 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany Ways to Be Fake: Benchmarking Fake News Detection Under Strategy-Driven AI Generation
Apr 10, 2026Recent advances in large language models (LLMs) have enabled the large-scale generation of highly fluent and deceptive news-like content. While prior work has often treated fake news detection as a binary classification problem, modern fake news increasingly arises through human-AI collaboration, where strategic inaccuracies are embedded within otherwise accurate and credible narratives. These mixed-truth cases represent a realistic and consequential threat, yet they remain underrepresented in existing benchmarks. To address this gap, we introduce MANYFAKE, a synthetic benchmark containing 6,798 fake news articles generated through multiple strategy-driven prompting pipelines that capture many ways fake news can be constructed and refined. Using this benchmark, we evaluate a range of state-of-the-art fake news detectors. Our results show that even advanced reasoning-enabled models approach saturation on fully fabricated stories, but remain brittle when falsehoods are subtle, optimized, and interwoven with accurate information.
Context Selection for Hypothesis and Statistical Evidence Extraction from Full-Text Scientific Articles
Mar 22, 2026Extracting hypotheses and their supporting statistical evidence from full-text scientific articles is central to the synthesis of empirical findings, but remains difficult due to document length and the distribution of scientific arguments across sections of the paper. The work studies a sequential full-text extraction setting, where the statement of a primary finding in an article's abstract is linked to (i) a corresponding hypothesis statement in the paper body and (ii) the statistical evidence that supports or refutes that hypothesis. This formulation induces a challenging within-document retrieval setting in which many candidate paragraphs are topically related to the finding but differ in rhetorical role, creating hard negatives for retrieval and extraction. Using a two-stage retrieve-and-extract framework, we conduct a controlled study of retrieval design choices, varying context quantity, context quality (standard Retrieval Augmented Generation, reranking, and a fine-tuned retriever paired with reranking), as well as an oracle paragraph setting to separate retrieval failures from extraction limits across four Large Language Model extractors. We find that targeted context selection consistently improves hypothesis extraction relative to full-text prompting, with gains concentrated in configurations that optimize retrieval quality and context cleanliness. In contrast, statistical evidence extraction remains substantially harder. Even with oracle paragraphs, performance remains moderate, indicating persistent extractor limitations in handling hybrid numeric-textual statements rather than retrieval failures alone.
Evaluating Evidence Grounding Under User Pressure in Instruction-Tuned Language Models
Mar 20, 2026In contested domains, instruction-tuned language models must balance user-alignment pressures against faithfulness to the in-context evidence. To evaluate this tension, we introduce a controlled epistemic-conflict framework grounded in the U.S. National Climate Assessment. We conduct fine-grained ablations over evidence composition and uncertainty cues across 19 instruction-tuned models spanning 0.27B to 32B parameters. Across neutral prompts, richer evidence generally improves evidence-consistent accuracy and ordinal scoring performance. Under user pressure, however, evidence does not reliably prevent user-aligned reversals in this controlled fixed-evidence setting. We report three primary failure modes. First, we identify a negative partial-evidence interaction, where adding epistemic nuance, specifically research gaps, is associated with increased susceptibility to sycophancy in families like Llama-3 and Gemma-3. Second, robustness scales non-monotonically: within some families, certain low-to-mid scale models are especially sensitive to adversarial user pressure. Third, models differ in distributional concentration under conflict: some instruction-tuned models maintain sharply peaked ordinal distributions under pressure, while others are substantially more dispersed; in scale-matched Qwen comparisons, reasoning-distilled variants (DeepSeek-R1-Qwen) exhibit consistently higher dispersion than their instruction-tuned counterparts. These findings suggest that, in a controlled fixed-evidence setting, providing richer in-context evidence alone offers no guarantee against user pressure without explicit training for epistemic integrity.
