 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo What I Say: A Spoken Prompt Dataset for Instruction-Following
Mar 10, 2026Speech Large Language Models (SLLMs) have rapidly expanded, supporting a wide range of tasks. These models are typically evaluated using text prompts, which may not reflect real-world scenarios where users interact with speech. To address this gap, we introduce DoWhatISay (DOWIS), a multilingual dataset of human-recorded spoken and written prompts designed to pair with any existing benchmark for realistic evaluation of SLLMs under spoken instruction conditions. Spanning 9 tasks and 11 languages, it provides 10 prompt variants per task-language pair, across five styles. Using DOWIS, we benchmark state-of-the-art SLLMs, analyzing the interplay between prompt modality, style, language, and task type. Results show that text prompts consistently outperform spoken prompts, particularly for low-resource and cross-lingual settings. Only for tasks with speech output, spoken prompts do close the gap, highlighting the need for speech-based prompting in SLLM evaluation.
Beyond Transcripts: A Renewed Perspective on Audio Chaptering
Feb 09, 2026Audio chaptering, the task of automatically segmenting long-form audio into coherent sections, is increasingly important for navigating podcasts, lectures, and videos. Despite its relevance, research remains limited and text-based, leaving key questions unresolved about leveraging audio information, handling ASR errors, and transcript-free evaluation. We address these gaps through three contributions: (1) a systematic comparison between text-based models with acoustic features, a novel audio-only architecture (AudioSeg) operating on learned audio representations, and multimodal LLMs; (2) empirical analysis of factors affecting performance, including transcript quality, acoustic features, duration, and speaker composition; and (3) formalized evaluation protocols contrasting transcript-dependent text-space protocols with transcript-invariant time-space protocols. Our experiments on YTSeg reveal that AudioSeg substantially outperforms text-based approaches, pauses provide the largest acoustic gains, and MLLMs remain limited by context length and weak instruction following, yet MLLMs are promising on shorter audio.
Lombard Speech Synthesis for Any Voice with Controllable Style Embeddings
Jan 19, 2026The Lombard effect plays a key role in natural communication, particularly in noisy environments or when addressing hearing-impaired listeners. We present a controllable text-to-speech (TTS) system capable of synthesizing Lombard speech for any speaker without requiring explicit Lombard data during training. Our approach leverages style embeddings learned from a large, prosodically diverse dataset and analyzes their correlation with Lombard attributes using principal component analysis (PCA). By shifting the relevant PCA components, we manipulate the style embeddings and incorporate them into our TTS model to generate speech at desired Lombard levels. Evaluations demonstrate that our method preserves naturalness and speaker identity, enhances intelligibility under noise, and provides fine-grained control over prosody, offering a robust solution for controllable Lombard TTS for any speaker.
Paragraph Segmentation Revisited: Towards a Standard Task for Structuring Speech
Dec 30, 2025Automatic speech transcripts are often delivered as unstructured word streams that impede readability and repurposing. We recast paragraph segmentation as the missing structuring step and fill three gaps at the intersection of speech processing and text segmentation. First, we establish TEDPara (human-annotated TED talks) and YTSegPara (YouTube videos with synthetic labels) as the first benchmarks for the paragraph segmentation task. The benchmarks focus on the underexplored speech domain, where paragraph segmentation has traditionally not been part of post-processing, while also contributing to the wider text segmentation field, which still lacks robust and naturalistic benchmarks. Second, we propose a constrained-decoding formulation that lets large language models insert paragraph breaks while preserving the original transcript, enabling faithful, sentence-aligned evaluation. Third, we show that a compact model (MiniSeg) attains state-of-the-art accuracy and, when extended hierarchically, jointly predicts chapters and paragraphs with minimal computational cost. Together, our resources and methods establish paragraph segmentation as a standardized, practical task in speech processing.
Shared Latent Representation for Joint Text-to-Audio-Visual Synthesis
Nov 07, 2025We propose a text-to-talking-face synthesis framework leveraging latent speech representations from HierSpeech++. A Text-to-Vec module generates Wav2Vec2 embeddings from text, which jointly condition speech and face generation. To handle distribution shifts between clean and TTS-predicted features, we adopt a two-stage training: pretraining on Wav2Vec2 embeddings and finetuning on TTS outputs. This enables tight audio-visual alignment, preserves speaker identity, and produces natural, expressive speech and synchronized facial motion without ground-truth audio at inference. Experiments show that conditioning on TTS-predicted latent features outperforms cascaded pipelines, improving both lip-sync and visual realism.
Assessing Identity Leakage in Talking Face Generation: Metrics and Evaluation Framework
Nov 05, 2025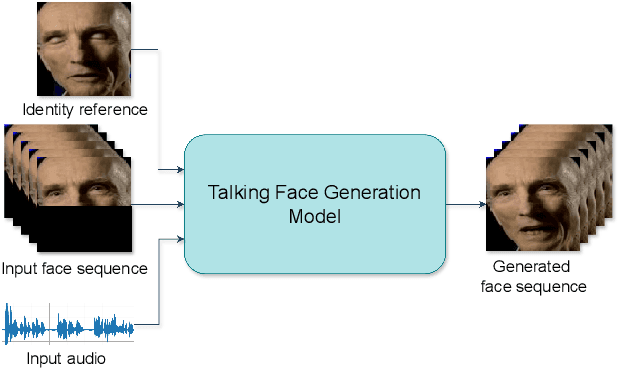


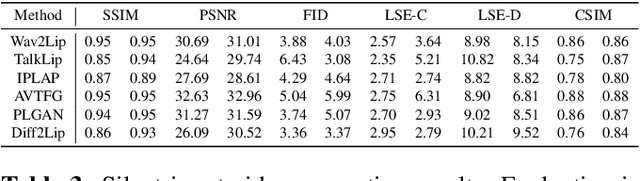
Inpainting-based talking face generation aims to preserve video details such as pose, lighting, and gestures while modifying only lip motion, often using an identity reference image to maintain speaker consistency. However, this mechanism can introduce lip leaking, where generated lips are influenced by the reference image rather than solely by the driving audio. Such leakage is difficult to detect with standard metrics and conventional test setup. To address this, we propose a systematic evaluation methodology to analyze and quantify lip leakage. Our framework employs three complementary test setups: silent-input generation, mismatched audio-video pairing, and matched audio-video synthesis. We also introduce derived metrics including lip-sync discrepancy and silent-audio-based lip-sync scores. In addition, we study how different identity reference selections affect leakage, providing insights into reference design. The proposed methodology is model-agnostic and establishes a more reliable benchmark for future research in talking face generation.
