 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models on Rare Disease Diagnosis: A Case Study using House M.D
Nov 14, 2025



Large language models (LLMs) have demonstrated capabilities across diverse domains, yet their performance on rare disease diagnosis from narrative medical cases remains underexplored. We introduce a novel dataset of 176 symptom-diagnosis pairs extracted from House M.D., a medical television series validated for teaching rare disease recognition in medical education. We evaluate four state-of-the-art LLMs such as GPT 4o mini, GPT 5 mini, Gemini 2.5 Flash, and Gemini 2.5 Pro on narrative-based diagnostic reasoning tasks. Results show significant variation in performance, ranging from 16.48% to 38.64% accuracy, with newer model generations demonstrating a 2.3 times improvement. While all models face substantial challenges with rare disease diagnosis, the observed improvement across architectures suggests promising directions for future development. Our educationally validated benchmark establishes baseline performance metrics for narrative medical reasoning and provides a publicly accessible evaluation framework for advancing AI-assisted diagnosis research.
Code-mixed LLM: Improve Large Language Models' Capability to Handle Code-Mixing through Reinforcement Learning from AI Feedback
Nov 13, 2024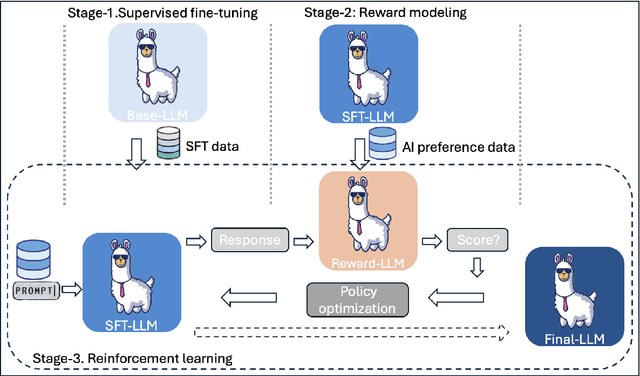

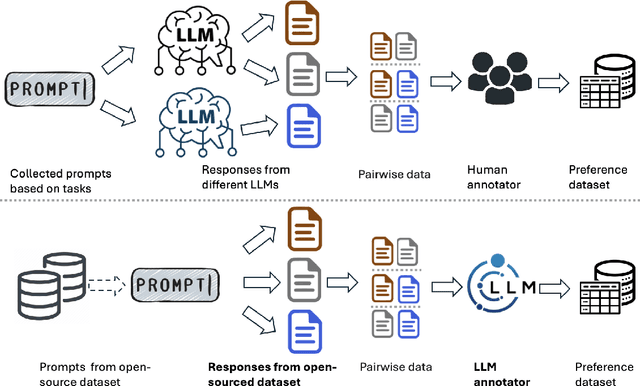
Code-mixing(CM) or code-switching(CSW) refers to the juxtaposition of linguistic units from two or more languages during the conversation or sometimes even a single utterance. Code-mixing introduces unique challenges in daily life, such as syntactic mismatches and semantic blending, that are rarely encountered in monolingual settings. Large language models (LLMs) have revolutionized the field of natural language processing (NLP) by offering unprecedented capabilities in understanding human languages. However, the effectiveness of current state-of-the-art multilingual LLMs has not yet been fully explored in the CM scenario. To fill this gap, we first benchmark the performance of multilingual LLMs on various code-mixing NLP tasks. Then we propose to improve the multilingual LLMs' ability to understand code-mixing through reinforcement learning from human feedback (RLHF) and code-mixed machine translation tasks. Given the high-cost and time-consuming preference labeling procedure, we improve this by utilizing LLMs as annotators to perform the reinforcement learning from AI feedback (RLAIF). The experiments show the effectiveness of the proposed method.
