 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Refinement of Translations: Large Language Models for Sentence and Document-Level Post-Editing
Paper and Code
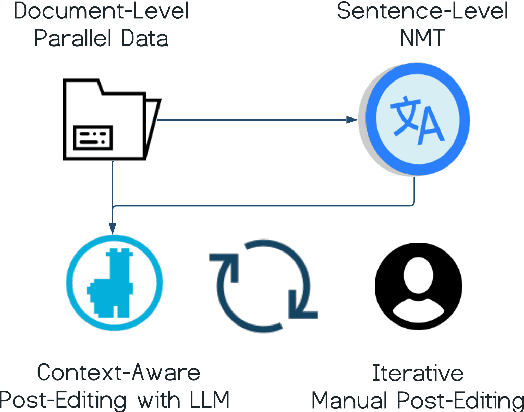



Large Language Models (LLM's) have demonstrated considerable success in various Natural Language Processing tasks, but they have yet to attain state-of-the-art performance in Neural Machine Translation (NMT). Nevertheless, their significant performance in tasks demanding a broad understanding and contextual processing shows their potential for translation. To exploit these abilities, we investigate using LLM's for MT and explore recent parameter-efficient fine-tuning techniques. Surprisingly, our initial experiments find that fine-tuning for translation purposes even led to performance degradation. To overcome this, we propose an alternative approach: adapting LLM's as Automatic Post-Editors (APE) rather than direct translators. Building on the LLM's exceptional ability to process and generate lengthy sequences, we also propose extending our approach to document-level translation. We show that leveraging Low-Rank-Adapter fine-tuning for APE can yield significant improvements across both sentence and document-level metrics while generalizing to out-of-domain data. Most notably, we achieve a state-of-the-art accuracy rate of 89\% on the ContraPro test set, which specifically assesses the model's ability to resolve pronoun ambiguities when translating from English to German. Lastly, we investigate a practical scenario involving manual post-editing for document-level translation, where reference context is made available. Here, we demonstrate that leveraging human corrections can significantly reduce the number of edits required for subsequent translations\footnote{Interactive Demo for integrating manual feedback can be found \href{https://huggingface.co/spaces/skoneru/contextual_refinement_ende}{here}}