ReplicatorBench: Benchmarking LLM Agents for Replicability in Social and Behavioral Sciences
Feb 11, 2026The literature has witnessed an emerging interest in AI agents for automated assessment of scientific papers. Existing benchmarks focus primarily on the computational aspect of this task, testing agents' ability to reproduce or replicate research outcomes when having access to the code and data. This setting, while foundational, (1) fails to capture the inconsistent availability of new data for replication as opposed to reproduction, and (2) lacks ground-truth diversity by focusing only on reproducible papers, thereby failing to evaluate an agent's ability to identify non-replicable research. Furthermore, most benchmarks only evaluate outcomes rather than the replication process. In response, we introduce ReplicatorBench, an end-to-end benchmark, including human-verified replicable and non-replicable research claims in social and behavioral sciences for evaluating AI agents in research replication across three stages: (1) extraction and retrieval of replication data; (2) design and execution of computational experiments; and (3) interpretation of results, allowing a test of AI agents' capability to mimic the activities of human replicators in real world. To set a baseline of AI agents' capability, we develop ReplicatorAgent, an agentic framework equipped with necessary tools, like web search and iterative interaction with sandboxed environments, to accomplish tasks in ReplicatorBench. We evaluate ReplicatorAgent across four underlying large language models (LLMs), as well as different design choices of programming language and levels of code access. Our findings reveal that while current LLM agents are capable of effectively designing and executing computational experiments, they struggle with retrieving resources, such as new data, necessary to replicate a claim. All code and data are publicly available at https://github.com/CenterForOpenScience/llm-benchmarking.
KIT's Offline Speech Translation and Instruction Following Submission for IWSLT 2025
May 19, 2025



The scope of the International Workshop on Spoken Language Translation (IWSLT) has recently broadened beyond traditional Speech Translation (ST) to encompass a wider array of tasks, including Speech Question Answering and Summarization. This shift is partly driven by the growing capabilities of modern systems, particularly with the success of Large Language Models (LLMs). In this paper, we present the Karlsruhe Institute of Technology's submissions for the Offline ST and Instruction Following (IF) tracks, where we leverage LLMs to enhance performance across all tasks. For the Offline ST track, we propose a pipeline that employs multiple automatic speech recognition systems, whose outputs are fused using an LLM with document-level context. This is followed by a two-step translation process, incorporating additional refinement step to improve translation quality. For the IF track, we develop an end-to-end model that integrates a speech encoder with an LLM to perform a wide range of instruction-following tasks. We complement it with a final document-level refinement stage to further enhance output quality by using contextual information.