CAPE: A CLIP-Aware Pointing Ensemble of Complementary Heatmap Cues for Embodied Reference Understanding
Jul 29, 2025We address the problem of Embodied Reference Understanding, which involves predicting the object that a person in the scene is referring to through both pointing gesture and language. Accurately identifying the referent requires multimodal understanding: integrating textual instructions, visual pointing, and scene context. However, existing methods often struggle to effectively leverage visual clues for disambiguation. We also observe that, while the referent is often aligned with the head-to-fingertip line, it occasionally aligns more closely with the wrist-to-fingertip line. Therefore, relying on a single line assumption can be overly simplistic and may lead to suboptimal performance. To address this, we propose a dual-model framework, where one model learns from the head-to-fingertip direction and the other from the wrist-to-fingertip direction. We further introduce a Gaussian ray heatmap representation of these lines and use them as input to provide a strong supervisory signal that encourages the model to better attend to pointing cues. To combine the strengths of both models, we present the CLIP-Aware Pointing Ensemble module, which performs a hybrid ensemble based on CLIP features. Additionally, we propose an object center prediction head as an auxiliary task to further enhance referent localization. We validate our approach through extensive experiments and analysis on the benchmark YouRefIt dataset, achieving an improvement of approximately 4 mAP at the 0.25 IoU threshold.
Mask-Free Audio-driven Talking Face Generation for Enhanced Visual Quality and Identity Preservation
Jul 28, 2025Audio-Driven Talking Face Generation aims at generating realistic videos of talking faces, focusing on accurate audio-lip synchronization without deteriorating any identity-related visual details. Recent state-of-the-art methods are based on inpainting, meaning that the lower half of the input face is masked, and the model fills the masked region by generating lips aligned with the given audio. Hence, to preserve identity-related visual details from the lower half, these approaches additionally require an unmasked identity reference image randomly selected from the same video. However, this common masking strategy suffers from (1) information loss in the input faces, significantly affecting the networks' ability to preserve visual quality and identity details, (2) variation between identity reference and input image degrading reconstruction performance, and (3) the identity reference negatively impacting the model, causing unintended copying of elements unaligned with the audio. To address these issues, we propose a mask-free talking face generation approach while maintaining the 2D-based face editing task. Instead of masking the lower half, we transform the input images to have closed mouths, using a two-step landmark-based approach trained in an unpaired manner. Subsequently, we provide these edited but unmasked faces to a lip adaptation model alongside the audio to generate appropriate lip movements. Thus, our approach needs neither masked input images nor identity reference images. We conduct experiments on the benchmark LRS2 and HDTF datasets and perform various ablation studies to validate our contributions.
Towards Better Disentanglement in Non-Autoregressive Zero-Shot Expressive Voice Conversion
Jun 04, 2025Expressive voice conversion aims to transfer both speaker identity and expressive attributes from a target speech to a given source speech. In this work, we improve over a self-supervised, non-autoregressive framework with a conditional variational autoencoder, focusing on reducing source timbre leakage and improving linguistic-acoustic disentanglement for better style transfer. To minimize style leakage, we use multilingual discrete speech units for content representation and reinforce embeddings with augmentation-based similarity loss and mix-style layer normalization. To enhance expressivity transfer, we incorporate local F0 information via cross-attention and extract style embeddings enriched with global pitch and energy features. Experiments show our model outperforms baselines in emotion and speaker similarity, demonstrating superior style adaptation and reduced source style leakage.
KIT's Low-resource Speech Translation Systems for IWSLT2025: System Enhancement with Synthetic Data and Model Regularization
May 26, 2025This paper presents KIT's submissions to the IWSLT 2025 low-resource track. We develop both cascaded systems, consisting of Automatic Speech Recognition (ASR) and Machine Translation (MT) models, and end-to-end (E2E) Speech Translation (ST) systems for three language pairs: Bemba, North Levantine Arabic, and Tunisian Arabic into English. Building upon pre-trained models, we fine-tune our systems with different strategies to utilize resources efficiently. This study further explores system enhancement with synthetic data and model regularization. Specifically, we investigate MT-augmented ST by generating translations from ASR data using MT models. For North Levantine, which lacks parallel ST training data, a system trained solely on synthetic data slightly surpasses the cascaded system trained on real data. We also explore augmentation using text-to-speech models by generating synthetic speech from MT data, demonstrating the benefits of synthetic data in improving both ASR and ST performance for Bemba. Additionally, we apply intra-distillation to enhance model performance. Our experiments show that this approach consistently improves results across ASR, MT, and ST tasks, as well as across different pre-trained models. Finally, we apply Minimum Bayes Risk decoding to combine the cascaded and end-to-end systems, achieving an improvement of approximately 1.5 BLEU points.