The Reopening of Pandora's Box: Analyzing the Role of LLMs in the Evolving Battle Against AI-Generated Fake News
Oct 25, 2024



With the rise of AI-generated content spewed at scale from large language models (LLMs), genuine concerns about the spread of fake news have intensified. The perceived ability of LLMs to produce convincing fake news at scale poses new challenges for both human and automated fake news detection systems. To address this gap, this work presents the findings from a university-level competition which aimed to explore how LLMs can be used by humans to create fake news, and to assess the ability of human annotators and AI models to detect it. A total of 110 participants used LLMs to create 252 unique fake news stories, and 84 annotators participated in the detection tasks. Our findings indicate that LLMs are ~68% more effective at detecting real news than humans. However, for fake news detection, the performance of LLMs and humans remains comparable (~60% accuracy). Additionally, we examine the impact of visual elements (e.g., pictures) in news on the accuracy of detecting fake news stories. Finally, we also examine various strategies used by fake news creators to enhance the credibility of their AI-generated content. This work highlights the increasing complexity of detecting AI-generated fake news, particularly in collaborative human-AI settings.
Hey GPT, Can You be More Racist? Analysis from Crowdsourced Attempts to Elicit Biased Content from Generative AI
Oct 20, 2024

The widespread adoption of large language models (LLMs) and generative AI (GenAI) tools across diverse applications has amplified the importance of addressing societal biases inherent within these technologies. While the NLP community has extensively studied LLM bias, research investigating how non-expert users perceive and interact with biases from these systems remains limited. As these technologies become increasingly prevalent, understanding this question is crucial to inform model developers in their efforts to mitigate bias. To address this gap, this work presents the findings from a university-level competition, which challenged participants to design prompts for eliciting biased outputs from GenAI tools. We quantitatively and qualitatively analyze the competition submissions and identify a diverse set of biases in GenAI and strategies employed by participants to induce bias in GenAI. Our finding provides unique insights into how non-expert users perceive and interact with biases from GenAI tools.
Watermarking Counterfactual Explanations
May 29, 2024The field of Explainable Artificial Intelligence (XAI) focuses on techniques for providing explanations to end-users about the decision-making processes that underlie modern-day machine learning (ML) models. Within the vast universe of XAI techniques, counterfactual (CF) explanations are often preferred by end-users as they help explain the predictions of ML models by providing an easy-to-understand & actionable recourse (or contrastive) case to individual end-users who are adversely impacted by predicted outcomes. However, recent studies have shown significant security concerns with using CF explanations in real-world applications; in particular, malicious adversaries can exploit CF explanations to perform query-efficient model extraction attacks on proprietary ML models. In this paper, we propose a model-agnostic watermarking framework (for adding watermarks to CF explanations) that can be leveraged to detect unauthorized model extraction attacks (which rely on the watermarked CF explanations). Our novel framework solves a bi-level optimization problem to embed an indistinguishable watermark into the generated CF explanation such that any future model extraction attacks that rely on these watermarked CF explanations can be detected using a null hypothesis significance testing (NHST) scheme, while ensuring that these embedded watermarks do not compromise the quality of the generated CF explanations. We evaluate this framework's performance across a diverse set of real-world datasets, CF explanation methods, and model extraction techniques, and show that our watermarking detection system can be used to accurately identify extracted ML models that are trained using the watermarked CF explanations. Our work paves the way for the secure adoption of CF explanations in real-world applications.