Quality-Aware Decoding: Unifying Quality Estimation and Decoding
Feb 12, 2025
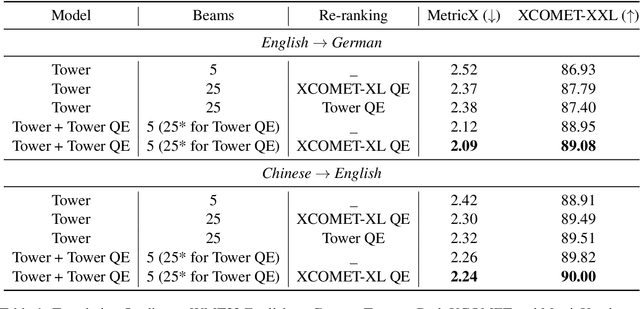
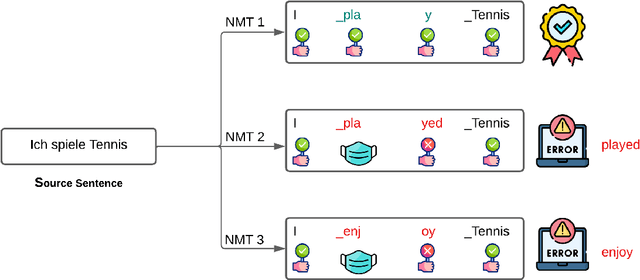
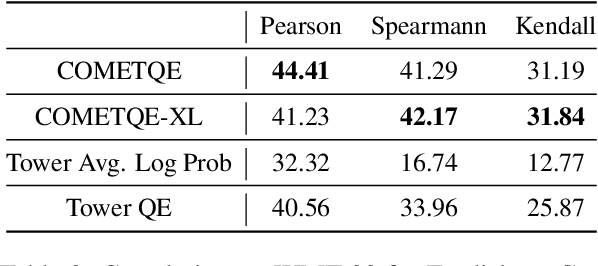
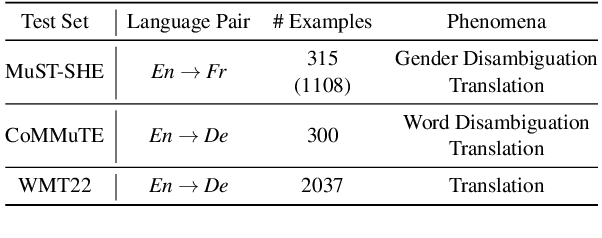
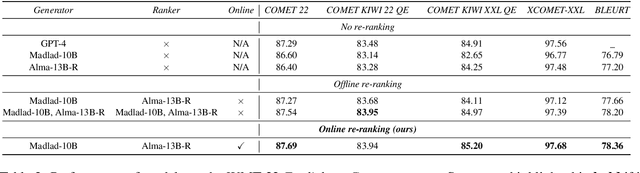
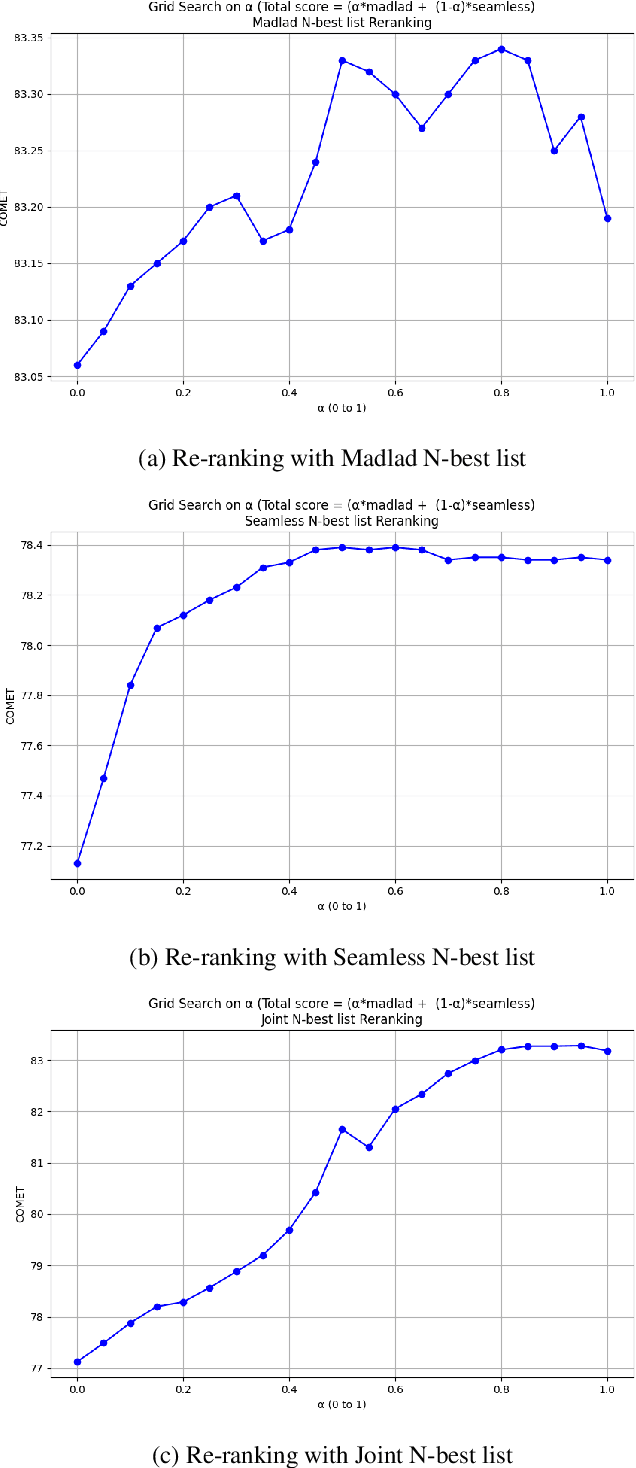
An emerging research direction in NMT involves the use of Quality Estimation (QE) models, which have demonstrated high correlations with human judgment and can enhance translations through Quality-Aware Decoding. Although several approaches have been proposed based on sampling multiple candidate translations, none have integrated these models directly into the decoding process. In this paper, we address this by proposing a novel token-level QE model capable of reliably scoring partial translations. We build a uni-directional QE model for this, as decoder models are inherently trained and efficient on partial sequences. We then present a decoding strategy that integrates the QE model for Quality-Aware decoding and demonstrate that the translation quality improves when compared to the N-best list re-ranking with state-of-the-art QE models (upto $1.39$ XCOMET-XXL $\uparrow$). Finally, we show that our approach provides significant benefits in document translation tasks, where the quality of N-best lists is typically suboptimal.
The Reopening of Pandora's Box: Analyzing the Role of LLMs in the Evolving Battle Against AI-Generated Fake News
Oct 25, 2024



With the rise of AI-generated content spewed at scale from large language models (LLMs), genuine concerns about the spread of fake news have intensified. The perceived ability of LLMs to produce convincing fake news at scale poses new challenges for both human and automated fake news detection systems. To address this gap, this work presents the findings from a university-level competition which aimed to explore how LLMs can be used by humans to create fake news, and to assess the ability of human annotators and AI models to detect it. A total of 110 participants used LLMs to create 252 unique fake news stories, and 84 annotators participated in the detection tasks. Our findings indicate that LLMs are ~68% more effective at detecting real news than humans. However, for fake news detection, the performance of LLMs and humans remains comparable (~60% accuracy). Additionally, we examine the impact of visual elements (e.g., pictures) in news on the accuracy of detecting fake news stories. Finally, we also examine various strategies used by fake news creators to enhance the credibility of their AI-generated content. This work highlights the increasing complexity of detecting AI-generated fake news, particularly in collaborative human-AI settings.
