligned with the head-to-fingertip line, it occasionally aligns more closely with the wrist-to-fingertip line. Therefore, relying on a single line assumption can be overly simplistic and may lead to suboptimal performance. To address this, we propose a dual-model framework, where one model learns from the head-to-fingertip direction and the other from the wrist-to-fingertip direction. We further introduce a Gaussian ray heatmap representation of these lines and use them as input to provide a strong supervisory signal that encourages the model to better attend to pointing cues. To combine the strengths of both models, we present the CLIP-Aware Pointing Ensemble module, which performs a hybrid ensemble based on CLIP features. Additionally, we propose an object center prediction head as an auxiliary task to further enhance referent localization. We validate our approach through extensive experiments and analysis on the benchmark YouRefIt dataset, achieving an improvement of approximately 4 mAP at the 0.25 IoU threshold.
Mask-Free Audio-driven Talking Face Generation for Enhanced Visual Quality and Identity Preservation
Jul 28, 2025Audio-Driven Talking Face Generation aims at generating realistic videos of talking faces, focusing on accurate audio-lip synchronization without deteriorating any identity-related visual details. Recent state-of-the-art methods are based on inpainting, meaning that the lower half of the input face is masked, and the model fills the masked region by generating lips aligned with the given audio. Hence, to preserve identity-related visual details from the lower half, these approaches additionally require an unmasked identity reference image randomly selected from the same video. However, this common masking strategy suffers from (1) information loss in the input faces, significantly affecting the networks' ability to preserve visual quality and identity details, (2) variation between identity reference and input image degrading reconstruction performance, and (3) the identity reference negatively impacting the model, causing unintended copying of elements unaligned with the audio. To address these issues, we propose a mask-free talking face generation approach while maintaining the 2D-based face editing task. Instead of masking the lower half, we transform the input images to have closed mouths, using a two-step landmark-based approach trained in an unpaired manner. Subsequently, we provide these edited but unmasked faces to a lip adaptation model alongside the audio to generate appropriate lip movements. Thus, our approach needs neither masked input images nor identity reference images. We conduct experiments on the benchmark LRS2 and HDTF datasets and perform various ablation studies to validate our contributions.
Facial Attribute Based Text Guided Face Anonymization
May 27, 2025The increasing prevalence of computer vision applications necessitates handling vast amounts of visual data, often containing personal information. While this technology offers significant benefits, it should not compromise privacy. Data privacy regulations emphasize the need for individual consent for processing personal data, hindering researchers' ability to collect high-quality datasets containing the faces of the individuals. This paper presents a deep learning-based face anonymization pipeline to overcome this challenge. Unlike most of the existing methods, our method leverages recent advancements in diffusion-based inpainting models, eliminating the need for training Generative Adversarial Networks. The pipeline employs a three-stage approach: face detection with RetinaNet, feature extraction with VGG-Face, and realistic face generation using the state-of-the-art BrushNet diffusion model. BrushNet utilizes the entire image, face masks, and text prompts specifying desired facial attributes like age, ethnicity, gender, and expression. This enables the generation of natural-looking images with unrecognizable individuals, facilitating the creation of privacy-compliant datasets for computer vision research.
Assessing the Use of Face Swapping Methods as Face Anonymizers in Videos
May 27, 2025The increasing demand for large-scale visual data, coupled with strict privacy regulations, has driven research into anonymization methods that hide personal identities without seriously degrading data quality. In this paper, we explore the potential of face swapping methods to preserve privacy in video data. Through extensive evaluations focusing on temporal consistency, anonymity strength, and visual fidelity, we find that face swapping techniques can produce consistent facial transitions and effectively hide identities. These results underscore the suitability of face swapping for privacy-preserving video applications and lay the groundwork for future advancements in anonymization focused face-swapping models.
A Survey on Class-Agnostic Counting: Advancements from Reference-Based to Open-World Text-Guided Approaches
Jan 31, 2025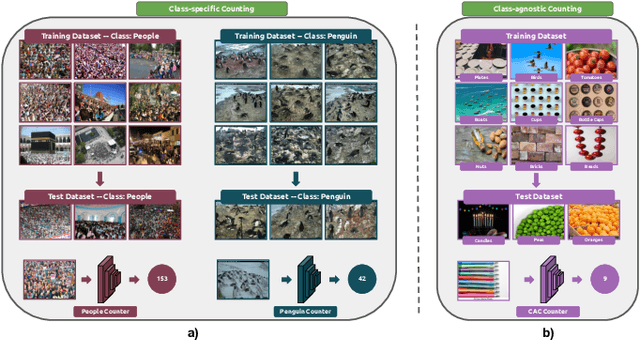

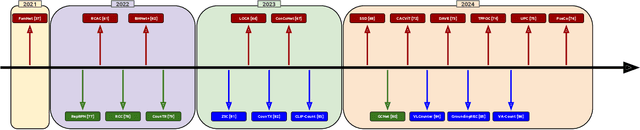

Object counting has recently shifted towards class-agnostic counting (CAC), which addresses the challenge of counting objects across arbitrary categories, tackling a critical need in versatile counting systems. While humans effortlessly identify and count objects from diverse categories without prior knowledge, most counting methods remain restricted to enumerating instances of known classes, requiring extensive labeled datasets for training, and struggling under open-vocabulary settings. Conversely, CAC aims to count objects belonging to classes never seen during training, typically operating in a few-shot setting. In this paper, for the first time, we review advancements in CAC methodologies, categorizing them into three paradigms based on how target object classes can be specified: reference-based, reference-less, and open-world text-guided. Reference-based approaches have set performance benchmarks using exemplar-guided mechanisms. Reference-less methods eliminate exemplar dependency by leveraging inherent image patterns. Finally, open-world text-guided methods utilize vision-language models, enabling object class descriptions through textual prompts, representing a flexible and appealing solution. We analyze state-of-the-art techniques and we report their results on existing gold standard benchmarks, comparing their performance and identifying and discussing their strengths and limitations. Persistent challenges -- such as annotation dependency, scalability, and generalization -- are discussed, alongside future directions. We believe this survey serves as a valuable resource for researchers to understand the progressive developments and contributions over time and the current state-of-the-art of CAC, suggesting insights for future directions and challenges to be addressed.
Impact of Face Alignment on Face Image Quality
Dec 16, 2024Face alignment is a crucial step in preparing face images for feature extraction in facial analysis tasks. For applications such as face recognition, facial expression recognition, and facial attribute classification, alignment is widely utilized during both training and inference to standardize the positions of key landmarks in the face. It is well known that the application and method of face alignment significantly affect the performance of facial analysis models. However, the impact of alignment on face image quality has not been thoroughly investigated. Current FIQA studies often assume alignment as a prerequisite but do not explicitly evaluate how alignment affects quality metrics, especially with the advent of modern deep learning-based detectors that integrate detection and landmark localization. To address this need, our study examines the impact of face alignment on face image quality scores. We conducted experiments on the LFW, IJB-B, and SCFace datasets, employing MTCNN and RetinaFace models for face detection and alignment. To evaluate face image quality, we utilized several assessment methods, including SER-FIQ, FaceQAN, DifFIQA, and SDD-FIQA. Our analysis included examining quality score distributions for the LFW and IJB-B datasets and analyzing average quality scores at varying distances in the SCFace dataset. Our findings reveal that face image quality assessment methods are sensitive to alignment. Moreover, this sensitivity increases under challenging real-life conditions, highlighting the importance of evaluating alignment's role in quality assessment.