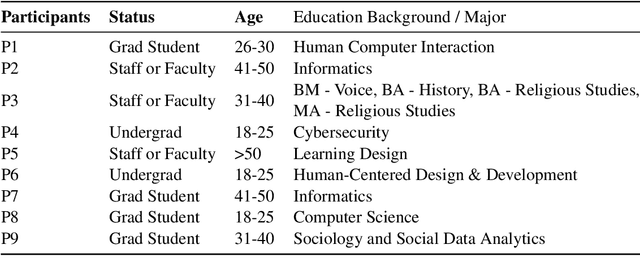
A Taxonomy of Rater Disagreements: Surveying Challenges & Opportunities from the Perspective of Annotating Online Toxicity
Nov 07, 2023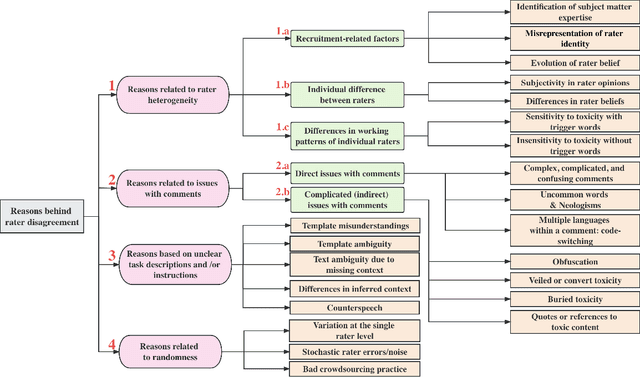
Toxicity is an increasingly common and severe issue in online spaces. Consequently, a rich line of machine learning research over the past decade has focused on computationally detecting and mitigating online toxicity. These efforts crucially rely on human-annotated datasets that identify toxic content of various kinds in social media texts. However, such annotations historically yield low inter-rater agreement, which was often dealt with by taking the majority vote or other such approaches to arrive at a single ground truth label. Recent research has pointed out the importance of accounting for the subjective nature of this task when building and utilizing these datasets, and this has triggered work on analyzing and better understanding rater disagreements, and how they could be effectively incorporated into the machine learning developmental pipeline. While these efforts are filling an important gap, there is a lack of a broader framework about the root causes of rater disagreement, and therefore, we situate this work within that broader landscape. In this survey paper, we analyze a broad set of literature on the reasons behind rater disagreements focusing on online toxicity, and propose a detailed taxonomy for the same. Further, we summarize and discuss the potential solutions targeting each reason for disagreement. We also discuss several open issues, which could promote the future development of online toxicity research.
RoCourseNet: Distributionally Robust Training of a Prediction Aware Recourse Model
Jun 01, 2022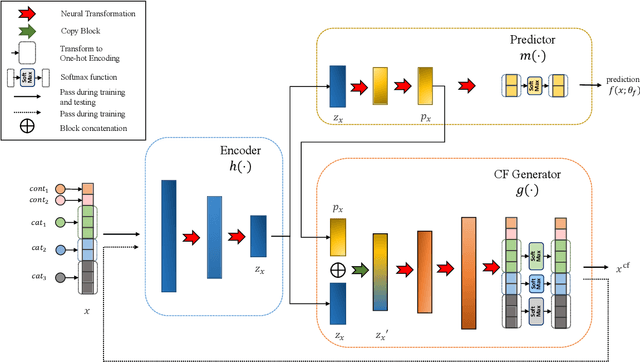
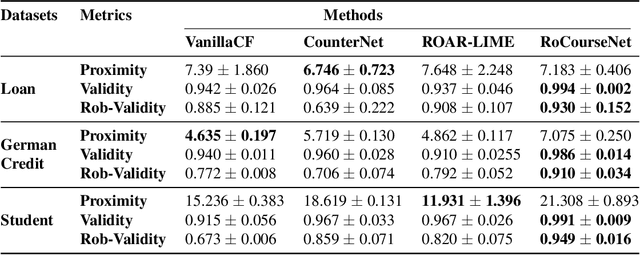
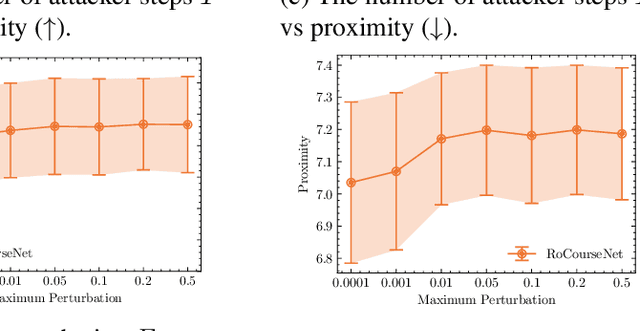
Counterfactual (CF) explanations for machine learning (ML) models are preferred by end-users, as they explain the predictions of ML models by providing a recourse case to individuals who are adversely impacted by predicted outcomes. Existing CF explanation methods generate recourses under the assumption that the underlying target ML model remains stationary over time. However, due to commonly occurring distributional shifts in training data, ML models constantly get updated in practice, which might render previously generated recourses invalid and diminish end-users trust in our algorithmic framework. To address this problem, we propose RoCourseNet, a training framework that jointly optimizes for predictions and robust recourses to future data shifts. We have three main contributions: (i) We propose a novel virtual data shift (VDS) algorithm to find worst-case shifted ML models by explicitly considering the worst-case data shift in the training dataset. (ii) We leverage adversarial training to solve a novel tri-level optimization problem inside RoCourseNet, which simultaneously generates predictions and corresponding robust recourses. (iii) Finally, we evaluate RoCourseNet's performance on three real-world datasets and show that RoCourseNet outperforms state-of-the-art baselines by 10% in generating robust CF explanations.