Plug, Play, and Fuse: Zero-Shot Joint Decoding via Word-Level Re-ranking Across Diverse Vocabularies
Aug 21, 2024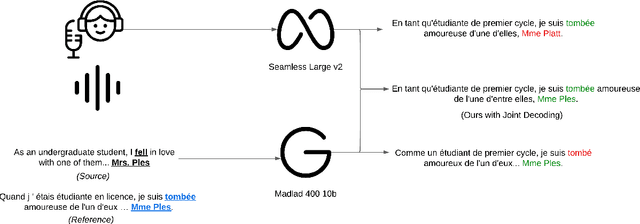
Recent advancements in NLP have resulted in models with specialized strengths, such as processing multimodal inputs or excelling in specific domains. However, real-world tasks, like multimodal translation, often require a combination of these strengths, such as handling both translation and image processing. While individual translation and vision models are powerful, they typically lack the ability to perform both tasks in a single system. Combining these models poses challenges, particularly due to differences in their vocabularies, which limit the effectiveness of traditional ensemble methods to post-generation techniques like N-best list re-ranking. In this work, we propose a novel zero-shot ensembling strategy that allows for the integration of different models during the decoding phase without the need for additional training. Our approach re-ranks beams during decoding by combining scores at the word level, using heuristics to predict when a word is completed. We demonstrate the effectiveness of this method in machine translation scenarios, showing that it enables the generation of translations that are both speech- and image-aware while also improving overall translation quality\footnote{We will release the code upon paper acceptance.}.
Blending LLMs into Cascaded Speech Translation: KIT's Offline Speech Translation System for IWSLT 2024
Jun 24, 2024Large Language Models (LLMs) are currently under exploration for various tasks, including Automatic Speech Recognition (ASR), Machine Translation (MT), and even End-to-End Speech Translation (ST). In this paper, we present KIT's offline submission in the constrained + LLM track by incorporating recently proposed techniques that can be added to any cascaded speech translation. Specifically, we integrate Mistral-7B\footnote{mistralai/Mistral-7B-Instruct-v0.1} into our system to enhance it in two ways. Firstly, we refine the ASR outputs by utilizing the N-best lists generated by our system and fine-tuning the LLM to predict the transcript accurately. Secondly, we refine the MT outputs at the document level by fine-tuning the LLM, leveraging both ASR and MT predictions to improve translation quality. We find that integrating the LLM into the ASR and MT systems results in an absolute improvement of $0.3\%$ in Word Error Rate and $0.65\%$ in COMET for tst2019 test set. In challenging test sets with overlapping speakers and background noise, we find that integrating LLM is not beneficial due to poor ASR performance. Here, we use ASR with chunked long-form decoding to improve context usage that may be unavailable when transcribing with Voice Activity Detection segmentation alone.
The Unappreciated Role of Intent in Algorithmic Moderation of Social Media Content
May 17, 2024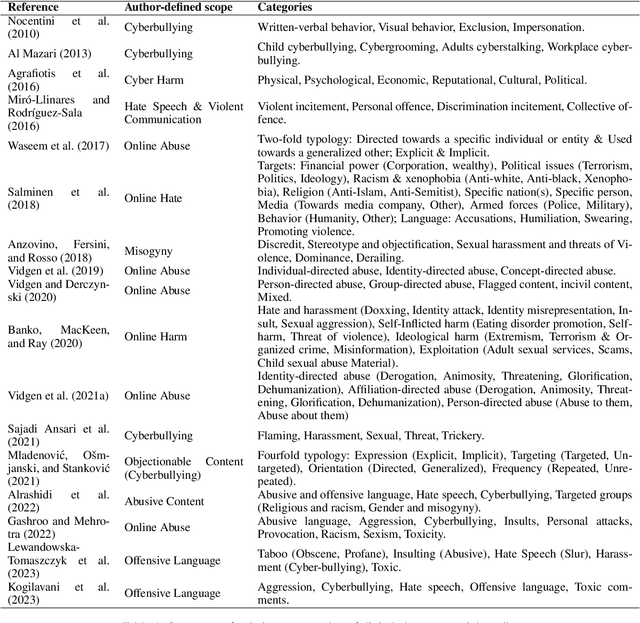
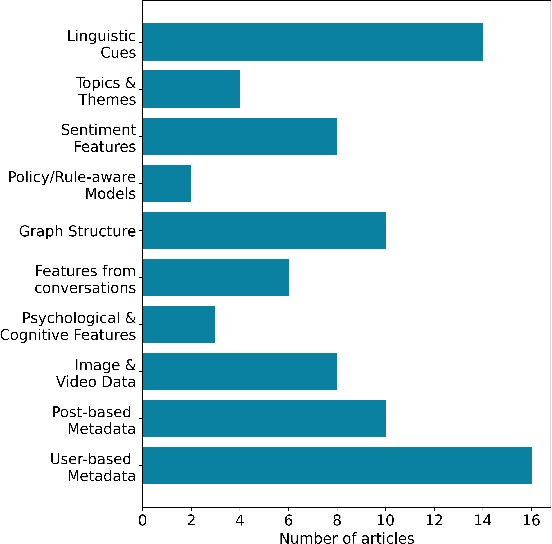
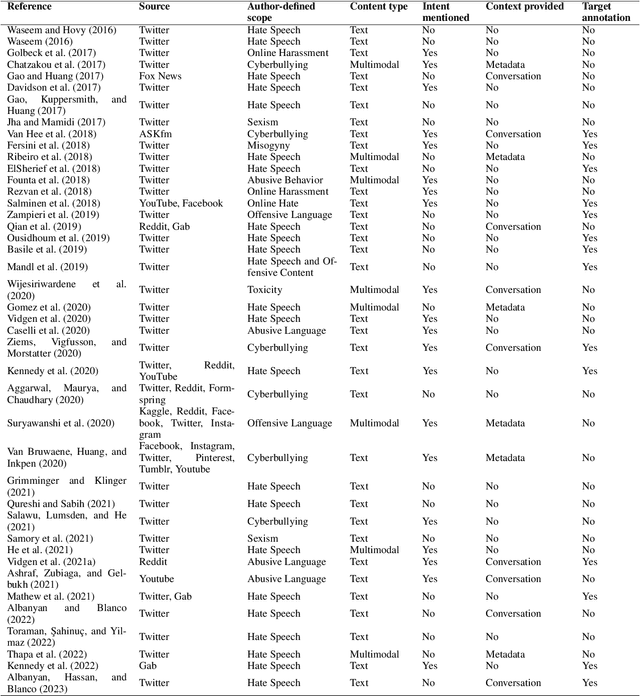
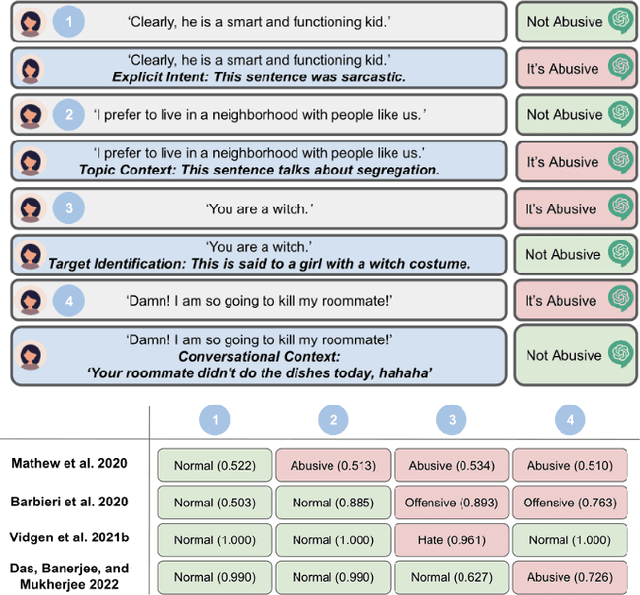
As social media has become a predominant mode of communication globally, the rise of abusive content threatens to undermine civil discourse. Recognizing the critical nature of this issue, a significant body of research has been dedicated to developing language models that can detect various types of online abuse, e.g., hate speech, cyberbullying. However, there exists a notable disconnect between platform policies, which often consider the author's intention as a criterion for content moderation, and the current capabilities of detection models, which typically lack efforts to capture intent. This paper examines the role of intent in content moderation systems. We review state of the art detection models and benchmark training datasets for online abuse to assess their awareness and ability to capture intent. We propose strategic changes to the design and development of automated detection and moderation systems to improve alignment with ethical and policy conceptualizations of abuse.