CounterNet: End-to-End Training of Counterfactual Aware Predictions
Sep 15, 2021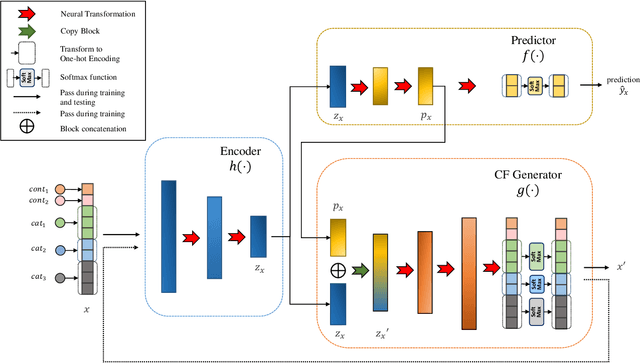
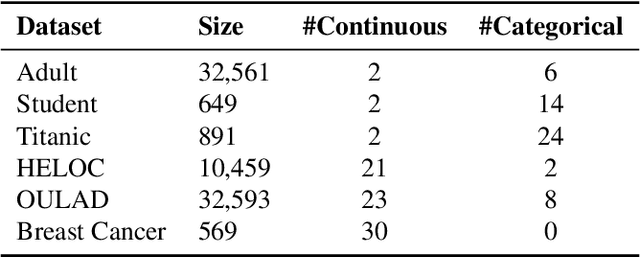
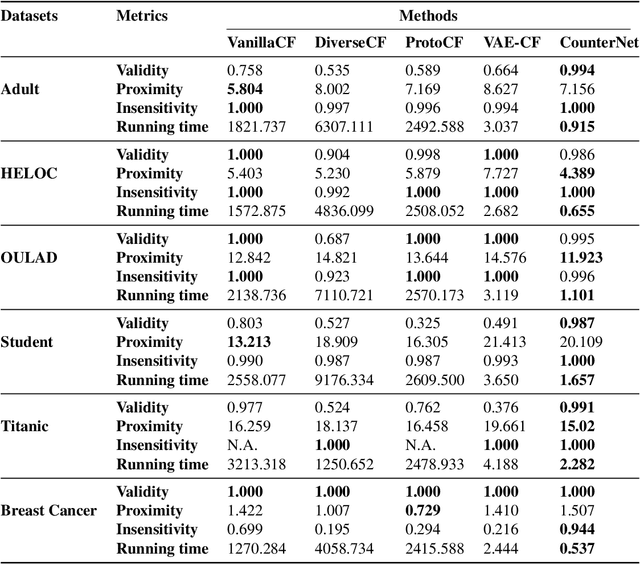
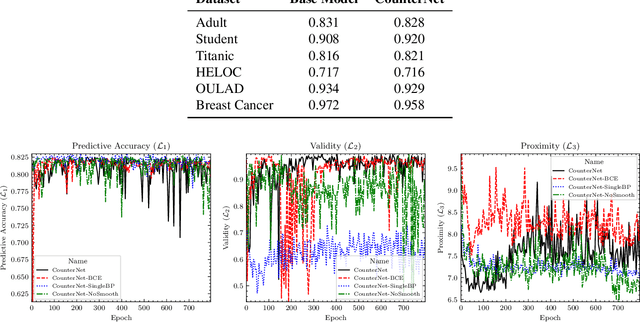
This work presents CounterNet, a novel end-to-end learning framework which integrates the predictive model training and counterfactual (CF) explanation generation into a single end-to-end pipeline. Counterfactual explanations attempt to find the smallest modification to the feature values of an instance that changes the prediction of the ML model to a predefined output. Prior CF explanation techniques rely on solving separate time-intensive optimization problems for every single input instance to find CF examples, and also suffer from the misalignment of objectives between model predictions and explanations, which leads to significant shortcomings in the quality of CF explanations. CounterNet, on the other hand, integrates both prediction and explanation in the same framework, which enables the optimization of the CF example generation only once together with the predictive model. We propose a novel variant of back-propagation which can help in effectively training CounterNet's network. Finally, we conduct extensive experiments on multiple real-world datasets. Our results show that CounterNet generates high-quality predictions, and corresponding CF examples (with high validity) for any new input instance significantly faster than existing state-of-the-art baselines.
Influence Maximization for Social Good: Use of Social Networks in Low Resource Communities
Dec 03, 2019

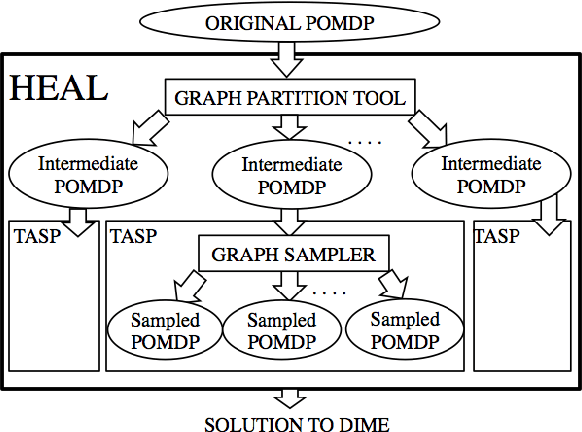

This thesis proposal makes the following technical contributions: (i) we provide a definition of the Dynamic Influence Maximization Under Uncertainty (or DIME) problem, which models the problem faced by homeless shelters accurately; (ii) we propose a novel Partially Observable Markov Decision Process (POMDP) model for solving the DIME problem; (iii) we design two scalable POMDP algorithms (PSINET and HEALER) for solving the DIME problem, since conventional POMDP solvers fail to scale up to sizes of interest; and (iv) we test our algorithms effectiveness in the real world by conducting a pilot study with actual homeless youth in Los Angeles. The success of this pilot (as explained later) shows the promise of using influence maximization for social good on a larger scale.
Artificial Intelligence for Low-Resource Communities: Influence Maximization in an Uncertain World
Dec 03, 2019



The potential of Artificial Intelligence (AI) to tackle challenging problems that afflict society is enormous, particularly in the areas of healthcare, conservation and public safety and security. Many problems in these domains involve harnessing social networks of under-served communities to enable positive change, e.g., using social networks of homeless youth to raise awareness about Human Immunodeficiency Virus (HIV) and other STDs. Unfortunately, most of these real-world problems are characterized by uncertainties about social network structure and influence models, and previous research in AI fails to sufficiently address these uncertainties. This thesis addresses these shortcomings by advancing the state-of-the-art to a new generation of algorithms for interventions in social networks. In particular, this thesis describes the design and development of new influence maximization algorithms which can handle various uncertainties that commonly exist in real-world social networks. These algorithms utilize techniques from sequential planning problems and social network theory to develop new kinds of AI algorithms. Further, this thesis also demonstrates the real-world impact of these algorithms by describing their deployment in three pilot studies to spread awareness about HIV among actual homeless youth in Los Angeles. This represents one of the first-ever deployments of computer science based influence maximization algorithms in this domain. Our results show that our AI algorithms improved upon the state-of-the-art by 160% in the real-world. We discuss research and implementation challenges faced in deploying these algorithms, and lessons that can be gleaned for future deployment of such algorithms. The positive results from these deployments illustrate the enormous potential of AI in addressing societally relevant problems.